ML Ops:数据质量是关键
选自Great Expectations Blog
作者:Great Expectations
机器之心编译
编辑:陈萍
ML Ops 是 AI 领域中一个相对较新的概念 , 可解释为「机器学习操作」 。 如何更好地管理数据科学家和操作人员 , 以便有效地开发、部署和监视模型?其中数据质量至关重要 。
 文章插图
文章插图
本文将介绍 ML Ops , 并强调数据质量在 ML Ops 工作流中的关键作用 。
ML Ops 的发展弥补了机器学习与传统软件工程之间的差距 , 而数据质量是 ML Ops 工作流的关键 , 可以加速数据团队 , 并维护对数据的信任 。
什么是 ML Ops
ML Ops 这个术语从 DevOps 演变而来 。
DevOps 是一组过程、方法与系统的统称 , 用于促进开发(应用程序 / 软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合 。 DevOps 旨在重视软件开发人员(Dev)和 IT 运维技术人员(Ops)之间沟通合作的文化、运动或惯例 。 透过自动化软件交付和架构变更的流程 , 来使得构建、测试、发布软件能够更加地快捷、频繁和可靠 。
而 MLOps 基于可提高工作流效率的 DevOps 原理和做法 , 例如持续集成、持续交付和持续部署 。 ML Ops 将这些原理应用到机器学习过程 , 其目标是:
更快地试验和开发模型
更快地将模型部署到生产环境
质量保证
DevOps 的常用示例是使用多种工具对代码进行版本控制 , 如 git、代码审查、持续集成(CI , 即频繁地将代码合并到共享主线中)、自动测试和持续部署(CD , 即自动将代码合并到生产环境) 。
在应用于机器学习时 , ML Ops 旨在确保模型输出质量的同时 , 加快机器学习模型的开发和生产部署 。 但是 , 与软件开发不同 , ML 需要处理代码和数据:
机器学习始于数据 , 而数据来源不同 , 需要用代码对不同来源数据进行清洗、转换和存储 。
然后 , 将处理好的数据提供给数据科学家 , 数据科学家进行代码编写 , 完成特征工程、开发、训练和测试机器学习模型 , 最终将这些模型部署到生产环境中 。
在生产中 , ML 模型是以代码的形式存在的 , 输入数据同样可以从各种来源获取 , 并创建用于输入产品和业务流程的输出数据 。
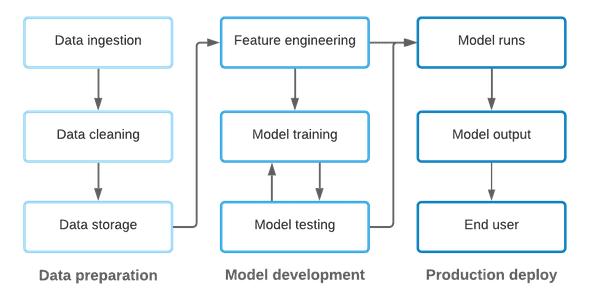 文章插图
文章插图
虽然上文的描述对该过程进行了简化 , 但是仍然可以看出代码和数据在 ML 环境中是紧密耦合的 , 而 ML Ops 需要兼顾两者 。
具体来说 , 这意味着 ML Ops 包含以下任务:
对用于数据转换和模型定义的代码进行版本控制;
在投入生产之前 , 对所获取的数据和模型代码进行自动测试;
在稳定且可扩展的环境中将模型部署到生产中;
监控模型性能和输出 。
数据测试和文档记录如何适配 ML Ops?
ML Ops 旨在加速机器学习模型的开发和生产部署 , 同时确保模型输出的质量 。 当然 , 对于数据质量人员来说 , 要实现 ML 工作流中各个阶段的加速和质量 , 数据测试和文档记录是非常重要的:
在利益相关者方面 , 质量差的数据会影响他们对系统的信任 , 从而对基于该系统做出决策产生负面影响 。 甚至更糟的是 , 未引起注意的数据质量问题可能导致错误的结论 , 并纠正这些问题又会浪费很多时间 。
在工程方面 , 急于修复下游消费者注意到的数据质量问题 , 是消耗团队时间并缓慢侵蚀团队生产力和士气的头号问题之一 。
此外 , 数据文档记录对于所有利益相关者进行数据交流、建立数据合同至关重要 。
下文将从非常抽象的角度介绍 ML pipeline 中的各个阶段 , 并讨论数据测试和文档记录如何适应每个阶段 。
数据获取阶段
- “千店同开”引质量担忧,小米回应
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- iPhone质量怎么样?吴彦祖射了一箭还能用
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能