挑战新物体描述问题,视觉词表解决方案超越人类表现
编者按:最近 , 研究者们发布了 nocaps 挑战 , 用以测量在没有对应的训练数据的情况下 , 模型能否准确描述测试图像中新出现的各种类别的物体 。 针对挑战中的问题 , 微软 Azure 认知服务团队和微软研究院的研究员提出了全新解决方案视觉词表预训练 (Visual Vocabulary Pre-training) 。 该方法在 nocaps 挑战中取得了新的 SOTA , 并首次超越人类表现 。
看图说话“新”问题图像描述或看图说话(Image Captioning)是计算机根据图片自动生成一句话来描述其中的内容 , 由于其潜在的应用价值(例如人机交互和图像语言理解)而受到了广泛的关注 。 这项工作既需要视觉系统对图片中的物体进行识别 , 也需要语言系统对识别的物体进行描述 , 因此存在很多复杂且极具挑战的问题 。 其中 , 最具挑战的一个问题就是新物体描述(Novel object captioning) , 即描述没有出现在训练数据中的新物体 。
最近 , 研究者们发布了 nocaps 挑战() , 以测量在即使没有对应的训练数据的情况下 , 模型能否准确描述测试图像中新出现的各种类别的物体 。 在这个挑战中 , 虽然没有配对的图像和文本描述(caption)进行模型训练 , 但是可以借助计算机视觉的技术来识别各类物体 。 例如在一些之前的工作中 , 模型可以先生成一个句式模板 , 然后用识别的物体进行填空 。 然而 , 这类方法的表现并不尽如人意 。 由于只能利用单一模态的图像或文本数据 , 所以模型无法充分利用图像和文字之间的联系 。 另一类方法则使用基于 Transformer 的模型进行图像和文本交互的预训练(Vision and Language Pre-training) 。 这类模型在多模态(cross-modal)的特征学习中取得了有效的进展 , 从而使得后续在图像描述任务上的微调(fine-tuning)获益于预训练中学到的特征向量 。 但是 , 这类方法依赖于海量的训练数据 , 在这个比赛中无法发挥作用 。
针对这些问题 , 微软 Azure 认知服务团队和微软研究院的研究员们提出了全新的解决方案 Visual Vocabulary Pre-training(视觉词表预训练 , 简称VIVO) , 该方法在没有文本标注的情况下也能进行图像和文本的多模态预训练 。 这使得训练不再依赖于配对的图像和文本标注 , 而是可以利用大量的计算机视觉数据集 , 如用于图像识别问题的类别标签(tag) 。 借助这个方法 , 模型可以通过大规模数据学习建立多种物体的视觉外表和语义名称之间的联系 , 即视觉词表(Visual Vocabulary)的建立 。 目前 , VIVO 方法在 nocaps 挑战中取得了新的 SOTA(即当前最优表现) , 并且首次超越了人类表现 。
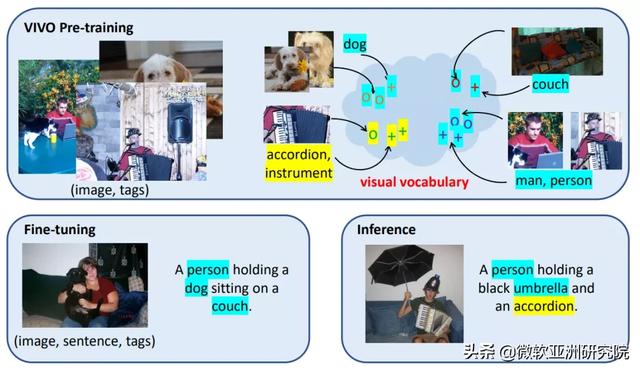
视觉词表成为解决问题的关键VIVO 方法取得成功的关键在于视觉词表(visual vocabulary)的建立 。 如图1所示 , 研究人员把视觉词表定义为一个图像和文字的联合特征空间(joint embedding space) , 其中语义相近的词汇 , 例如男人和人、手风琴和乐器 , 会被映射到距离更近的特征向量上 。 在预训练学习建立了视觉词表以后 , 模型还会在有对应的文本描述的小数据集上进行微调 。 微调时 , 训练数据只需要涵盖少量的共同物体 , 例如人、狗、沙发 , 模型就能学习如何根据图片和识别到的物体来生成一个通用的句式模板 , 并且把物体填入模板中相应的位置 , 例如 , “人抱着狗” 。 在测试阶段 , 即使图片中出现了微调时没有见过的物体 , 例如手风琴 , 模型依然可以使用微调时学到的句式 , 加上预训练建立的视觉词表进行造句 , 从而得到了“人抱着手风琴”这句描述 。
 文章插图
文章插图
图1:VIVO 预训练使用大量的图片标签标注来建立视觉词表
VIVO 预训练使用大量的图片标签标注来建立视觉词表 , 其中语义相近的词汇与对应的图像区域特征会被映射到距离相近的向量上 。 微调使用只涵盖一部分物体(蓝色背景)的少量文本描述标注进行训练 。 在测试推理时 , 模型能够推广生成新物体(黄色背景)的语言描述 , 得益于预训练时见过的丰富物体类型 。
- 腾讯游戏发起对华为的挑战,或因后者对国内手机市场的影响力大跌
- 新型纯蓝OLED可克服目前显示屏蓝光性能不足的挑战
- “机器人妻子”上市遭抢购,是在解决刚需,还是在挑战伦理?
- 苹果服务收入大增 反垄断将成为最大挑战
- Galaxy Note 20挑战者:Moto G Stylus 2021的渲染图出现
- 日本正式官宣!中国院士多次发声,中国的5G、6G面临双重挑战
- 中国这项技术领先世界,首次发起挑战,英国人:美国可不敢这样玩
- 库克还笑得出来吗?纬创工厂事件后苹果又迎新挑战,网友拍手叫好
- 约束"硅谷帝国"——监管科技巨头的困境与挑战
- 再见了,扫码支付?新型支付方式试水成功,微信、支付宝迎来挑战