人机交互过程拆解:是什么?怎么做?
编辑导读:AI改变了我们与机器互动的方式 , 影响了我们的生活 , 重新定义了我们与机器的关系 。 本文作者对人机交互的过程进行了分析拆解 , 对语音识别技术为什么能把语音信号变成文字展开了详细的说明 , 一起来看看~
 文章插图
文章插图
背景:市面上有哪些搭载类似交互系统的产品?
微信的小微平台、淘宝的淘小蜜、钉钉的智能工作助理、百度的小度等等 , 既有面向C端消费者 , 又有面向B端企业主 , 如果要论商业化的潜力无疑目前机器人行业很大程度上C端的机器人产品已经几乎被验证无法实现盈利了 , 参考微软小冰和siri , 不过未来教育行业的幼儿机器人也许是一条光明大道 。
更多的厂商已经转向了帮助企业主实现数字化管理、智能化办公而开发机器人能力 , 演化除了机器人的自定义平台 , 用于企业运维和管理 。
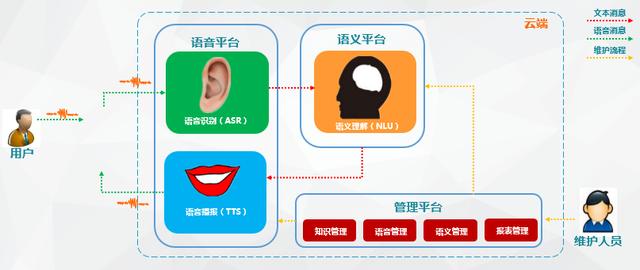
智能语音交互系统简单来讲:就是语音识别+语义理解+TTS
虽然说的简单 , 但是内部系统往往都比较复杂 , 每个点拆开来可能就足够我们去研究迭代一生 。 为何说AI时代的重点和基础是语音智能交互?在人工智能时代 , 人们发现语音比文字输入更能收集到有用的大量信息 , 这也是一种未来的主流形式 。
 文章插图
文章插图
语音交互流程
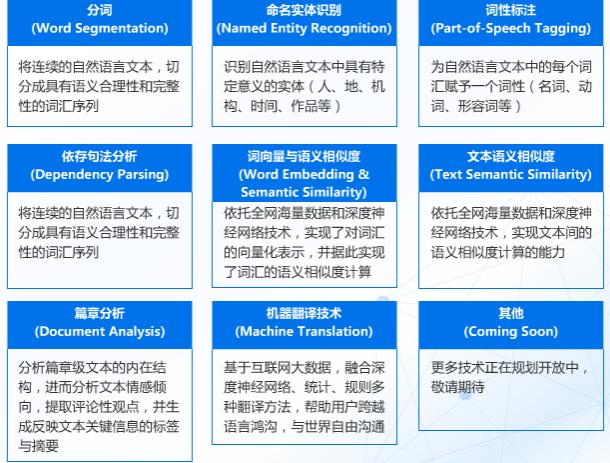
智能语音交互系统概括起来就是一段音频被机器人所吸收检测 , 将识别到到的语音信号截取、转换成语料库里读音信号频率最为相近的文字(所以也有人形容语音识别其实是一种概率事件) , 而文本会通过特定接口进入语义分析引擎 , 进行分析 。 其中就可能要进行分词、命名实体识别、词性标注、依存句法分析、词向量表示与语义相似度计算等NLP基础功能 。
 文章插图
文章插图
NLP基础技术
一般情况下都会首先进行分词分析:
例如:我想在房间里看电影
分词:【我】【想】【在】【房间】【看】【电影】
这就是分词的效果 。 而分词的目的是为了找出文字中最重要的核心语义 , 命名实体识别功能(假如需要的话)
分词:【我】【想】【在】【房间】【看】【电影】其中涉及到人物、地点、作品这些词汇就可以自动被提炼出来 , 很多应用场景会需要用到这种信息分类识别的能力 , 比如人口录入系统 , 只要将基本信息复制进去 , 自动分类此人的身份证号码、地址、年龄等需求信息 。
词性标注:词性标注可以帮助我们找到其中的名称、动词、 形容词等 。
依存句法分析的主要功能是能够针对句子找出句子的核心部分 , 比如分词:【我】【想】【在】【房间】【看】【电影】
经过词性标注和依存句法分析之后可以找出这句话的观点是:【在】【房间】【看】【电影】 , 这是整句话的核心 。
从而我们可以通过检索知识库中和分词内容相似度计算 , 并输出相似度最高答案 。
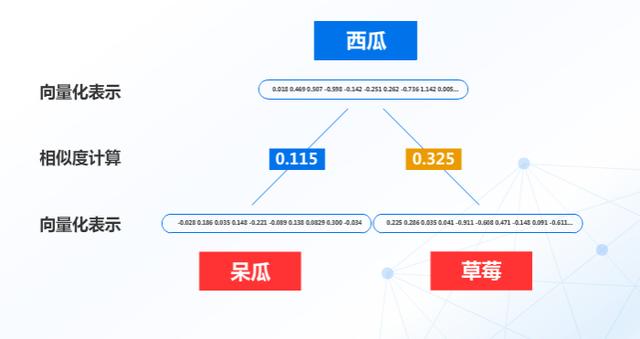
而词向量与相似度主要能解决什么问题呢?比如西瓜、呆瓜、草莓 , 在语义上哪两个更像呢?
这个时候我们可以将这三个词通过向量表达式工具和计算相似度来解决:
 文章插图
文章插图
可以明显的看出 , 语义上西瓜和草莓更相似 , 同属水果 , 这样就解决了大部分字面意思相近但是语义差别较大的情况 , 避免机器人错误理解人类的意图 。
回到题目 , 当我们的文本进入语义分析引擎 , 并经过上述的步骤后 , 计算相似度从而触发设定阀值以上的答案即可请求服务器发送正确答案给到终端处 , 如果需要机器人播报返回的文字时 , 可以接入TTS语音合成引擎(一般语音识别引擎就有这项功能) 。
- Java基础知识回顾,还记得吗?
- 「客制化过程」rx78 87主题键盘
- 贝尔金36W快充车充拆解,给iPhone12车上用好像不错
- 5099元游戏利器!蓝宝石RX 6800 XT显卡拆解图赏
- 戴尔首款90W氮化镓快充充电器拆解,果然氮化镓也不能改变你
- Linux 开发过程那么麻烦,是否值得?
- 拆解表明一加8T确实采用了双电池+增强散热设计
- 使用原位聚合增强"染色"过程,赋予纺织品电子特性
- 鼓励新能源废蓄电池再利用!不得随意拆解丢弃!罚款
- 华为22.5W电荷泵充电器拆解,小小充电器也可以做得这么好