文章图片
文章图片

文章图片
文章图片

文章图片
在大多数人印象中 , AR眼镜的主要特征是提供虚实融合的视觉辅助效果 。 实际上 , 与同样基于虚拟技术的VR相比 , AR不仅仅能够看到真实环境 , 它的应用场景和VR也不同 , 因为它可以通过一系列智慧的功能来辅助日常生活、工作和学习 。
此前Meta就曾提出 , AR眼镜将采用支持场景感知的AI算法 , 推算使用者在场景中需要获取的信息 , 以及需要执行的下一步动作 , 接着使用者可以用EMG腕带来进行确认 。 的确 , 穿戴式AR眼镜与智能AI助手结合是必然的结果 , 市面上大多数非AR的智能眼镜已经配备语音助手 , 相比之下AR眼镜需要的不只是语音助手 , 它应该可以通过摄像头来提供智能的视觉辅助 , 就像是科幻电影描述的那样 。
近年来 , 计算机视觉技术已经得到长足发展 , 相关算法可以识别不同类型的物体 , 或是用于手势识别、人脸识别等场景 。 不过 , 目前计算机视觉算法面临的最大难题是 , 它主要是基于第三人称视角的照片和视频训练的 , 因此AI相当于以旁观者的角度去识别周围环境和活动 , 如果将它应用于家用机器人或AR眼镜 , 则需要识别第一人称图像 , 这对基于第三人称数据训练的AI并不友好 。
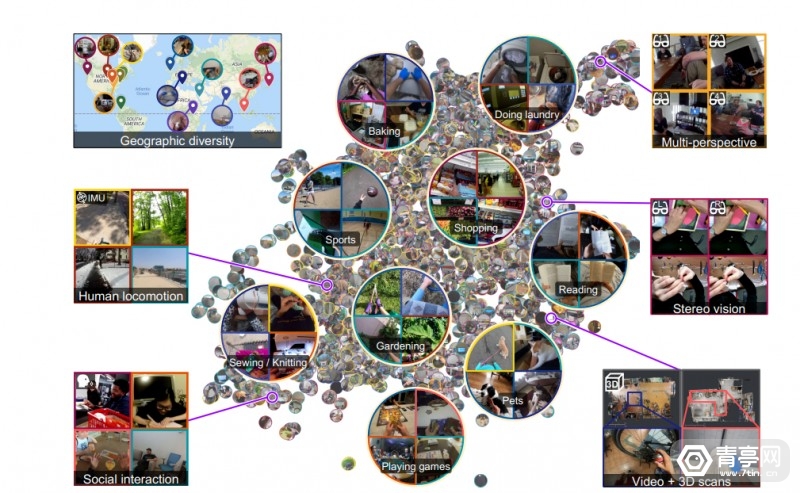
为了解决上述问题 , Meta近期开源了市面上最大的第一人称视频数据集Ego4D , 视频时长累计3205小时 , 号称是其他同类数据集规模的20多倍 。 据悉 , 该数据集是Meta与全球13所大学合作的成果 , 共耗时2年时间完成 。 另外 , Ego4D数据基于室内和室外场景 , 来源也分布在世界多个国家 , 比如:自沙特阿拉伯、东京、洛杉矶和哥伦比亚等等 。
为何收集第一人称视频
收集了这么多第一人称视角的视频 , 它和第三人称视频有什么区别呢?简单来讲 , 就像是在过山车上看景色 , 和从地面看过山车之间的区别 。
人的大脑可以轻易将第一人称和第三人称视角联系起来 , 而现有的AI技术不支持这样灵活的分析能力 , 因此如果让计算机视觉算法理解过山车上的景色 , 它可能并不能看懂 , 因为训练算法的数据一般是地面上拍摄的第三人称视频 。
AI科研人员Kristen Grauman表示:为了让AI像人一样与周围的环境交互 , 它需要具备第一人称感知能力 , 像人眼一样感知实时运动、交互和多感官视觉 。
而和许多视频数据不同 , Ego4D视频通过头戴摄像头来拍摄 , 因此可以模拟第一人称视角 , 而且它们是一系列动态的活动 , 而不只是一张一张图片 。 因此 , Ego4D的出现有望为第一人称计算机视觉打开新的场景 , 用于穿戴式摄像头、家用机器人助手等设备 , 这些设备将通过第一人称摄像头来理解周围的环境 。
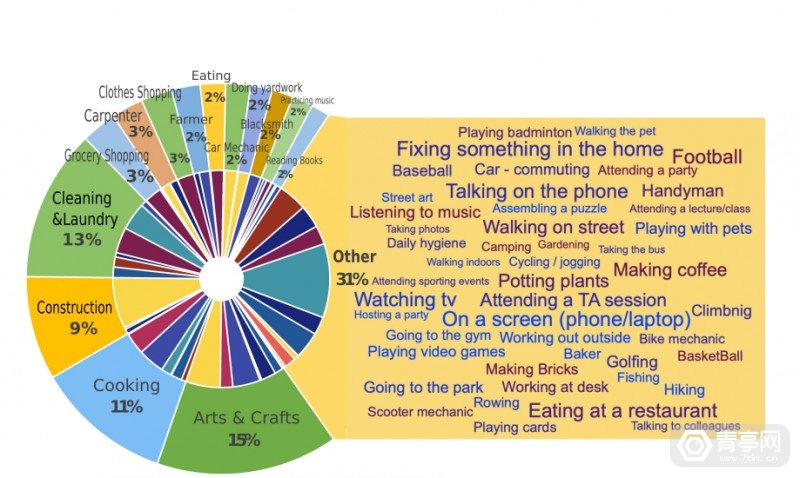
Ego4D数据收集参与者的职业
牛津大学教授Andrew Zisserman表示:在未来几年 , Ego4D数据集有望成为计算机视觉发展的驱动力 , 它会帮助计算机视觉算法以第一人称理解事件和活动 , 分析时间背景等 。
为AR眼镜公开采集数据
值得注意的是 , 利用图像、语音数据来分析用户周边环境 , 可能会带来严重的隐私争议 , 尤其是Meta推出的Stories拍照眼镜 , 很可能会被看作是移动的监控 。
Ego4D视频数据包含的活动内容
Meta明确指出 , 这些数据是由合作学校的855人录制的 , 他们并非Meta员工 , 使用的设备则是GoPro和拍照眼镜 。
而为了获得大家的信任 , Meta多次公开视频数据采集的详细信息和进度 , 在Meta公布的网站中 , 你可以直接查看Ego4D包含的视频数据 , 这些信息都是公开的 。
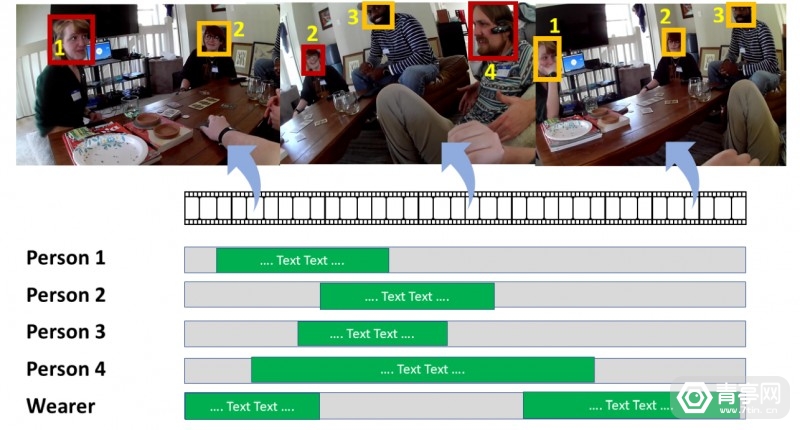
Meta还透露:Ego4D录制的视频来自于未经编排的日常活动 , 包括施工、购物、玩游戏、烘焙、撸猫/狗、社交等等 。 通过面部打码等方法 , 去除可识别的身份等信息后 , 大学才将这些视频数据提供给Meta 。 视频内容涉及环境、人手动作 , 以及和一百种不同的物品交互 。 除此之外 , FRL科研人员也利用Vuzix Blade AR眼镜 , 在预先设定的实验室场景中 , 收集了额外400小时的第一人称视频数据 。
- meta|产业加速发育,元宇宙尚待厘清边界
- meta|英国政府呼吁:不要活煮螃蟹、章鱼,原因是:它们能感觉到痛苦
- meta|围绕着元宇宙这一概念,究竟是未来还是炒作
- meta|如果进化论被推翻,人类还有哪些来源,神创论还会回归吗?
- meta|Apple新款手表全面剖析:耐用度提升、窄边框设计、屏幕大有用吗?
- meta|ofo退押新套路,推出“拉好友,退押金”功能,惹得全网众怒!
- meta|通往元宇宙的尽头,从卖课开始
- ai|预训练模型的在蛋白质结构建模中的应用及挑战
- meta|三分钟,让您了解热点名词“元宇宙”
- meta|德国科学家用玉米爆米花取代塑料泡沫,减少环境污染,还降低成本