「爬虫四步走」手把手教你使用Python抓取并存储网页数据
 文章插图
文章插图
爬虫是Python的一个重要的应用 , 使用Python爬虫我们可以轻松的从互联网中抓取我们想要的数据 , 本文将基于爬取B站视频热搜榜单数据并存储为例 , 详细介绍Python爬虫的基本流程 。 如果你还在入门爬虫阶段或者不清楚爬虫的具体工作流程 , 那么应该仔细阅读本文!
第一步:尝试请求
首先进入b站首页 , 点击排行榜并复制链接
现在启动Jupyter notebook , 并运行以下代码
import requestsurl = ''res = requests.get('url')print(res.status_code)#200在上面的代码中 , 我们完成了下面三件事
- 导入
requests
- 使用
get方法构造请求
- 使用
status_code获取网页状态码
200 , 表示服务器正常响应 , 这意味着我们可以继续进行 。第二步:解析页面
在上一步我们通过requests向网站请求数据后 , 成功得到一个包含服务器资源的Response对象 , 现在我们可以使用
.text来查看其内容 文章插图
文章插图可以看到返回一个字符串 , 里面有我们需要的热榜视频数据 , 但是直接从字符串中提取内容是比较复杂且低效的 , 因此我们需要对其进行解析 , 将字符串转换为网页结构化数据 , 这样可以很方便地查找HTML标签以及其中的属性和内容 。
在Python中解析网页的方法有很多 , 可以使用
正则表达式 , 也可以使用BeautifulSoup、pyquery或lxml , 本文将基于BeautifulSoup进行讲解.Beautiful Soup是一个可以从HTML或XML文件中提取数据的第三方库.安装也很简单 , 使用
pip install bs4安装即可 , 下面让我们用一个简单的例子说明它是怎样工作的from bs4 import BeautifulSouppage = requests.get(url)soup = BeautifulSoup(page.content, 'html.parser')title = soup.title.textprint(title)# 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili在上面的代码中 , 我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换为一个BeautifulSoup对象 , 注意在使用时需要制定一个解析器 , 这里使用的是html.parser 。接着就可以获取其中的某个结构化元素及其属性 , 比如使用
soup.title.text获取页面标题 , 同样可以使用soup.body、soup.p等获取任意需要的元素 。第三步:提取内容
在上面两步中 , 我们分别使用requests向网页请求数据并使用bs4解析页面 , 现在来到最关键的步骤:如何从解析完的页面中提取需要的内容 。
在Beautiful Soup中 , 我们可以使用
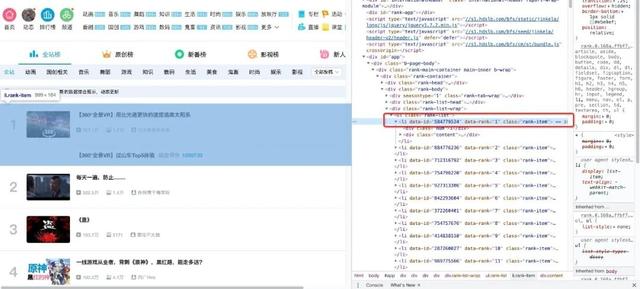
find/find_all来定位元素 , 但我更习惯使用CSS选择器.select , 因为可以像使用CSS选择元素一样向下访问DOM树 。现在我们用代码讲解如何从解析完的页面中提取B站热榜的数据 , 首先我们需要找到存储数据的标签 , 在榜单页面按下F12并按照下图指示找到
 文章插图
文章插图可以看到每一个视频信息都被包在
class="rank-item"的li标签下 , 那么代码就可以这样写all_products = products = soup.select('li.rank-item')for product in products:rank = product.select('div.num')[0].textname = product.select('div.info > a')[0].text.stripplay = product.select('span.data-box')[0].textcomment = product.select('span.data-box')[1].textup = product.select('span.data-box')[2].texturl = product.select('div.info > a')[0].attrs['href']all_products.append({"视频排名":rank,"视频名": name,"播放量": play,"弹幕量": comment,"up主": up,"视频链接": url})
- Nginx服务器屏蔽与禁止屏蔽网络爬虫的方法
- 手把手教你挑选大大大大屏的投影仪
- 手把手教你用python编程写一款自己的音乐下载器
- Python爬虫入门第一课:如何解析网页
- 开启Scrapy爬虫之路!听说你scrapy都不会用?
- 安全漏洞大揭秘:手把手教你轻松防止SQL注入
- 专栏丨当代“爬虫”现状
- 手把手教你AspNetCore WebApi:Serilog
- 今天才知道,原来手机就能给视频添加字幕,手把手教会你
- 爬虫程序优化要点—附Python爬虫视频教程