赛灵思姚颂:数字AI芯片进步趋缓,颠覆式创新难 | GTIC2020( 二 )
二、 AI芯片最需解决的是宽带问题紧接着 , 姚颂谈及对行业现状的看法 。 他说 , AI芯片这个词用得特别泛 , AI领域本身就特别宽泛 , 有一小部分才是机器学习 , 机器学习中的一小部分才是深度学习 , 深度学习天然切分为训练和推理两个阶段 , 其中有数不过来的各种神经网络 。
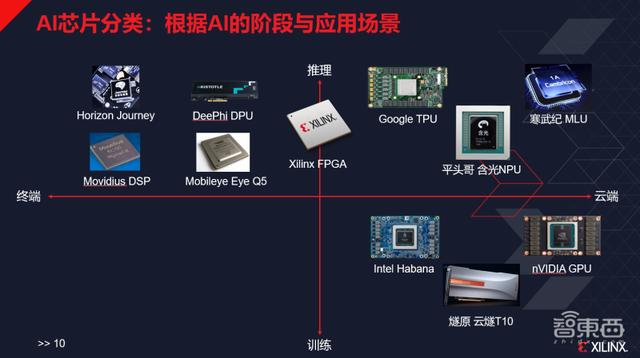
一个AI芯片可以指代的东西有很多 , 因此这是一个很宽泛的概念 , 按稍严格的分类 , 它可以分成训练、推理两个阶段 , 以及云端、终端两个应用场景 。 大家目前基本不在终端做训练 , 因此终端的场景象限基本是空的 。
 文章插图
文章插图
AI芯片分类:根据AI的阶段与应用场景
AI芯片核心解决的是什么问题?去堆并行算力?实际并不是 。
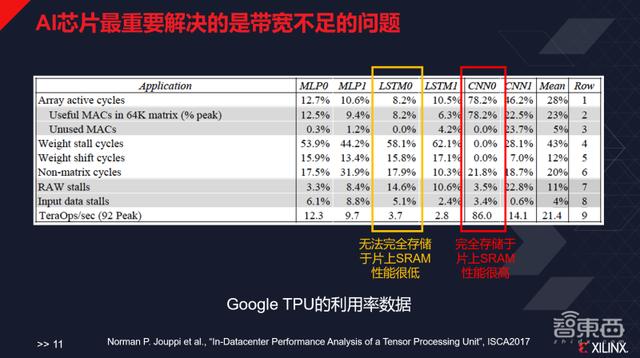
谷歌TPU第一代的论文中写道 , 其芯片最开始是为了自己设计的GoogLeNet做的优化 , CNN0的部分就是谷歌自己设计的Inception network , 谷歌设计的峰值性能是每秒92TeraOps , 而这个神经网络能跑到86 , 数值非常高;但是对于谷歌不太擅长的LSTM0 , 其性能只有3.7 , LSTM1的性能只有2.8 , 原因在于它整个的存储系统的带宽其实不足以支撑跑这样的应用 , 因而造成了极大的算力浪费 。
 文章插图
文章插图
AI芯片最重要解决的是带宽不足的问题
AI芯片最重要解决的问题核心是带宽不足的问题 , 其中一种最粗暴且奢侈的方式就是用大量的片上SRAM(静态随机存取存储器) , 比如原来寒武纪用36MB DRAM做DianNao , 深鉴科技曾用10.13MB SRAM做EIE , TPU采用过28MB SRAM 。
而将这种工程美学发挥到中最“残暴”的公司 , 叫做Cerebras , 它把一整个Wafer只切一片芯片 , 有18GB的SRAM , 所有的数据、模型都存在片上 , 因此其性能爆棚 。
当然这种方式是非常奢侈的 , Cerebras要为它单独设计解决制冷、应力等问题 , 单片芯片的成本就在1百万美元左右 , 对外一片芯片卖500美元 , 这一价格非常高昂 。 因此业内就需要用微架构等其他方式解决这一问题 。
业内常用的有两种解决方式:
一是在操作时加一些buffer , 因为神经网络是一个虽然并行 , 但层间又是串行的结构 。 把前一层的输出buffer住 , 或把它直接用到下一层作为输入 。
二是在操作时做一些切块 , 因为神经网络规模比较大 , 每次将它切一小部分 , 比如16X16 , 把切出来这一块的计算一次性做完 , 在做这部分计算的时候同步开始读取下一块的数据 , 让这件事像流水线一样串起来 , 就可以掩盖掉很多存储、读取的延迟 。
现在在数字电路层面 , 业内更多在做一些架构的更新 , 根据不同的应用需求做架构的设计 。
三、数字AI芯片颠覆式创新难在谈到AI芯片产业特点时 , 姚颂说 , 首先AI芯片的概念非常宽泛 , 所以它并不一定是特别难的事 。
 文章插图
文章插图
数字AI芯片产业特点
设计一颗特别通用的芯片很难 , 设计CPU和GPU同样很难 , 但是如果只做某一颗芯片 , 只支持某一个算法和某几个算法 , 其实并不太难 , 尤其是对算力的需求很低的时候 , 技术难度就没有那么大了 。 以至于现在对于一些简单的神经网络的加速 , 直接付钱给芯原微电子、GUC等机构 , 都可以帮助做前端定制 。 因此对于AI芯片还是要辩证看待 , 不同的东西难度也不同 。
第二 , 高集成度对于终端市场来说非常重要 , 这是所有做AI起家的公司都会认识到的一点 。
举例来说 , 如果厂商想要将AI芯片做到摄像头里面 , ISP怎么做、SoC谁来做?将AI芯片做到耳机里面 , 是语音唤醒的AI部分最终集成蓝牙做成SoC , 还是蓝牙的部分集成AI做成SoC?这些都是要考虑的问题 。
- 华为钱包2020年高光时刻 成为数字人民币离线钱包
- 微软等机构开发数字“新冠疫苗接种护照”
- 合合信息与腾讯云达成战略合作 共推数字化产业升级方案
- 系统|数字未来大会2021:项飚谈“系统人”,陈楸帆聊“内卷”
- 爷青回!MIX 4现身:这次真的要来了?
- 三星公司发布2021款数字座舱 集成诸多高科技
- 想实现《曼达洛人》的数字布景吗?索尼模块化屏幕即将开售
- 腾讯苏州战略合作再升级,腾讯(苏州)数字产业基地揭牌
- 索尼发布两款Crystal LED显示器 目标数字生产领域
- 向日葵领航·坐席解决方案:远程协助推进数字化医疗