浅谈Linux内核源码分析方法( 三 )
这里举一个简单的例子 , 假定我们要分析Linux的变频机制实现的代码 。 目前为止我们仅仅是知道这个名词而已 , 透过字面含义我们可以大致猜测它应该和CPU的频率调节相关 。 通过信息搜集 , 我们应该能得到如下的相关的信息:
1.CPUFreq机制 。
2.performance、powersave、userspace、ondemand、conservative调频策略 。
3./driver/cpufreq/ 。
4./documention/cpufreq 。
5.P state和C state 。
……
分析Linux内核代码如果能搜集到这些信息 , 应该说是非常“幸运”了 。 毕竟有关Linux内核的资料确实不如.NET和JQuery那么丰富 , 不过这相比于十数年前 , 没有强大的搜索引擎 , 没有相关的研究资料的时期应该称得上是“大丰收”时代了!我们通过简单的“搜索”(可能会花费一到两天的时间吧) , 甚至找到了这部分代码所在的源码文件目录 , 不得不说这样的信息简直是“价值连城”!
第二步:源码定位
从资料搜集中 , 我们“有幸”找到了源码相关的源码目录 。 但是这并非意味着我们的确就是分析这个目录下的源代码 。 有时我们找到的目录有可能是分散的 , 也有时我们找到的目录下有很多和具体机器相关的代码 , 而我们更关心的是待分析代码的主要机制 , 而非与机器相关的特化代码(这样更有助于我们理解内核的本质) 。 因此 , 我们需要对资料中涉及代码文件的资料进行仔细甄选 。 当然 , 这一步也不太可能一次性完成 , 谁也不能保证一次就能选择出所有待分析的源码文件而且一个不漏 。 但是我们也不必担心 , 只要我们能抓住大多数模块相关的核心源文件 , 通过后期对代码的具体分析 , 就很自然的把它们全部找出来 。
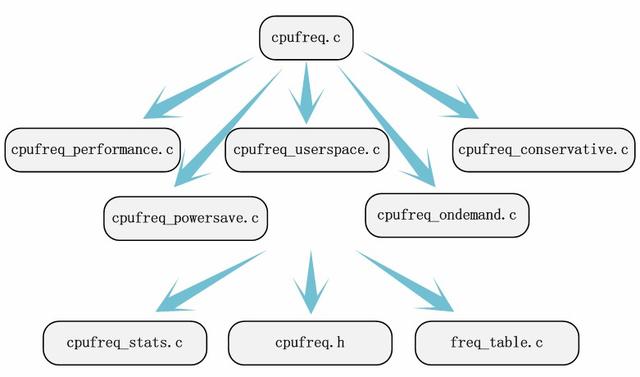
回到上述的例子中 , 我们认真的阅读/documention/cpufreq下的文档说明 。 目前的Linux源码会把模块相关的文档说明保存在源码目录的documention的文件夹下 , 如果待分析的模块没有文档说明 , 这多少会增加定位关键源码文件的难度 , 但是不会导致我们找不到我们要分析的源码 。 通过阅读文档说明 , 我们至少能关注到/driver/cpufreq/cpufreq.c这个源文件 。 通过这个对源文件的文档说明 , 结合之前搜罗到的调频策略 , 我们很容易关注到cpufreq_performance.c、cpufreq_powersave.c、cpufreq_userspace.c、cpufreq_ondemand、cpufreq_conservative.c这五个源文件 。 所有涉及的文件都找完了吗?不用担心 , 从它们开始分析 , 迟早能找到其他的源文件 。 如果在windows下使用sourceinsight阅读内核源码的话 , 我们通过函数的调用和查找符号引用等功能 , 结合代码的分析可以很方便的找到另外的文件freq_table.c、cpufreq_stats.c和/include/linux/cpufreq.h 。
 文章插图
文章插图
按照搜索出的信息流动方向 , 我们完全可以定位到需要分析的源码文件 。 源码定位这一步并非十分关键 , 因为我们不需要找出所有源码文件 , 我们可以把部分工作推迟到分析代码的过程中 。 源码定位也比较关键 , 找到一部分源码文件是分析源码的基础 。
第三步:简单注释
在已定位好的源码文件中 , 分析每个变量、宏、函数、结构体等代码元素的大致含义和功能 。 之所以称此为简单注释 , 并非指这部分的注释工作很简单 , 而是指这部分的注释可以不必过分细化 , 只要大致描述出相关代码元素的含义即可 。 相反 , 这里的工作其实是整个分析流程中最困难的一步 。 因为这是第一次深入到内核代码的内部 , 尤其是对于首次分析内核源码的人来说 , 大量的生疏
- AMD Zen3 APU内核图提前偷跑:三级缓存质变
- 苹果M1、A14内核设计对比:差别很大
- Linux Kernel 5.10.5发布:禁用FBCON加速滚动特性
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- Fedora正在寻求协助 希望加快Linux 5.10 LTS内核测试进度
- Linux Mint 20.1 Ulyssa稳定版已确定延期至2021年初发布
- 英特尔Xe GPU在Linux 5.11上的性能表现不错
- MIPS架构厂商日渐式微 Linux报告其漏洞遭遇困难
- 苹果M1、A14内核设计对比:迥然不同
- Linux Kernel 5.11首个候选版本更新发布