HBase你真的了解吗?( 五 )
- 数据的持久化文件 HFile 中是按照 KeyValue 存储的 , 如果 Rowkey 过长比如 100 个字 节 , 1000 万列数据光 Rowkey 就要占用 100*1000 万=10 亿个字节 , 将近 1G 数据 , 这会极大 影响 HFile 的存储效率;
- MemStore 将缓存部分数据到内存 , 如果 Rowkey 字段过长内存的有效利用率会降低 ,系统将无法缓存更多的数据 , 这会降低检索效率 。 因此 Rowkey 的字节长度越短越好 。
- 目前操作系统是都是 64 位系统 , 内存 8 字节对齐 。 控制在 16 个字节 , 8 字节的整数 倍利用操作系统的最佳特性 。
- 散列原则
- 如果 Rowkey 是按时间戳的方式递增 , 不要将时间放在二进制码的前面 , 建议将 Rowkey 的高位作为散列字段 , 由程序循环生成 , 低位放时间字段 , 这样将提高数据均衡分布在每个 Regionserver 实现负载均衡的几率 。 如果没有散列字段 , 首字段直接是时间信息将产生所有 新数据都在一个 RegionServer 上堆积的热点现象 , 这样在做数据检索的时候负载将会集中 在个别 RegionServer , 降低查询效率 。
- 唯一原则
- 必须在设计上保证其唯一性 。 rowkey 是按照字典顺序排序存储的 , 因此 , 设计 rowkey 的时候 , 要充分利用这个排序的特点 , 将经常读取的数据存储到一块 , 将最近可能会被访问 的数据放到一块 。
- 解决热点问题
- 加盐
- HASH
- 反转
- 时间戳反转
- 什么是SnapshotHBase 从0.95开始引入了Snapshot , 可以对table进行Snapshot , 也可以Restore到Snapshot 。 Snapshot可以在线做 , 也可以离线做 。 Snapshot的实现不涉及到table实际数据的拷贝 , 仅仅拷贝一些元数据 , 比如组成table的region info , 表的descriptor , 还有表对应的HFile的文件的引用 。
# 建立快照:snapshot 'tableName', 'snapshotName'?# 列出快照:list_snapshots?# 删除快照delete_snapshot 'snapshotName'?# 从快照复制生成一个新表clone_snapshot 'snapshotName', 'newTableName'?# 用快照恢复数据 , 它需要先禁用表 , 再进行恢复disable 'tableName' restore_snapshot 'snapshotName'九、HBase调优9.1 读性能调优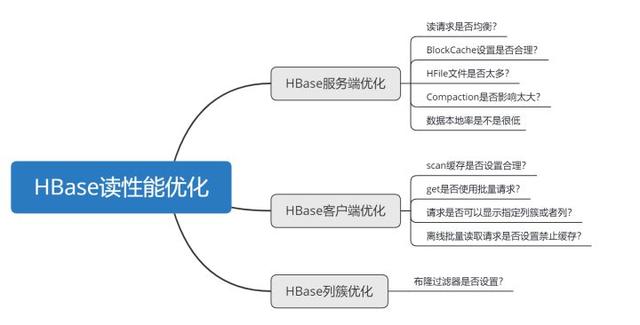 文章插图
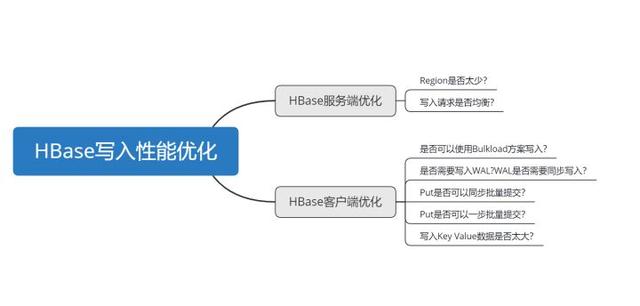
文章插图9.2 写性能调优
 文章插图
文章插图十、高级应用10.1 MR操作HBase
- HBase作为MR的数据源 , 实现聚合操作
- 使用HBase的SnapShot获取相应的HFile文件地址 , MR操作HFile文件
- HBase作为Hive的外表 , 实现离线分析
- iQOO 7邀请函曝光“马”“鸭”“羊”代表什么
- 只需799元就可以把旧iPad换成新款iPad?是真的!但这羊毛可没那么容易薅
- 更便宜的米11系列新品要来了,小米11Lite了解下
- 华为手机备忘录真的太赞了,居然集成了7大功能,个个都非常实用
- 爱立信突然宣布!瑞典“坏消息”从天而降?华为5G真的没辙了?
- 真的开始普及了,全天候全地形按摩放松神器
- 人工智能正在了解人类的“言外之意”
- “低价误国,高价兴邦”,小米真的做错了吗?
- APP真的能偷听吗?千款APP被检查,专家:可以实现
- 华为要让专家当家,你了解华为吗?华为对于中国创业者真正的意义