浅谈Linux内核源码分析方法( 五 )
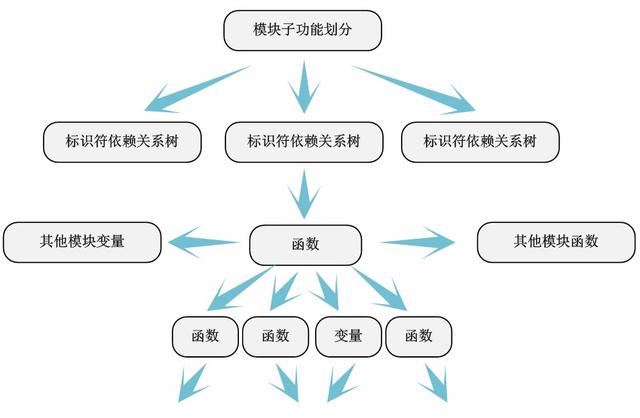
通过第四步对代码模块的划分 , 我们就可以很“轻松”地逐个对模块进行分析 。 一般的 , 我们可以从文件底部的模块出入口函数开始(“module_init”和“module_exit”声明的函数 , 一般都在文件最后) , 根据它们调用的函数(自己定义的或者其他模块的函数)和使用的关键变量(本文件内的全局变量或者其他模块的外部变量)画出“函数-变量-函数”依赖关系图——我们称为标识符依赖关系图 。
当然 , 模块内标识符依赖关系并非是单纯的树形结构 , 很多情况是错综复杂的网络关系 。 这时候 , 我们对代码的详细注释的作用就体现出来了 。 我们根据函数本身的含义 , 将模块进行子功能划分 , 抽取出每个子功能的标识符依赖树 。
 文章插图
文章插图
通过标识符依赖关系分析 , 可以很清晰的展示模块定义的函数调用了那些函数 , 使用了哪些变量 , 以及模块子功能之间的依赖关系——公用了哪些函数和变量等 。
第六步:模块间相互依赖关系
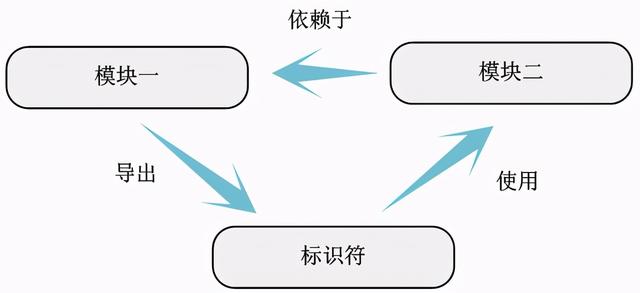
一旦将所有的模块内部标识符依赖关系图整理完毕 , 根据模块使用的其他模块的变量或函数 , 可以很容易得到模块之间的依赖关系 。
 文章插图
文章插图
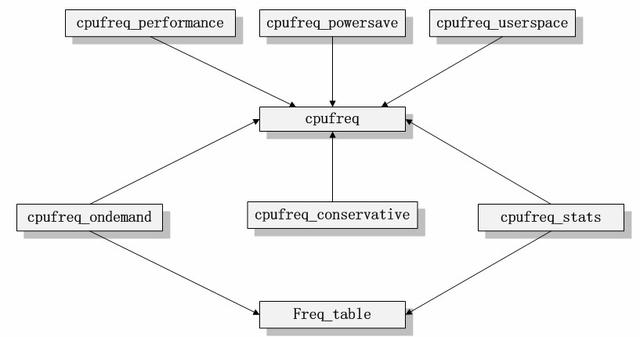
cpufreq代码的模块依赖关系可以表示为如下关系 。
 文章插图
文章插图
第七步:模块架构图
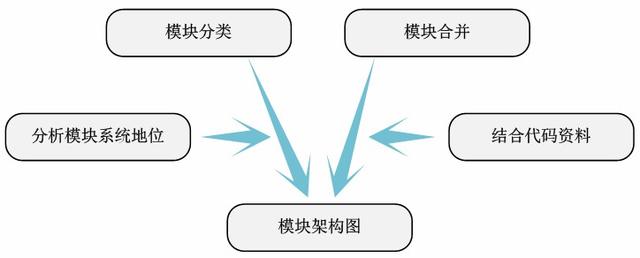
透过模块间的依赖关系图 , 可以很清楚的表达模块在整个待分析代码中的地位和功能 。 基于此 , 我们可以将模块分类 , 整理出代码的架构关系 。
 文章插图
文章插图
如cpufreq的模块依赖关系图所示 , 我们可以很清楚的看到所有的调频策略模块都是依赖于核心模块cpufreq、cpufreq_stats和freq_table的 。 如果我们把被依赖的三个模块抽象为代码的核心框架的话 , 这些调频策略模块都是建立在这个框架之上的 , 它们负责和用户层交互 。 而核心模块cpufreq提供了驱动等相关的接口负责与系统底层交互 。 因此 , 我们可以得到如下的模块架构图 。
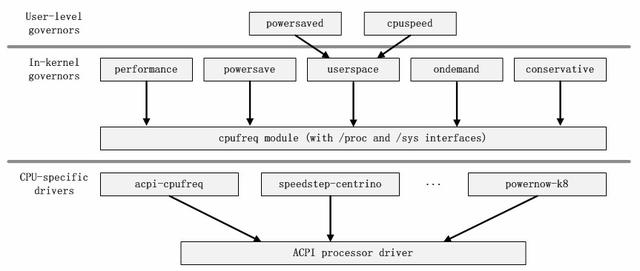 文章插图
文章插图
当然 , 架构图并非模块的无机拼接 , 我们还需要结合查阅的资料去丰富架构图的含义 。 因此 , 这里的架构图的细节会随着不同的人的理解有所偏差 。 但是架构图主体的含义很基本一致的 。 至此 , 我们完成了待分析的内核代码的所有分析工作 。
四、总结
正如文章开始所说 , 我们不可能对全部的内核代码进行分析 。 因此 , 通过对待分析的代码进行信息搜集 , 然后按照上述的流程分析出代码的原本始末是了解内核本质的有效手段 。 这种按照具体需要分析内核代码的方式 , 为快速进入Linux内核的世界提供了可能 。 通过这种方式 , 不断的对内核的其他模块分析 , 最后综合得到自己对Linux内核的理解 , 也就达到了我们学习Linux内核的目的 。
【浅谈Linux内核源码分析方法】最后向大家推荐两本学习内核的参考书 。 一本是《Linux内核的设计与实现》 , 该书为读者快速精简的介绍了Linux内核的主要功能和实现 。 但不会把读者带入Linux内核代码的深渊中 , 是了解内核架构和入门Linux内核代码的非常好的参考书 , 同时该书会提高读者对内核代码的兴趣 。 另一本是《深入理解
- AMD Zen3 APU内核图提前偷跑:三级缓存质变
- 苹果M1、A14内核设计对比:差别很大
- Linux Kernel 5.10.5发布:禁用FBCON加速滚动特性
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- Fedora正在寻求协助 希望加快Linux 5.10 LTS内核测试进度
- Linux Mint 20.1 Ulyssa稳定版已确定延期至2021年初发布
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- MIPS架构厂商日渐式微 Linux报告其漏洞遭遇困难
- 苹果M1、A14内核设计对比:迥然不同
- Linux Kernel 5.11首个候选版本更新发布