Redis的线程模型和事务( 二 )
我们可以理解成 , 因为Redis作为内存数据库 , 又有个很好的线程模型 , 并不存在io阻塞和CPU等性能瓶颈 。 再往后可以提升Redis空间的 , 就在于机器的内存和网络带宽了 。
3.2. 线程模型我之前的很多篇文章都提到了Reactor线程模型 , 像Tomcat、Netty等 , 都使用了Reactor线程模型来实现IO多路复用 , 这次再加上Redis 。 还记得之前有介绍Reactor模型有三种:单线程Reactor模型 , 多线程Reactor模型 , 主从Reactor模型 。
通常来说 , 主从Reactor模型是最健壮的 , Tomcat和Netty都是使用这种 , 但是 Redis是使用单线程Reactor模型。
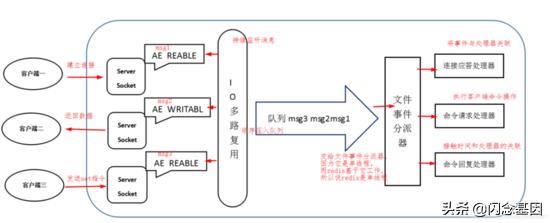 文章插图
文章插图
上图描述了Redis工作的线程模型 , 模拟了服务端处理客户端命令的过程:
- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字 , 即将套接字的fd注册到epoll上 , 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时 , 与操作相对应的文件事件就会产生 。
- 尽管多个文件事件可能会并发地出现 , 但I/O多路复用程序总是会将所有产生事件的套接字都推到一个队列里面 , 然后通过这个队列 , 以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字 。
- 此时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件 。 文件事件处理器以单线程方式运行 , 这就是之前一直提到的Redis线程模型中 , 效率很高的那个单线程 。
3.3. 分析为什么不怕Reactor单线程模型的弊端?
我们回顾之前的文章 , Reactor单线程模型的最大缺点在于:Acceptor和Handlers都共用一个线程 , 只要某个环节发生阻塞 , 就会阻塞所有 。 整个尤其是Handlers是执行业务方法的 , 最容易发生阻塞 , 像Tomcat就默认使用200容量大线程池来执行 。 那Redis为什么就不怕呢?
原因就在于Redis作为内存数据库 , 它的Handlers是可预知的 , 不会出现像Tomcat那样的自定义业务方法 。 不过也建议不要在Reids中执行要占用大量时间的命令 。
总结:Redis单线程效率高的原因
- 纯内存访问:数据存放在内存中 , 内存的响应时间大约是100纳秒 , 这是Redis每秒万亿级别访问的重要基础 。
- 非阻塞I/O:Redis采用epoll做为I/O多路复用技术的实现 , 再加上Redis自身的事件处理模型将epoll中的连接 , 读写 , 关闭都转换为了时间 , 不在I/O上浪费过多的时间 。
- 单线程避免了线程切换和竞态产生的消耗 。
4.1. 概念那么Redis的事务是为了处理什么情况?
假设 , 客户端A提交的命令有A1、A2和A3 这三条 , 客户端B提交的命令有B1、B2和B3 , 在进入服务端队列后的顺序实际上很大部分是随机 。 假设是:A1、B1、B3、A3、B2、A2 , 可客户端A期望自己提交的是按照顺序一起执行的 , 它就可以使用事务实现:B2、A1、A2、A3、B1、B3 , 客户端B的命令执行顺序还是随机的 , 但是客户端A的命令执行顺序就保证了 。
- 如何进行不确定度估算:模型为何不确定以及如何估计不确定性水平
- 一文讲透“进程、线程、协程”
- 电脑之间不能一概而论?AMD线程撕裂者3990X整机上手体验
- 3分钟短文:说说Laravel模型关联关系最单纯的“一对一”
- 使用 redis-py 储存地理位置数据
- 《深入理解Java虚拟机》:锁优化
- 自用:HMM隐马尔可夫模型学习笔记(2)-前向后向算法
- OpenAI推出数学推理证明模型,推理结果首次被数学家接受
- JVM 之java内存模型
- Google的神经网络表格处理模型TabNet介绍