Facebook开源人工智能模型RAG:可检索文档以回答问题( 二 )
消除研究中的训练开销如果人工智能助手要在日常生活中扮演更有用的角色 , 它们不仅需要能够访问大量的信息 , 更重要的是 , 能够访问正确的信息 。 考虑到世界的发展速度 , 事实证明 , 这对于预训练的模型具有挑战性 , 即使是很小的变化 , 也需要不断的计算密集型再训练 。 RAG 允许自然语言处理模型绕过再训练步骤 , 访问并提取最新的信息 , 然后使用最先进的 seq2seq 生成器输出结果 。 这种融合应该会使未来的自然语言处理模型更具适应性 , 而且我们确实已经从 Facebook 的人工智能相关研究项目 Fusion-in-Decoder 中看到了成果 。
我们认为 RAG 具有广阔的潜力 , 这就是我们今天发布它作为 Hugging Face Transformer 库的一个组件的原因 。 Hugging Face 的 Transformer 已经成为开源自然语言处理中事实上的标准 , 这要归功于它较低的进入门槛和对最新模型的覆盖 , 并且它与新的 Datasets 库集成 , 以提供 RAG 所依赖的索引知识源 。 现在 , 随着 RAG 的加入 , 我们相信社区将能够基于检索的生成应用于我们已经探索过的知识密集型任务和一些我们甚至还没有想到的任务 。
 文章插图
文章插图
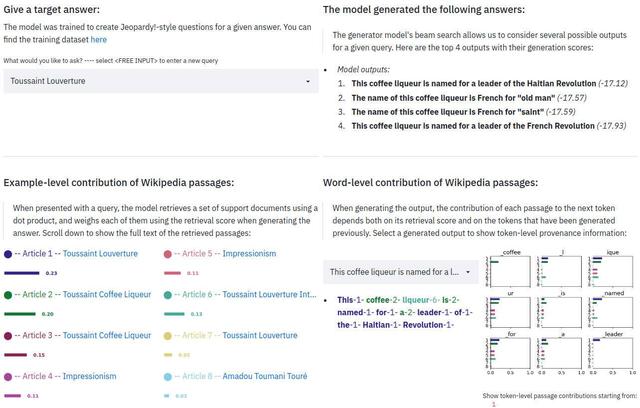 文章插图
文章插图
RAG 解放了研究人员和工程师 , 使他们能够快速开发和部署解决方案 , 以完成自己的知识密集型任务 , 而这些任务只需五行代码即可完成 。 我们可以预见未来对知识密集型任务的研究潜力 , 这些任务就像今天的情绪分析这样的轻量级知识任务一样简单易懂 。
作者介绍:
Sebastian Riedel , 研究主管;Douwe Kiela , 研究科学家;Patrick Lewis , FAIR 博士生;Aleksandra Piktus , 软件工程师 。
原文链接:
【Facebook开源人工智能模型RAG:可检索文档以回答问题】
延伸阅读:
K8s和YARN都不够好 , 全面解析Facebook自研流处理服务管理平台-InfoQ
关注我并转发此篇文章 , 私信我“领取资料” , 即可免费获得InfoQ价值4999元迷你书 , 点击文末「了解更多」 , 即可移步InfoQ官网 , 获取最新资讯~
- Facebook向客户发邮件:对苹果隐私新规“别无选择”
- 人工智能|麻辣财经:我国“算力”增长迅速,有力支撑人工智能发展
- 人工智能有助于文学照亮人性
- 人工智能改变生活 智能验脚让穿鞋更科学
- Facebook智能眼镜有望2021年上市 AR叠加体验或缺席
- 在Galaxy Buds Pro正式发布前 有人已开始在Facebook上出售这款产品
- Flipper Zero将于下月发货:为极客打造的开源多功能小工具
- Lip Factory利用人工智能现场为顾客创建定制口红
- 不再是特例:Facebook将在平台上禁掉乔治亚州的政治广告
- Facebook Messenger收集的数据量有多吓人?可视化对比图告诉你