大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率( 二 )
高效的模型请求为了解决传输的性能瓶颈 , 研究人员在学习器与行为器间引入了分布式透传缓存机制 , 其中行为器使用TensorFlow进行优化 , 并利用Reverb作为后端 。
缓存原件的主要目的在于平衡庞大数量行为器的请求和学习器的任务 。 这些缓存原件不仅大幅度减小了学习器提供模型请求的压力 , 同时也将行为器的模型读取延时缩短约了4倍 , 使得算法、特别是PPO这样的策略训练循环更加迅速 。
 文章插图
文章插图
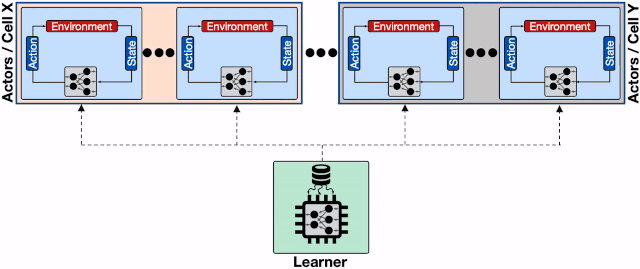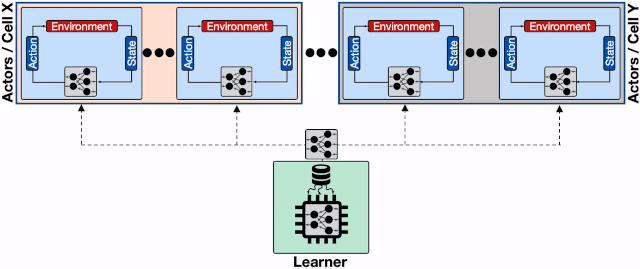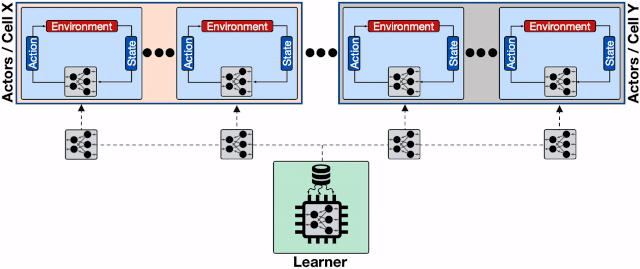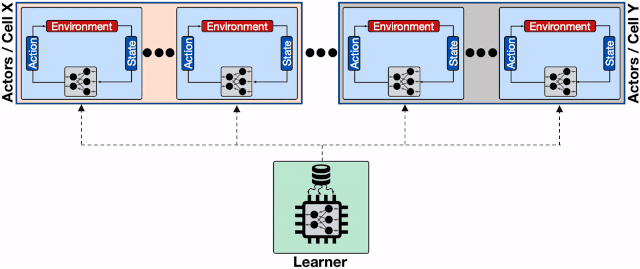
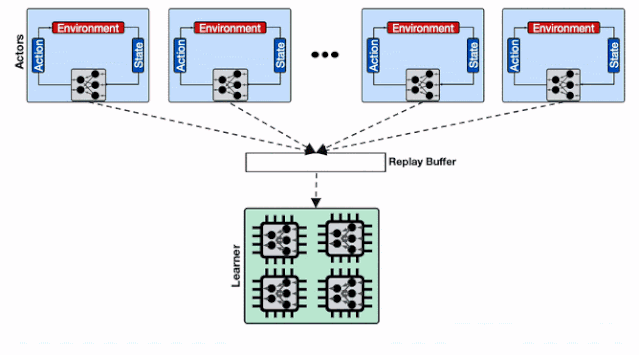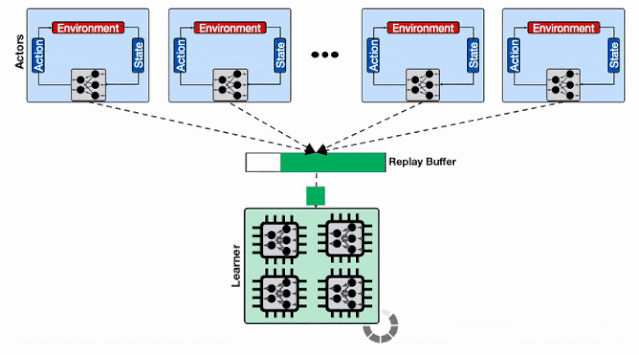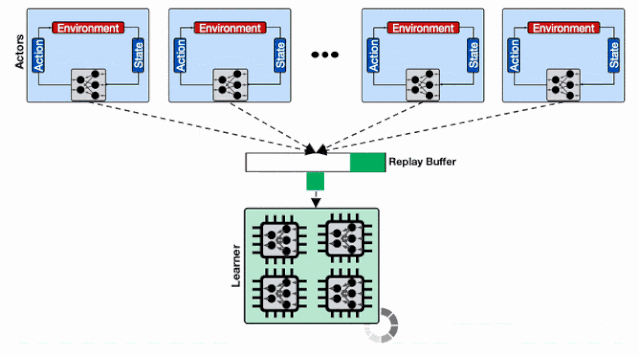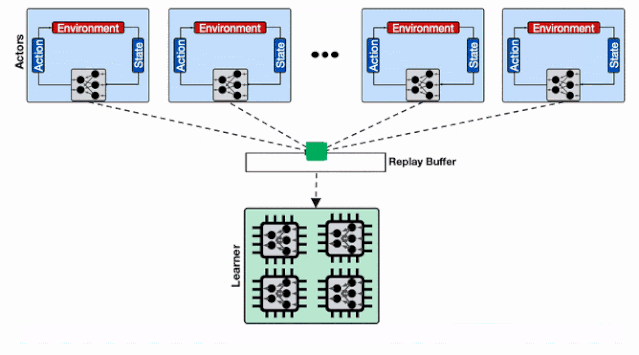
分布式强化学习系统的架构 。 每一个蓝色的行为器都需要像学习器请求模型 , 通信开销会增加整体的收敛时间;
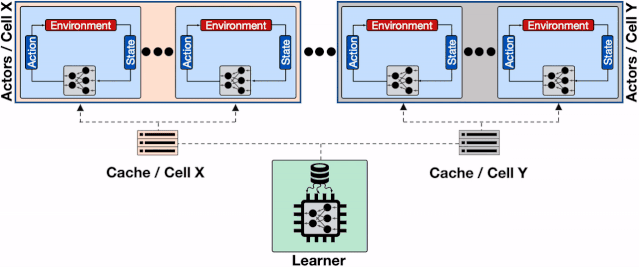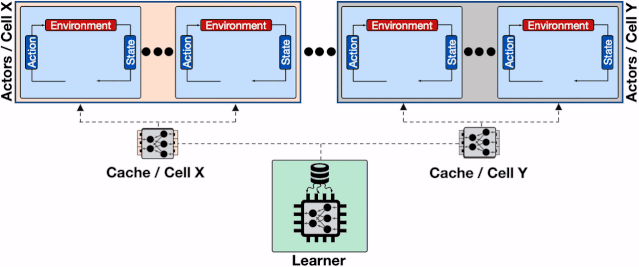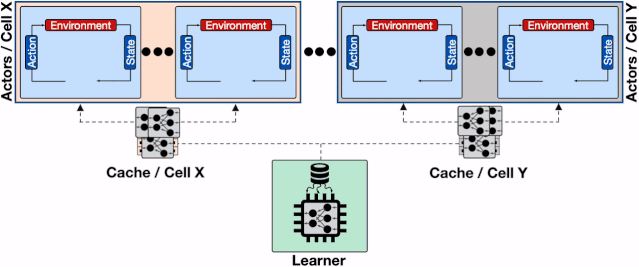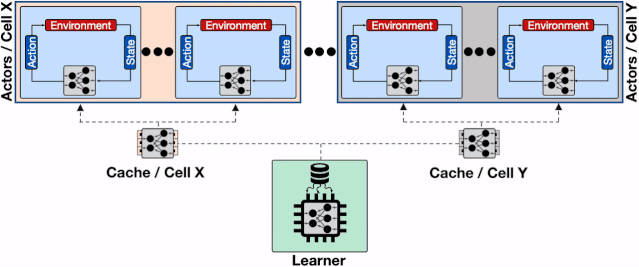 文章插图
文章插图
增加了透传缓存机制的分布式系统 , 行为器会从邻近的缓存中读取模型、不仅缓解了学习器的负载压力、同时减小了行为器读取模型的平均延时 。
高通量输入流程为了解决数据输入的性能瓶颈 , 研究人员使用了机器学习任务专用的数据存储系统Reverb 。 但仅仅使用单个Reverb回放缓存服务是不足以支撑大规模分布式强化学习系统的性能要求的 , 来自数千个行为器的数据写入效率会被大大拉低 。
 文章插图
文章插图
仅仅存在单个回放缓存时 , 数千个行为器的数据被拖慢 。 训练系统使用了多个计算核 , 那么仅仅使用一个数据回放缓存是不足以支撑高性能计算的 。
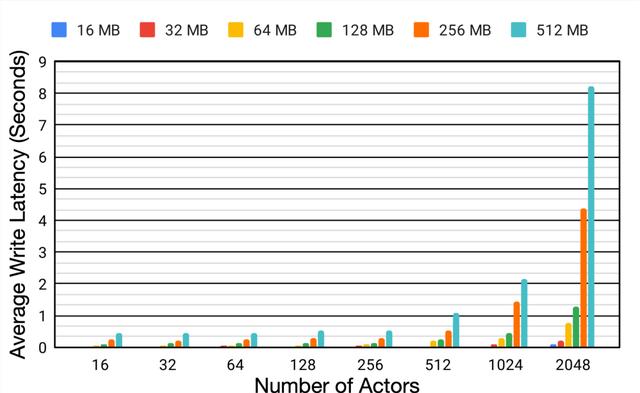
为了更好地理解分布式系统中回放缓存 (replay buffer) 的性能 , 研究人员利用不同的模型大小和行为器数量在相同的设备上进行了比较试验 。
实验表明 , 随着行为器数量从16增长到2048 , 模型大小从16M增加到512M的过程中 , 平均延时增加了6.2倍和18.9倍 , 这种写入数据的延迟大幅度降低了行为器从环境中收集数据的效率 , 并造成了整体训练过程的低效 。
 文章插图
文章插图
单个Reverb缓冲器的性能变化
为了解决这一问题 , 研究人员利用了Reverb的分片能力来增加行为器和学习器以及回放缓存服务间的数据通量 。 分片功能平衡了数量巨大的行为器与多个缓存器间的负载 , 避免了单个缓存器造成的瓶颈 , 最小化了写延时 。 这种方式使得Menger可以在不同Borg计算单元上大规模地进行拓展 。
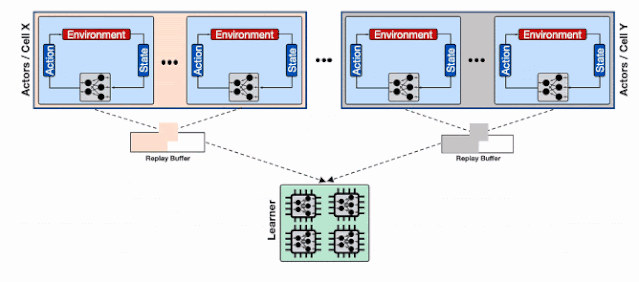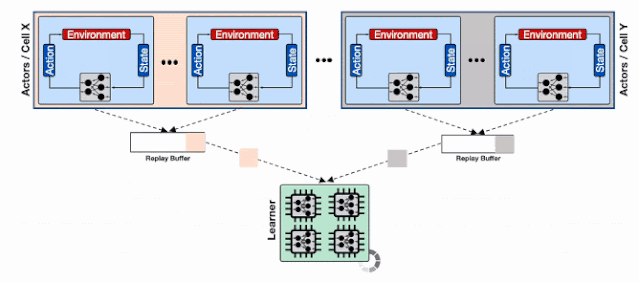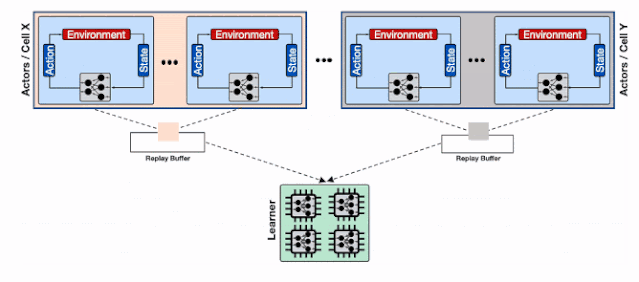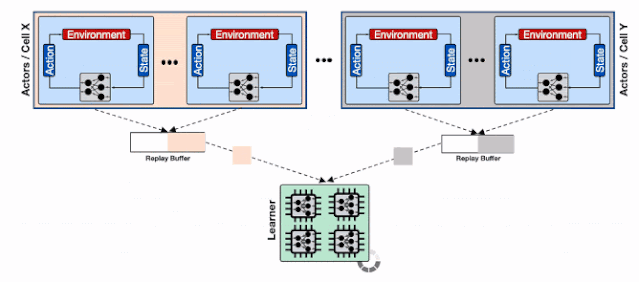 文章插图
文章插图
基于分片重放缓存的分布式强化学习系统 , 每个缓存收集来自多个学习器的数据 , 为输入学习器的加速硬件提供了更高的数据通量 。
案例分析:芯片布局任务研究人员将这套算法应用于芯片设计中布局任务的优化中 , 实验表明针对实际任务这种方法将训练时间从8.6小时减低为一个小时 。 虽然Menger在TPU上进行了优化 , 但同时作者认为在GPUs上也会有相似地性能提升 。
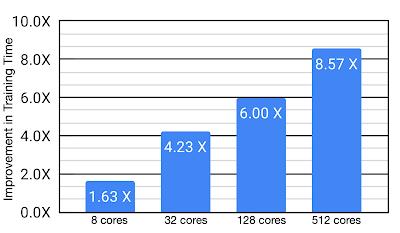 文章插图
文章插图
这种框架为大规模强化学习提供了有益的方向 , 虽然仅仅在芯片设计的位置布局上成功应用 , 但这也从一个侧面反映出强化学习与这套系统在各个领域较好的应用前景 。 未来如果想利用成百上千个智能体进行任务训练提升训练性能 , 这套分布式高速训练系统是不错的选择 。
ref:
ChipPlace:
Borg:
Reverb:
 文章插图
文章插图
 文章插图
文章插图
- 分布式数据库Hbase入门介绍
- NET Core微服务之路:再谈分布式系统中一致性问题分析
- 分布式SQL数据库新的演变方向
- 韩大规模弃用5G!三星暗示华为成唯一救星:诺基亚和爱立信懵了
- 怎么理解分布式、高并发、多线程
- 秀出天际!阿里新创988页爆款分布式进阶学习笔记,简直细节
- 好程序员大数据培训分享Hadoop分布式集群
- 5G无线知识,从“大规模MIMO”开始
- iphone12|iPhone 12大规模翻车,苹果这次有点过分了
- |iPhone 12大规模翻车,不但没信号,它还绿了