数据仓库的治理一塌糊涂,没有管理好数据,最后都会怎么样
|0x00 老大难的数仓治理“年年数据要治理 , 数据年年治不好” 。
数仓治理的老大难 , 通常是跟着业务需求快跑 , 要不是数据零散在各个团队 , 或者是大家的研发规范有不同 , 作为一项通过维度模型来约束规范的工种来讲 , “模型”的治理难度 , 大于“架构” 。
目前整个行业通常的模型治理方法 , 是规定一种建模规范 , 大家在编码的过程中各自遵守 。 当业务开始变得模糊不清的时候 , 再专门抽调时间 , 来做人工治理 。 就像黄河一样 , 流沙清理了一次又一次 , 但上游还是会冲下新的流沙 。
 文章插图
文章插图
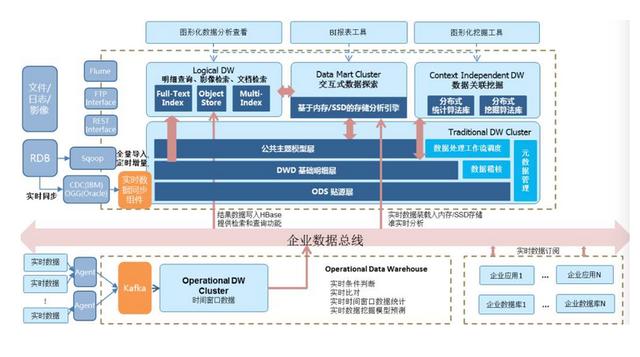
数仓的假设既然都是采用的维度建模 , 那么其设计思想必然是自下而上的进行建设 , 与架构进行类比 , 也就是先做好子模块 , 最后做顶层设计 。
但如果设计者不熟悉对应的领域模型 , 一旦业务上发生了变动 , 一张核心表动辄几百张的引用 , 会让重构的工作变得困难无比 。
【数据仓库的治理一塌糊涂,没有管理好数据,最后都会怎么样】强如阿里 , 会做一些更进一步的工作 , 比如模型的健康分 , 看看你的存储成本有多少、计算成本有多少、生命周期是不是合理、代码规范有没有避免全表扫描 , 等等 。 但这些工作只能发现一些常规的问题 , 也依然需要进行人工治理 , 不仅效率上没有得到提高 , 每天推送的邮件也会让你产生心烦 。
投入多少人 , 投入多少时间 , 终归是解决了一时的问题 , 而非长远 。
 文章插图
文章插图
因此 , 换个思路考虑问题 , 当业务高速发展时 , 数仓势必要跟着跑 , 不然业务都跪了 , 数仓又有何用 。 但业务通常不会一直处于高速发展的阶段 , 就像长跑一样 , 总有跑跑停停的时候 , 因此如果我们遵循一定的做事方法 , 流程上多一点步骤 , 那么就会极大的延缓数仓治理的问题 。
即不追求长久的问题解决 , 而以一段时间内的稳定为目标 , 比如一年 。 当业务已经发展到比较稳定的阶段 , 再回过头来做治理 , 既能够避免因为业务变动而影响模型重构 , 也可以节省大家的精力和压力 , 就不失为一种解决思路了 。
完美的解决方案通常不存在 , 退而求其次是大多数人的选择 。 当技术无法解决问题时 , 不妨用另类思路去解决 。
|0x01 事前:理论数仓的指导思想是什么?如果一定有定义 , 那么就是:以维度建模为基础 , 根据业务域和数据域设计主题模型 , 构建一致性的维度和事实 。
以下简略叙述理论 , 维度模型已经有很多的讲解文章 , 这里只是起到思路讲解的作用 。
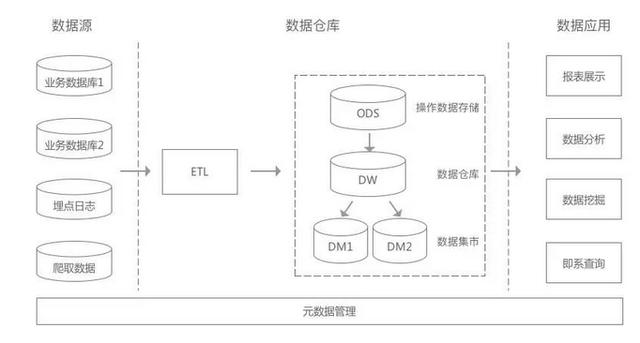
从宏观上讲 , 首先要了解数据的统计周期 , 是增量同步 , 还是全量同步 , 并根据预估的数据量设计ODS 。
其次 , 要大致了解业务域的划分情况 , 将一类不可拆分的行为作为一类 , 比如支付、比如搜索 。 当有了宏观的划分之后 , 就可以根据这些业务过程 , 构建最明细粒度的事实表 , 也就是DWD 。
再次 , 基于DWD便可以根据主题对象进行数据建模 , 构建公共粒度的汇总指标事实表 。 很多时候 , 由于需要加工一定的业务逻辑 , 可能带来DWD依赖DWS的情况 , 比如基于时间序列的业务过程 , 这里就需要避免统计类型或者业务类型的逻辑 , 加工到DWD中 , 这部分应该放到ADS层去做 。
 文章插图
文章插图
最后 , 定义好一致性的维度 , 即DIM 。 通常是静态的信息 , 如果存在动态可变的属性 , 还是放到DWD比较合适 。
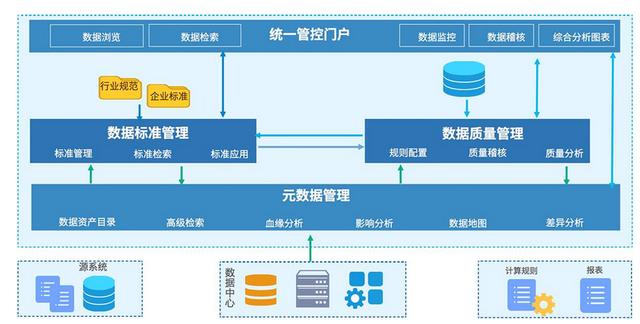
从这里开始 , 每位研发同学 , 都可以掌握维度建模的核心思想 , 通常公共层建设好之后 , 应该是变动极其小的 , 为了避免设计不好导致的后续维护问题 , 模型一定要有评审 , 即便是忙 , 也至少要找一个人帮忙进行CodeReview 。
- 「技术」这样的思路,让控制器中按键处理数据的方法变得简单了
- IPsecVPN(数据通信)
- 学大数据是否有前途 如何系统掌握大数据技术
- 分析|用数据量化方法透视不确定性世界
- 微信官方发布国庆假期消费大数据,来瞧瞧你的钱都花到哪了
- 数据|女生从事数据分析岗位会面临哪些压力
- 海云数据:用AI让不可能变成可能
- 面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测
- 开封市商务局与美团公司联合开展电子商务领域战略合作签约仪式暨白色污染治理倡议活动
- 澳大利亚留学—大数据分析