多视图几何三维重建实战系列之R-MVSNet
作者:浩南
来源:公众号@3D视觉工坊
上期文章介绍了用于三维重建的深度学习框架MVSNet[1] , 这也是如今比较主流的深度估计的神经网络框架 。 框架的原理按照双目立体匹配框架步骤:匹配代价构造、匹配代价累积、深度估计和深度图优化四个步骤 。 使用过MVSNet的同学会发现 , MVSNet使用3D的卷积神经网络对聚合后的代价体进行正则化 , 防止在学习过程中 , 受到低概率的错误匹配影响 。
但使用三维卷积神经网络(U-Net[2]) , 会造成非常大的GPU消耗 , 使得我们在使用过程中 , 受到一定的限制 。 同时 , 因为该正则化的模块 , 导致普通GPU单卡下无法训练和测试较高分辨率的影像集 , 也会影响深度估计范围和估计精度 。
 文章插图
文章插图
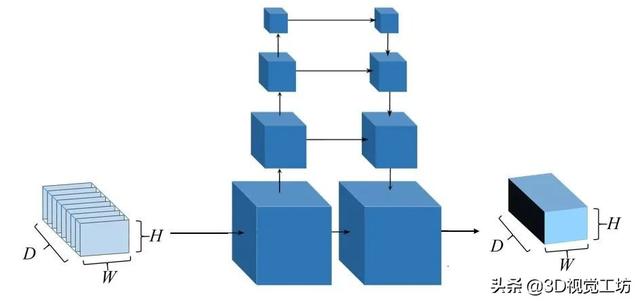
图1 MVSNet代价体正则化
针对该问题 , 本篇文章将介绍CVPR2019的R-MVSNet[3] , 并简单根据代码 , 介绍运行步骤和对应的问题 。
1、R-MVSNet
R-MVSNet同样是香港科技大学姚遥等人在CVPR2019上提出的一种深度学习框架 , 它在MVSNet的基础上 , 解决了正则化过程中GPU消耗大、无法估计较大场景和高分辨率照片的问题 。 R-MVSNet的网络结构如下:
 文章插图
文章插图
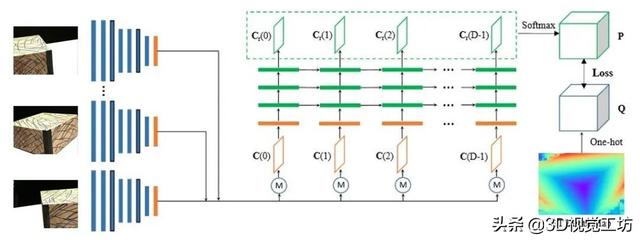
图2 R-MVSNet网络结构
和MVSNet的结构类似 , 给定一个参考影像和与其类似的原始影像 , 通过2D CNN网络进行深度特征的提取 , 每张影像输出32通道的特征图 。 在参考平面扫描算法[4]构造参考影像的匹配代价 。 形成一个特征体 , 然后利用GRU结构代替3DCNN对特征体进行深度正则化 , 防止过拟合现象 , 输出表示沿深度方向不同像素所在深度概率的概率体 , 最后利用“赢者通吃”原则 , 输出深度图 。 R-MVSNet和MVSNet一样 , 隶属于监督学习的范畴 。
深度特征提取 , 匹配代价构造的步骤和MVSNet完全一致 , 其创新点在于利用循环神经网络中的GRU结构对代价体进行正则化 , 有效降低了3D CNN正则化带来的巨大GPU消耗 。 以下就该创新做重点阐释 。
1.1、回顾MVSNet中的正则化步骤
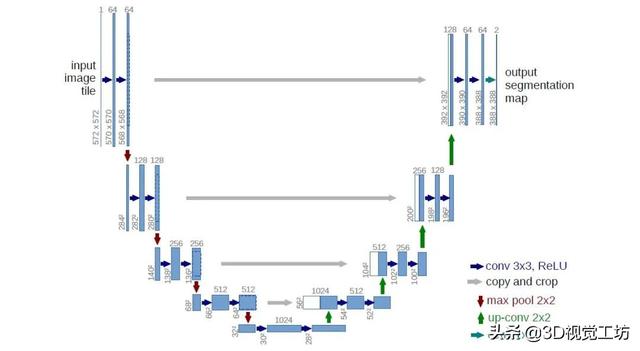
MVSNet中正则化使用的3D CNN网络参考的是U-Net(图3) , U-Net可以理解为 , 先按照左边的部分进行下采样 , 以降低图片的分辨率 , 得到大尺度的信息 , 之后 , 结合不同尺度的图像信息 , 进行上采样(如灰色所示) 。
 文章插图
文章插图
图3 U-Net结构
MVSNet使用U-Net结构进行正则化时 , 内存消耗会随着模型增大而立方级别的增大 。 所以 , MVSNets网络虽然深度估计效率高 , 但在三维卷积神经网络正则化过程中GPU资源消耗过大(图4), 造成MVSNet可以估计的深度范围较小 , 影响深度估计的精度 。 传统方法的优化方法只对当前深度那一层信息进行处理 , 提取深度 , 而图4 – c)中 , 3DCNN则是对全体进行代价体正则化 , 面临效率和成本问题 。
 文章插图
文章插图
a) 传统方法的代价累积消耗 b) RNN代价体正则化消耗 c) 3D CNN 代价体正则化消耗
图4 代价体处理消耗示意图
1.2、R-MVSNet中的GRU优化
R-MVSNet网络提出的替代方式是将代价体分割成沿着深度方向拼接而成的多个代价图 , 直接对单个代价图进行过滤 。 同时考虑到单个代价图缺失上下文信息 , 采用循环神经网络(GRU结构)过滤整个代价体 , 使得保证深度图估计高效率的同时 , 降低了GPU消耗 。
堆栈式GRU结构 。 GRU(Gate-Recurrent Unit)是一种循环神经网络的结构 , 和LSTM一样 , 设有状态传递和“遗忘”机制 , 便于逐序处理数据 , 按照该思路 , 引入GRU结构(图5-a) , 对代价图按照深度方向逐序过滤 。 定义[]为向量相连作为共同输入输入 , *为矩阵相乘 。
- 酷派发百元机:展讯芯片+水滴屏+双摄,网友:为时已晚
- 京东|京东探索稀疏三维空间点云Global Context学习方法获认可
- 山东安步几何汽车体验中心开业庆典落幕
- “侍”在必得 VAIO FH14笔记本抢先体验
- 创业邦|滴滴旗下橙心优选胜算几何?,抢跑社区团购
- 科技刀|ArchiMate视图指南(6):信息结构视图和服务实现视图
- 三维空间|数学家证实四维空间存在,如果人类成功进入后,能改变什么?
- 三维空间|超大质量黑洞被捕捉!质量远远超出太阳的10亿倍,为何如此之大?
- 三维空间|如果人类进入四维空间,你能想象会发生什么?科学家:怀疑人生!
- 经济观察报|几何级数增长不再?,蚂蚁上市突搁浅:拆解联合贷款谜团