为什么微信推荐这么快?( 四 )
4. 近实时增量更新的挑战 - 十秒内完成索引的更新
- 数据一致性与持久化
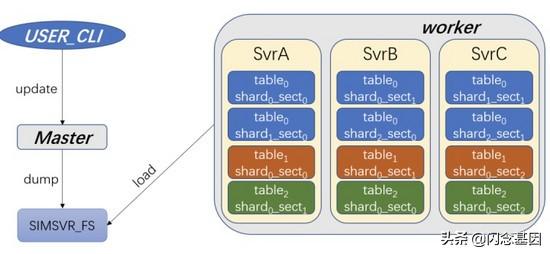
- 对于大多数的分布式存储组件来说 , 都是使用 raft 或者 paxos 等一致性协议保证数据一致性并持久化至本机上;
- 对于 SimSvr 来说 , 每张表会被分为多个 sharding , 且 sharding 数不保证为奇数;
- 在 worker 中加入一致性组件及额外的存储引擎 , 会使得整体的结构变得复杂;
- 最终在考量后 , 结合业务的批量增量更新的特点 , 选择了先将数据落地 fs , 再由 worker 拉取数据加载的方案;在这种方案下 , 1000 以内数量的 key 插入 , 能够在 10s 内完成 , 达到了业务的要求 。
 文章插图
文章插图增量持久化
- 增量更新的性能保障
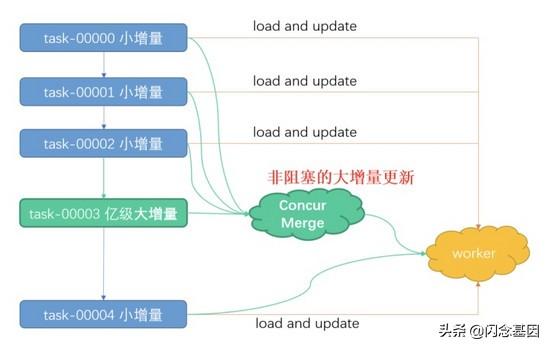
- 由于在线建索引是非常消耗 cpu 资源的过程 , 因此为了不影响现网的读服务 , worker 仅提供少量的 cpu 资源用于增量数据的更新;
- 对于小批量的增量数据 , worker 可以直接加载存放在 fs 上的数据并直接进行索引的在线插入;
- 对于大批量的增量数据 , 为了避免影响读服务及大增量更新慢的问题 , SimSvr 将大批量数据在 trainer 进行合并且并发重建索引 , 最后再由 worker 直接加载建好的索引 。
 文章插图
文章插图增量更新
5. 丰富的功能特性
5.1 支持额外的特征存储库
- 在推荐系统中 , 同一个模型 , 产生的数据除了用于检索的索引库 , 常常还有视频特征/用户画像的特征数据;
- 这类数据 , 仅仅只需要查询的功能 , 并且与同个模型同个版本产出的索引库相互作用 , 产生正确的召回效果;
- 基于这种原子性更新的特性 , SimSvr 支持了额外的特征存储库 , 用于存储与模型一同更新且仅用于查询的特征数据 , 帮助业务省去了数据同步与对齐的烦恼 。
- 在推荐系统中 , ABTest 是非常常见的 , 多个模型的实验往往也是需要同时进行的;
- 另外 , 在某些场景下 , 同一个模型会产生不同的索引数据 , 在线上使用时要求同模型的索引要同时生效;
- 对于以上两种情况 , 如果使用多表支持多模型 , 在索引更新上存在生效时间的差异从而无法支持;
- SimSvr 对于这种情况 , 支持了同一张表多份索引的原子性更新 , 保证了索引能够同时生效 。
- 在 ABTest 场景下 , 除了有多模型间的实验 , 还有相同模型不同版本数据的实验;
- 在相同模型中 , 版本迭代/不同版本进行实验的场景是广泛存在的;
- 如果使用多表支持这样的多版本索引 , 不管在业务方的使用上 , 还是在 SimSvr 的管理上 , 都显得不是那么地优雅;
- 对此 , SimSvr 支持了同一张表的多版本管理 , 并且多版本支持在现网下同时进行服务 , 业务可以按需请求目标版本 , 进行灵活的实验 。
- 在视频号场景中 , 业务使用 SimSvr 对视频进行索引;
- 在使用某个用户的特征进行召回时 , 常常召回了许多用户已看过的视频 , 影响用户体验;
- 通过增加召回结果并在结果中进行过滤 , 对于重度用户 , 一样存在上述问题 , 并且还会导致不必要的性能开销;
- SimSvr 改造 hnswlib , 嵌入了过滤器的逻辑 , 使得其支持在检索过程中实时对符合特定条件的 key 进行过滤 , 保证了召回结果的有效性 。
- 对于一些推荐系统来说 , 对于数据的时效性要求是非常高的 , 在数据过了其最佳召回时间段之后 , 就不应该出现在召回结果中 , 以免出现不合时宜的尴尬;
- 微信还能这么用?让你大开眼界的微信隐藏操作
- 微软调侃WhatsApp隐私策略调整 并推荐用户迁移至Skype
- 短短几个月,安装包从200M涨到354M,微信越来越臃肿了?
- 国家发布“铁令”,微信、支付宝始料未及,必须作出整改
- iOS版微信又双更新了,AirPods Pro推出牛年限定款
- 飞书文档微信小程序审核被卡?字节跳动副总裁谢欣:希望腾讯停止无理由封杀
- 这次玩儿得有点大!美宣布决定!微信、苹果二选一事件“重现”?
- 拜拜扫描仪!微信打开这个功能,文档表格扫一扫秒变电子档
- 微信又迎来更新!你们想要的功能终于来了
- 特朗普还在挣扎?禁支付宝、微信支付等8款中国应用