使用tensorflow和Keras的初级教程( 四 )
评估输出X_test = preprocessing.normalize(X_test)results = model.evaluate(X_test, y_test.values)1781/1781 [==============================] - 1s 614us/step - loss: 0.0086 - accuracy: 0.9989用Tensor Board分析学习曲线TensorBoard是一个很好的交互式可视化工具 , 可用于查看训练期间的学习曲线、比较多个运行的学习曲线、分析训练指标等 。 此工具随TensorFlow自动安装 。
import osroot_logdir = os.path.join(os.curdir, “my_logs”)def get_run_logdir(): import time run_id = time.strftime(“run_%Y_%m_%d-%H_%M_%S”) return os.path.join(root_logdir, run_id)run_logdir = get_run_logdir()tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)model.fit(X_train, y_train.values, batch_size = 2000, epochs = 20, verbose = 1, callbacks=[tensorboard_cb])%load_ext tensorboard%tensorboard --logdir=./my_logs --port=6006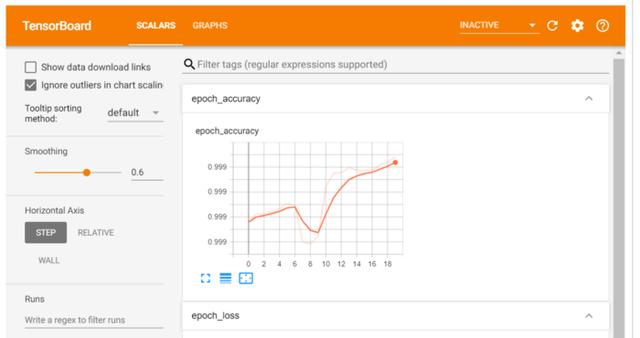 文章插图
文章插图
超参调节如前所述 , 对于一个问题空间 , 有多少隐藏层或多少神经元最适合 , 并没有预定义的规则 。 我们可以使用随机化searchcv或GridSearchCV来超调一些参数 。 可微调的参数概述如下:
- 隐藏层数
- 隐藏层神经元
- 优化器
- 学习率
- epoch
def build_model(n_hidden_layer=1, n_neurons=10, input_shape=29):# 创建模型model = Sequential()model.add(Dense(10, input_shape = (29,), activation = 'tanh'))for layer in range(n_hidden_layer):model.add(Dense(n_neurons, activation="tanh"))model.add(Dense(1, activation = 'sigmoid'))# 编译模型model.compile(optimizer ='Adam', loss = 'binary_crossentropy', metrics=['accuracy'])return model使用包装类克隆模型from sklearn.base import clonekeras_class = tf.keras.wrappers.scikit_learn.KerasClassifier(build_fn = build_model,nb_epoch = 100, batch_size=10)clone(keras_class)keras_class.fit(X_train, y_train.values)创建随机搜索网格from scipy.stats import reciprocalfrom sklearn.model_selection import RandomizedSearchCVparam_distribs = { “n_hidden_layer”: [1, 2, 3], “n_neurons”: [20, 30],# “learning_rate”: reciprocal(3e-4, 3e-2),# “opt”:[‘Adam’]}rnd_search_cv = RandomizedSearchCV(keras_class, param_distribs, n_iter=10, cv=3)rnd_search_cv.fit(X_train, y_train.values, epochs=5)检查最佳参数rnd_search_cv.best_params_{'n_neurons': 30, 'n_hidden_layer': 3}rnd_search_cv.best_score_model = rnd_search_cv.best_estimator_.model优化器也应该微调 , 因为它们影响梯度下降、收敛和学习速率的自动调整 。- Adadelta -Adadelta是Adagrad的一个更健壮的扩展 , 它基于梯度更新的移动窗口来调整学习速率 , 而不是累积所有过去的梯度
- 随机梯度下降-常用 。 需要使用搜索网格微调学习率
- Adagrad-对于所有参数和其他优化器的每个周期 , 学习速率都是恒定的 。 然而 , Adagrad在处理误差函数导数时 , 会改变每个参数的学习速率“η” , 并在每个时间步长“t”处改变
- ADAM-ADAM(自适应矩估计)利用一阶和二阶动量来防止跳越局部极小值 , 保持了过去梯度的指数衰减平均值
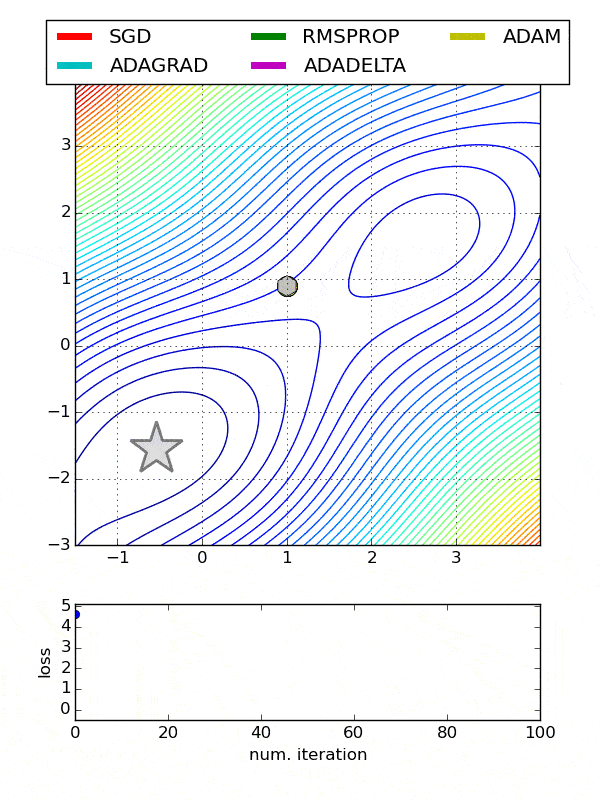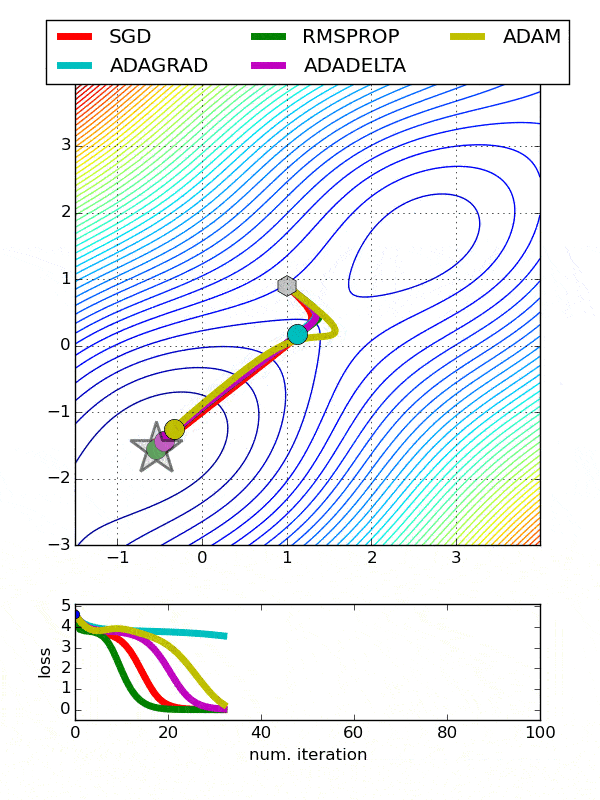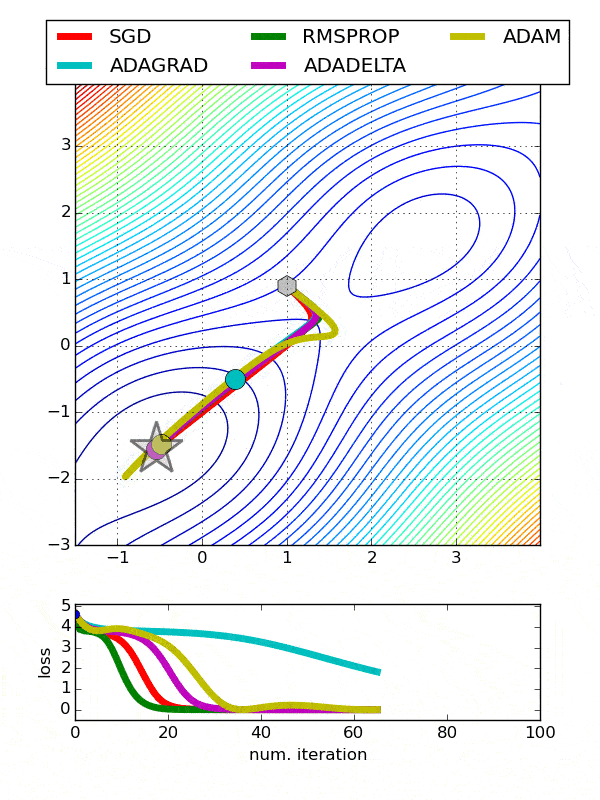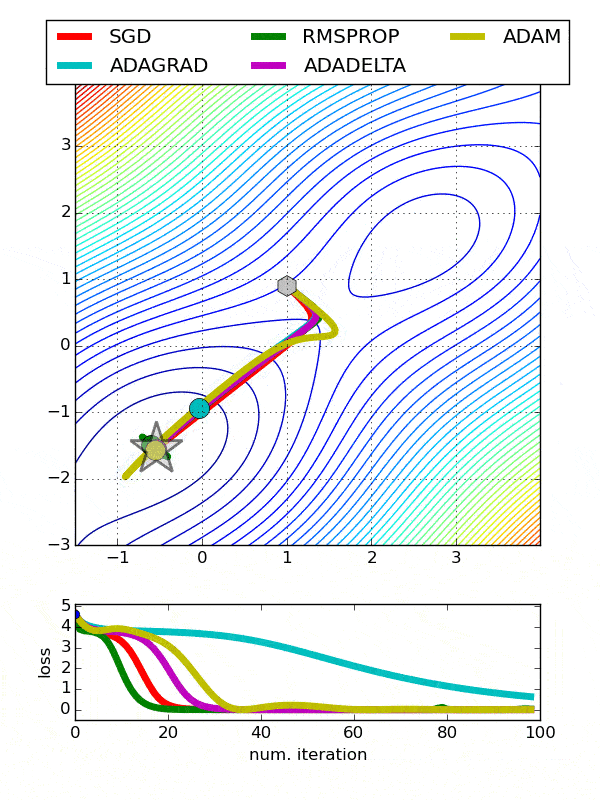 文章插图
文章插图
- 或使用天玑1000+芯片?荣耀V40已全渠道开启预约
- 苹果将推出使用mini LED屏的iPad Pro
- 手机能用多久?如果出现这3种征兆,说明“默认使用时间”已到
- 苹果有望在2021年初发布首款使用mini LED显示屏的 iPad Pro
- 笔记本保养有妙招!学会这几招笔记本再战三年
- 数据可视化三节课之二:可视化的使用
- 索尼sw77与sw55的使用差别感受
- 爆料称一加9系列与潜望式镜头无缘 继续使用普通长焦
- 太空舱|四川绵阳:中国首款智慧移宿空间亮相 使用寿命可达50年
- 电影制作专业学生使用AI创作《汉密尔顿》歌词,意外提到了希拉里