语法数据扩增提升推理启发法的鲁棒性( 三 )
我们没有试图确保生成实例的自然性;例如 , 在倒置转换中 , 车厢造成了大量噪音(The carriage made a lot of noise)被转换成大量噪音造成了车厢(A lot of noise made the carriage) 。 此外 , 扩增数据集的标签存在一些噪音;例如 , 我们假设倒置将正确的标签从蕴含改为中性 , 但是也并非必然如此(如果买方遇到卖方(The buyer met the seller) , 那么卖方遇到买方(The seller met the buyer)是有可能的) 。
最后 , 我们包括一个随机的打乱条件 , 其中 MNLI 前提及其假设都被随机打乱 。 我们使用这个情况来测试语法上不知情的方法是否能教会这个模型:当忽略单词顺序时 , 就无法做出可靠的推论 。
4. 试验设置? 我们将每个扩增集分别添加到 MNLI 的训练集中 , 并对每个生成的训练集进行微调 BERT 的训练 。 微调的更多细节在附录 A.1 中 。 我们为扩增策略与扩增集大小的每种组合重复了五个随机种子的过程 , 但最成功的策略(倒置+转换假设(INVERSION+TRANSFORMED HYPOTHESIS))除外 。 且对于每个扩增的范围 , 均进行了 15 次运行 。 参照 McCoy 等人(2019b) , 在对 HANS 进行评估时 , 我们将模型产生的中性与矛盾标签合并为一个单一的非蕴含(non-entailment)标签 。
? 对于原始前提(ORIGINAL PREMISE)与转换假设(TRANSFORMED HYPOTHESIS) , 我们尝试了分别使用每一种转换 , 并使用了包含倒置与被动化的数据集进行了实验 。 我们还分别对仅使用带有蕴含标签的被动化例子和仅使用带有非蕴含标签的被动化例子进行了单独的实验 。 作为基线 , 我们使用了 100 次在未进行数据扩增的 MNLI 上训练出的微调的 BERT 模型(McCoy et al., 2019a) 。
? 我们会报告模型在 HANS 上的准确性和在 MNLI 的开发集上的准确性(MNLI 测试集的标签不公开) 。 我们没有调整这个开发集的任何参数 。 我们下面讨论的所有比较都在 p<0.01 的水平上 , 比较结果都是十分显著的(基于双向 t 检验) 。
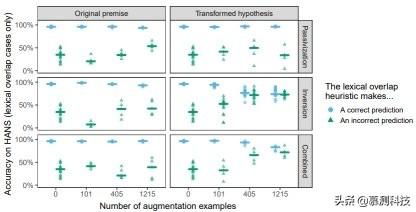
5. 结果? MNLI 的准确性在不同的扩增策略中都非常相似 , 并且与未经扩增的基线(0.84)相匹配 , 这表明最多有 1215 个实例的语法扩增不会损害数据集的整体表现 。 相比之下 , HANS 的准确度差异很大 , 大多数模型在非蕴含的实例中的表现得比置信准确度差(在 HANS 上为 0.5) , 这表明了它们采用了启发法(图 1) 。 很大程度上 , 最有效的扩增策略是倒置结合转换假设 。 HANS 在单词重叠案例(其中正确的标签都是非蕴含的 , 例如:
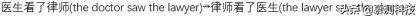 文章插图
文章插图
)的准确度在没有数据扩增的情况下为 0.28 , 在大型扩增集上为 0.73 。 同时 , 在启发法做出正确预测的情况下(如
 文章插图
文章插图
) , 这种策略降低了 BERT 的准确性;实际上 , 在词汇重叠做出正确与不正确的预测情况下 , 最佳模型的准确度都是相似的 , 这表明了这种干预阻止了模型采用启发法 。
 文章插图
文章插图
图 1:语法增强策略的比较 。 点表示诊断词汇重叠启发法对 HANS 实例的准确度 , 这是由在 MNLI 上微调的 BERT 的每次运行与每个扩增的数据集相结合所得到的 。 水平条表示整体运行的中位数准确度 。 置信准确度为 0.5 。
随机打乱的方法并未使模型在未经扩增的基线上得到了改善 , 表明关注语法的转换是必要的(表 A.2) 。 被动化比倒置的收益要小得多 , 这可能是由于存在显式的标记引起的(如单词 by) , 这可能导致模型仅在这些单词出现时才考虑词序 。 有趣的是 , 即使是在 HANS 的被动实例中 , 倒置也仍比被动化更有效(大型倒置扩增:0.13;大型被动化扩增:0.01) 。 最后 , 自身倒置比倒置与被动化的结合更有效 。
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 阳狮报告:4成受访者认为自己的数据比免费服务更有价值
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 学习大数据是否需要学习JavaEE
- 意大利运营商Ho Mobile被曝数据泄露
- 微软官方数据恢复工具即将更新:更易于上手 优化恢复性能
- HDMI 2.1诞生三年:超高速数据线落地 8K电视圆满了
- Mozilla将默认禁用Firefox中的退格键以防止用户编辑数据丢失
- iPhone或取消卡针数据线等配件,苹果将推出mini LED屏iPad Pro