清华大学刘知远:知识指导的自然语言处理( 二 )
 文章插图
文章插图
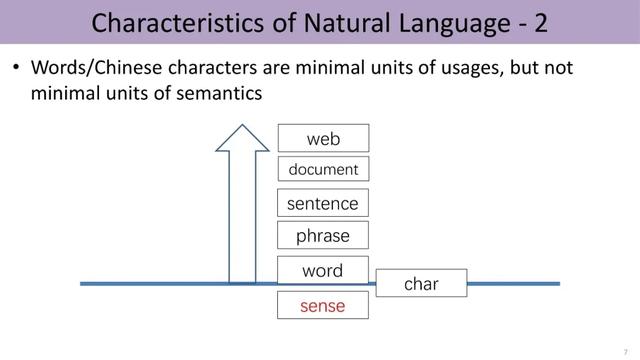
这就涉及语言的另一个特点:一词多义现象 。 日常交流中 , 我们把词或汉字视为最小的使用单位 。 然而 , 这些并非最小的语义单元 , 词的背后还会有更细粒度的词义层次 , 比如“苹果”这个词至少有水果、公司产品这两种解释 。 那么词义(sense)是最小单元么?可能也不是 。
 文章插图
文章插图
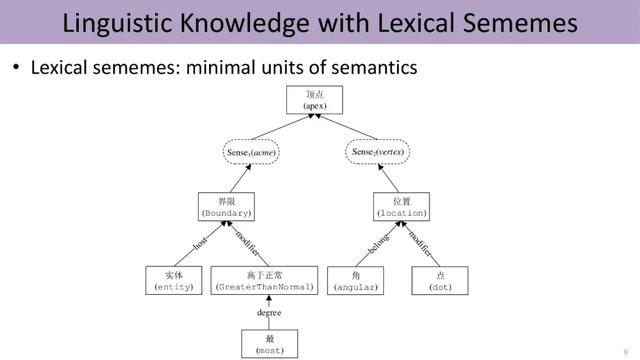
语义最小单元:义原
语言学家指出可以对词义进行无限细分 , 找到一套语义“原子”来描述语言中的所有概念 。 这套原子称为义原(sememes) , 即语义的最小单元 。 例如 , “顶点”这个词可能有两个词义 , 每个词义用细粒度更小的义原来表示 。 如图 , 左边的词义是指某物的最高点 , 由四个义原的组合进行表示 。
 文章插图
文章插图
在人工标注义原方面 , 语言学家董振东先生辛劳数十年 , 手工标注了一个知识库HowNet , 发布于1999年 。 经过几轮迭代 , 现囊括约2000个不同的义原 , 并利用这些义原标注了中英文各十几万个单词的词义 。
 文章插图
文章插图
然而深度学习时代 , 以word2vec为代表的大规模数据驱动的方法成为主流 , 传统语言学家标注的大规模知识库逐渐被推向历史的墙角 , HowNet、WordNet等知识库的引用明显下跌 。
那么 , 数据驱动是最终的AI解决方案么?
直觉上并非如此 。 数据只是外在信息、是人类智慧的产物 , 却无法反映人类智能的深层结构 , 尤其是高层认知 。 我们能否教会计算机语言知识呢?
HowNet与Word2Vec的融合
2017年 , 刘知远等人尝试将HowNet融入当时深度学习自然语言处理中一个里程碑式的工作Word2Vec , 取得了振奋人心的实验效果 。
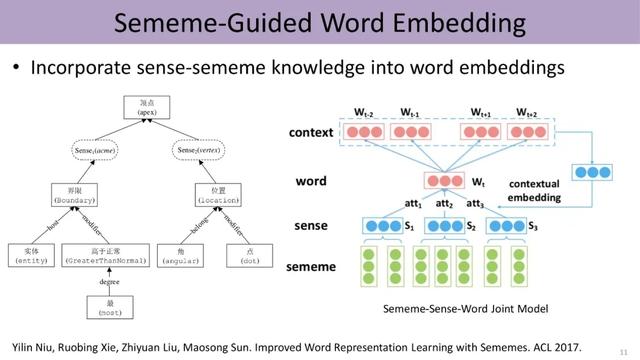
下图展示了义原指导的word embedding , 该模型根据上下文来计算同一词语不同义原的注意力、得到不同词义的权重 , 从而进行消歧 , 进一步利用上下文学习该词义的表示 。 尽管利用了传统Word2Vec中skip-gram的方法 , 即由中心词Wt预测滑动窗口里上下文的词 , 然而中心词的embedding由标注好的义原的embedding组合而成 。 因此 , 这项研究将HowNet中word、sense和sememe三层结构融入word embedding中 , 综合利用了知识库和数据两方面的信息 。
 文章插图
文章插图
实验结果证明 , 融入HowNet的知识可以显著提升模型效果 , 尤其是涉及认知推理、类比推理等成分的任务 。 并且 , 我们能自动发现文本中带有歧义的词在具体语境下隶属于哪一个词义 。 不同于过去有监督或半监督的方法 , 该模型并未直接标注这些词所对应的词义 , 而是利用HowNet知识库来完成 。 由此可见 , 知识库对于文本理解能够提供一些有意义的信息 。
 文章插图
文章插图
受到这项工作的鼓舞 , 刘知远的团队将知识的运用从词语层面扩展到句子级别 。 过去深度学习是直接利用上文的语义预测下一个词 , 现在把word、sense和sememe的三层结构嵌入预测过程中 。 首先由上文预测下一个词对应的义原 , 然后由这些义原激活对应的sense , 进而由sense激活对应的词 。 一方面 , 该方法引入知识 , 利用更少的数据训练相对更好的语言模型;另一方面 , 形成的语言模型具有更高的可解释性 , 能够清楚地表明哪些义原导致了最终的预测结果 。
- 华为云知识计算解决方案获首批“知识图谱产品认证证书”
- 企业|技术快速迭代倒逼知识产权“贴身”服务,上海首家AI商标品牌指导站入驻徐汇西岸
- 手机卡顿时,究竟是关机还是重启,这四点差异明显,看完涨知识了
- 原来微信长按2秒这么实用!能开启5个高级功能,涨知识了
- 你不知道的6个微信隐藏功能,个个超实用,学到就是涨知识
- iPhone自带的录音转文字功能,堪称会议记录神器,涨知识了
- 清华大学研究院出手!擦一次,持续24小时防雾,改变眼镜党体验
- 手机定位很简单,打开手机设置,立刻知道对方去过哪里,涨知识了
- 才发现微信隐藏的6个功能,各个都很实用,涨知识了
- 视频|好看视频宣布品牌升级:定位视频知识图谱