ML Ops:数据质量是关键( 二 )
即使是在数据集处理的早期阶段 , 从长远来看 , 对数据进行质量检查和文档记录可以极大地加速操作 。 对于工程师来说 , 可靠的数据测试非常重要 , 可以使他们安全地对数据获取 pipeline 进行更改 , 而不会造成不必要的问题 。 同时 , 当从内部和外部上游来源获取数据时 , 为了确保数据出现未预料的更改 , 在获取阶段进行数据验证是非常重要的 。
 文章插图
文章插图
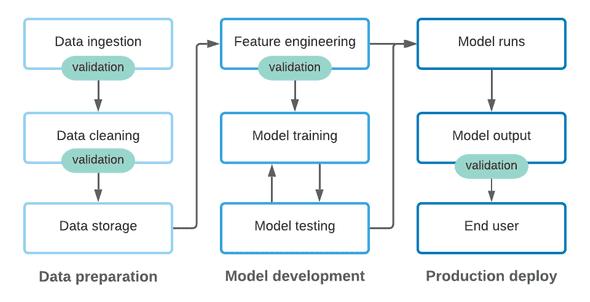
模型开发
本文将特征工程、模型训练和模型测试作为核心模型开发流程的一部分 。 在这个不断迭代的过程中 , 围绕数据转换代码和支持数据科学家的模型输出提供支持 , 因此在一个地方进行更改不会破坏其他地方的内容 。
在传统的 DevOps 中 , 通过 CI/CD 工作流进行持续的测试 , 可以快速地找出因代码修改而引入的任何问题 。 更进一步 , 大多数软件工程团队要求开发人员不仅要使用现有的测试来测试代码 , 还要在创建新功能时添加新的测试 。 同样 , 运行测试以及编写新的测试应该是 ML 模型开发过程的一部分 。
在生产中运行模型
与所有 ML Ops 一样 , 在生产环境中运行的模型依赖于代码和输入数据 , 来产生可靠的结果 。 与数据获取阶段类似 , 我们需要保护数据输入 , 以避免由于代码更改或实际数据更改而引起的不必要问题 。 同时 , 我们还应该围绕模型输出进行一些测试 , 以确保模型继续满足我们的期望 。
【ML Ops:数据质量是关键】尤其是在具有黑盒 ML 模型的环境中 , 建立和维护质量标准对于模型输出至关重要 。 同样地 , 在共享区域记录模型的预期输出可以帮助数据团队和利益相关者定义和传达「数据合同」 , 从而增加 ML pipeline 的透明度和信任度 。
 文章插图
文章插图
- “千店同开”引质量担忧,小米回应
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- iPhone质量怎么样?吴彦祖射了一箭还能用
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能