HBase你真的了解吗?( 二 )
- RegionServer
- 管理Master分配的Region
- 处理来自Client的读写请求
- 和底层的HDFS交互 , 存储数据Flush到HDFS中
- 负责Region变大之后的拆分
- 负责StoreFile的合并工作 , 防止小文件过多
- HRegion
- 数据表的行方向的切割分片 , 分布在不用的Region Server 。
- Region由一个或者多个Store组成 , 每个Store保存一个Column Family 。
- 每个Region由以下信息标识:< 表名,StartRowkey,创建时间>
- Store
- 每一个Region由一个或多个Store组成 , 每个 ColumnFamily对应一个Store
- 一个Store由一个memStore和0或者 多个StoreFile组成
- HBase以store的大小来判断是否需要切分region
- MemStore
- MemStore是一个内存级别的存储 , 一个列族Store对应一个MemStore
- 当MemStore的大小达到一个阀值时 , MemStore会被flush到文 件
- StoreFile
- StoreFile是磁盘级别存储的文件组件
- Memstore内存中的数据写到文件后就是StoreFile , StoreFile底层是以HFile的格式保存
- 当Storefile文件的数量增长到一定阈值后 , 系统会进行合并 ,
- 在合并过程中会进行版本合并和删除工作 , 形成更大的Storefile
- HFile
- HFile是StoreFile的存储格式 , 例如txt、orc等
- 查看HFile文件数据命令hbase org.apache.hadoop.hbase.io.hfile.HFile -e -p -f 文件路径
- WAL(HLog)
- 保证数据的高可靠性:HBase随机写入数据的时候 , 先写入缓存 , 再异步刷新落盘 , 为了防止缓存数据丢失 , 数据写入缓存之前需要首先顺序写入HLog
- HDFS
- 实际存储数据的分布式文件系统
- 数据默认3副本存储策略有效保证数据的高可靠性
 文章插图
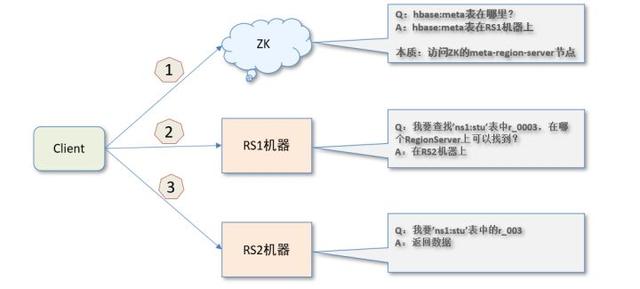
文章插图- 寻址步骤:
- 第 1 步:Client 请求 Zookeeper 获取hbase:meta元数据表所在的 RegionServer 的地址 。
- 第 2 步:Client 请求hbase:meta所在的 RegionServer 再次获取访问数据所在的 RegionServer 地址 , Client 会将hbase:meta的相关信息 cache 下来 , 以便下一次快速访问 。
- Region的RowKey构成:表名,StartRowkey,创建时间.整体进行MD5 Hash值
- 第 3 步:Client 请求数据所在的 RegionServer , 操作数据 。
6.3 写入流程
- 写流程1、Client 先根据 RowKey 找到对应的 Region 所在的 RegionServer2、Client 向 RegionServer 提交写请求3、RegionServer 找到目标 Region4、Region 检查数据是否与 Schema 一致5、如果客户端没有指定版本 , 则获取当前系统时间作为数据版本6、将更新写入 WAL Log7、将更新写入 MemStore8、判断 MemStore 的是否需要 flush 为 StoreFile 文件 。
- 写流程源码查看
- 流程1、客户端通过 ZooKeeper 以及-ROOT-表和.META.表找到目标数据所在的 RegionServer(就是 数据所在的 Region 的主机地址)2、联系 RegionServer 查询目标数据3、RegionServer 定位到目标数据所在的 Region , 发出查询请求4、Region 先在 Memstore 中查找 , 命中则返回5、如果在 MemStore 中找不到 , 则在 StoreFile 中扫描 为了能快速的判断要查询的数据在不在这个 StoreFile 中 , 应用了 BloomFilter
- iQOO 7邀请函曝光“马”“鸭”“羊”代表什么
- 只需799元就可以把旧iPad换成新款iPad?是真的!但这羊毛可没那么容易薅
- 更便宜的米11系列新品要来了,小米11Lite了解下
- 华为手机备忘录真的太赞了,居然集成了7大功能,个个都非常实用
- 爱立信突然宣布!瑞典“坏消息”从天而降?华为5G真的没辙了?
- 真的开始普及了,全天候全地形按摩放松神器
- 人工智能正在了解人类的“言外之意”
- “低价误国,高价兴邦”,小米真的做错了吗?
- APP真的能偷听吗?千款APP被检查,专家:可以实现
- 华为要让专家当家,你了解华为吗?华为对于中国创业者真正的意义