引擎级多模|SequoiaDB让研发和DBA和谐共处
很多朋友可能是通过2011年成立的PostgreSQL中国社区认识我的 , 今年 , 我加入SequoiaDB巨杉数据库 , 期待在分布式数据库领域 , 继续与大家探讨无尽的技术话题 。 周日 , 转发了公司公众号文章《SequoiaDB SQL查询语句执行过程》后 , 不少同行都问我SequoiaDB是不是就是基于一个分布式的存储 , 并对接上层的各类数据库及存储操作协议 , 形成兼容架构 , 这是不是就是巨杉的核心特色 。
在此 , 我先进行回答:「首先 , SequoiaDB底层是一个完整的原生分布式数据库 , 绝不仅仅是一个分布式存储;其次 , 支持多种引擎只是特色之一 , 惊喜绝对不仅是这一点 。 」因此 , 借着自己在公司公众号发表的首篇文章 , 给关心这些问题的朋友进行解答 。
我们先定义一下数据库的直接用户是谁 , 那当然是我们的研发人员及DBA 。 这往往是两个互相紧密合作 , 同时又在某些环节互相制约的角色 。 研发人员希望快速敏捷地开发程序 , 用越简单的方式开发越好 , 不希望受到数据库底层各种条件限制的束缚 。 在近年来兴起的微服务架构中 , 更是鼓励独立的开发团队管理并选择自己所需要的数据库 。 微服务中 , 为了保持各个服务之间的松耦合 , 每个服务都有自己的数据库 。 针对不同的业务需求 , 研发人员可以选择不同的数据库类型 , 有的使用关系型数据库 , 如:MySQL、PostgreSQL , 有的使用非关系型数据库 , 如:MongoDB 。 每个客户项目中 , 为了完成业务流程 , 往往牵涉到多个服务 , 因此在多个服务之间进行数据处理往往充满挑战 。 而DBA更将会由于陷入到多个数据库的交叉管理 , 导致管理难度急速增加 , 往往由最初双方共同解决问题 , 到最后是大家剑拔弩张 。
以一个金融在线交易的业务为例 , 通常包括各种信息 , 例如:账户查询、业务办理、账目调整 , 过程中需要验证交易信息 , 同时需要写入交易历史 。 传统单体应用中 , 只需要使用一次事务交易就可以检查账号的信息 , 同时基于事务完成交易历史数据的写入 。 但在微服务架构下 , 由于各个业务存放在不同的数据库中 , 考虑到业务需求不 , 研发团队可能认为账户信息更适合使用MySQL处理 , 而历史数据由于其海量膨胀及结构需要灵活变化的特性可能选择MongoDB引擎 。 导致业务处理时 , 需要通过各服务提供的API进行数据交换 , 给程序设计复杂度及系统处理性能都带来挑战 , 如下图“方案1” 。 另一个方案 , 是通过ETL或日志复制等方式 , 将某个库中的业务数据同步到另一数据库 , 然后进行使用 , 带来的问题是数据不一致 , 同时数据存在多分冗余 , 耗费磁盘空间 , 如下图“方案2” 。
 文章插图
文章插图
市场上云计算厂商提供了支持不同协议的云数据库服务 , 受到不少用户青睐 , 特别是使得DBA可以减少很多安装部署及维护不同数据库架构的工作 。 但一方面 , 即使是使用云数据库 , 每个不同的数据库引擎之间 , 数据依然是各个孤岛 , 与上图一样方案1、方案2中的数据交互问题没有解决 。 如果需要进一步进行“数据中台”整合 , 还需要单独的ETL操作汇总到单独的数据仓库 。 另一方面 , 从平台的角度 , 用户必须使用公共云 , 或在企业中花费巨资 , 部署绑定某个云厂商的私有云“全家桶”方案 , 才可获得云数据库基于资源池化的存储计算分离 , 及多引擎支持能力 。
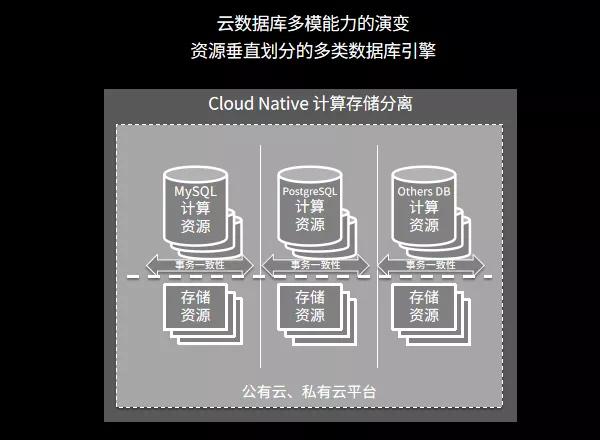 文章插图
文章插图
巨杉数据库提供引擎级多模能力 , 在SequoiaDB的原生分布式数据库基础上 , 同时支持多种数据库 , 现有的v3.4版本已经支持:MySQL、PostgreSQL、Spark、PosixFS兼容协议及原生SDB JSON API , 新的v5.0版本更将支持MariaDB、MongoDB、S3兼容协议 , 也欢迎关注并报名参加我们10月22日的SequoiaDB v5.0发布会 。
- IOS|安卓,有了这五个引擎,直接起飞
- 在弃用11年后微软终于允许IT管理员禁用IE中的JScript脚本引擎
- 数据|温昱:搜索引擎数据痕迹处理中权利义务关系之反思
- 搜索引擎|拜登任命脸书和苹果高管担任白宫职务,推动大型科技公司渗透过渡
- 搜索引擎|你真的会用搜索引擎吗?别再输入口水话,3秒教你搜出精准答案
- 晶报|“湾区引擎”蓄势待发“科技福田”乘风破浪
- 数码实验室|敬请关注:华为搜索引擎花瓣搜索更新至版本10.1.6.305
- IT之家|华为详解凤凰引擎技术:手机实现实时光线追踪
- 新华社新闻|可令赴火星时间减半,美企提出新型核引擎设想
- 科技生活快讯|外媒:苹果正在开发自己的搜索引擎技术