机器学习之Hyperparameter Tuning
【机器学习之Hyperparameter Tuning】机器学习时模型训练非常简单 , 将数据分成训练集(training set)和测试集(testing set) , 用training set训练模型 , 然后将模型应用到testing set上评估模型的好坏 。
怎么优化模型 , 使得模型更加稳定有效呢?
方法是超参数优化(Hyperparameter tuning) 。 比如我们有3个hyperparameter , 每个Hyperparameter可以设置3个数值 , 这样我们就可以得到3X3X3=27个组合 , 然后用相同的训练集分别训练27个模型 , 将这27个模型分别应用在testing set上 , 就可以比较出那组Hyperparameter组合比较好 。
但是 , 当我们把模型应用到真实场景的时候 , 往往会发现模型效果比在testing set上差很多 。 为什么会出现这样的问题呢?原因是我们调整参数的时候都是用的一套testing set , 所以我们选择的参数只是适应这个特殊的数据集 。 这时候validation set就该上场了!
这次数据就不能只分为训练集和测试集了 , 而是在训练集和测试集之外再分出验证集(validation set) 。 在Hyperparameter tuning时将训练的模型应用到validation set上挑选出最好的Hyperparameter 组合 , 然后将最好组合的模型应用到testing set上 , 得到模型的最终效果 。
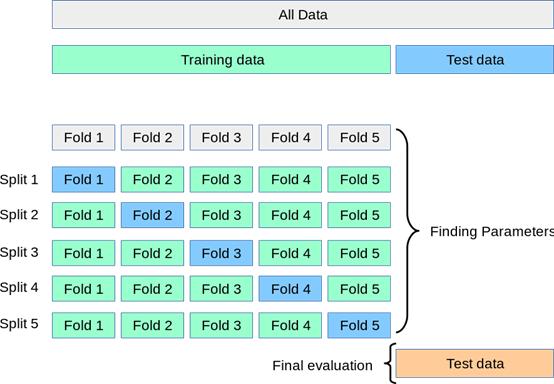
这时候另外一个问题出现了 , 由于我们这次将模型应用在一个固定validation set上 , 而validation set 有可能太大或者太小 , 这次得到的模型很有可能不是模型的最优解 , 怎么办呢?我们可以用k fold cross validation来解决这个问题 。 如下图 , 首先将数据分为训练集和测试集 , 训练集再分为k份(例子中是5份) , 模型训练的时候用其中的k-1份作为训练集 , 用剩下的一份数据作为验证集 , 这样训练k个模型 , 将k次建模结果的平均数作为这个Hyperparameter组合的最终结果 , 这样得到模型的最优解 。
 文章插图
文章插图
- 我们是后浪|机器人,“乖乖听话”
- 抢险探测应急救援消防灭火 中国智能特种机器人都在这
- 宁夏举办第35届青少年科技创新大赛机器人竞赛项目
- 擎朗送餐机器人在2020国际智能机器人博览会打造智慧商业模式
- 普渡机器人精彩亮相2020中国(佛山)国际智能机器人博览会
- 从Bengio演讲发散开来:探讨逻辑推理与机器学习
- 辅助行走的老人智能搀扶机器人设计
- 用尽全身力气不想加班的机器人,这大概是程序员最后的倔强,哈哈
- 石头扫地机器人 T7 Pro 使用报告:轻松实现双目避障
- 趋势(六):人工智能和机器人将成为法律系统的主要进入点