Python|Python爬取2万条相亲数据!看看中国单身男女都在挑什么
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
文章图片
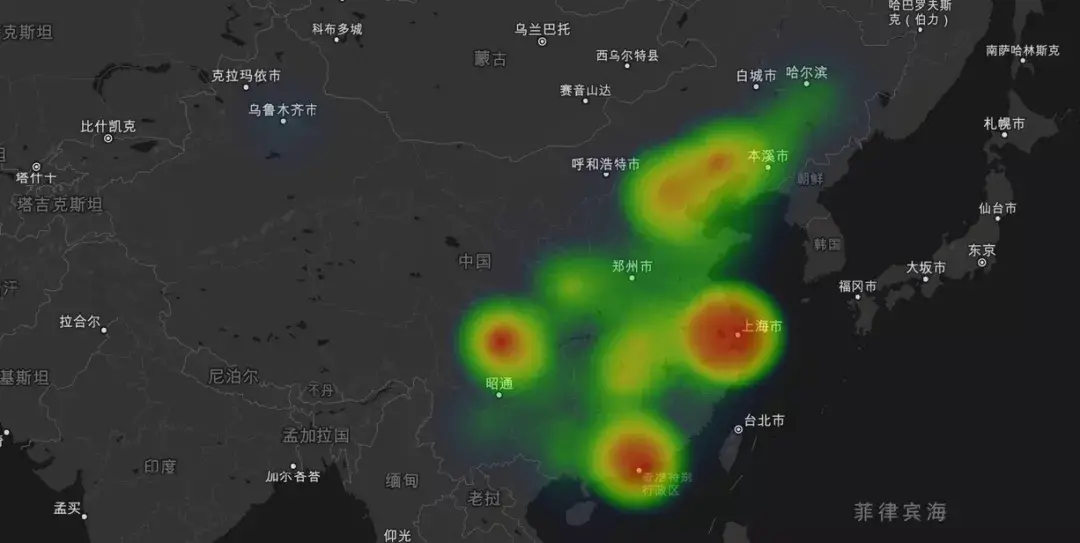
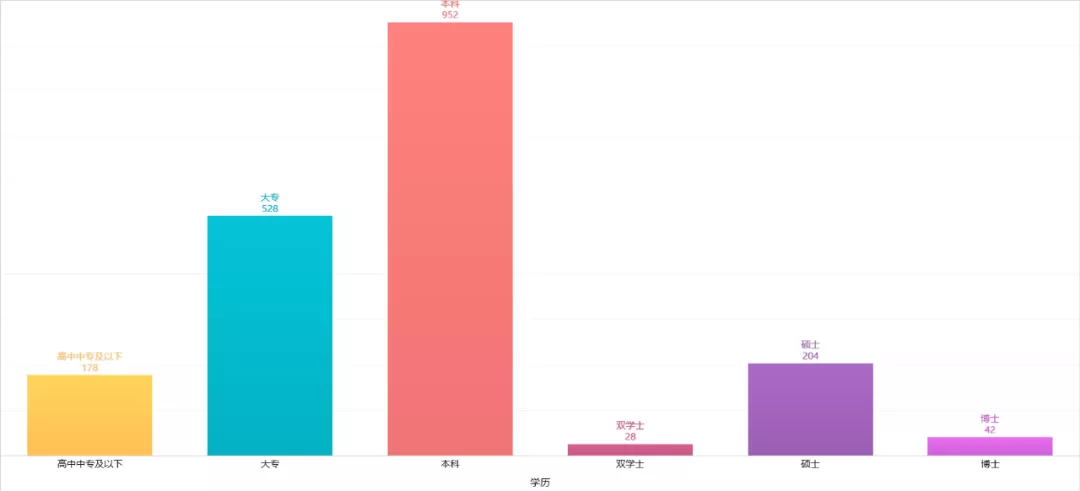
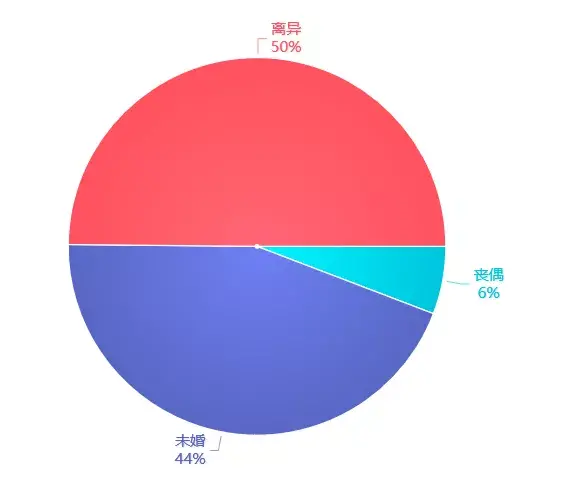
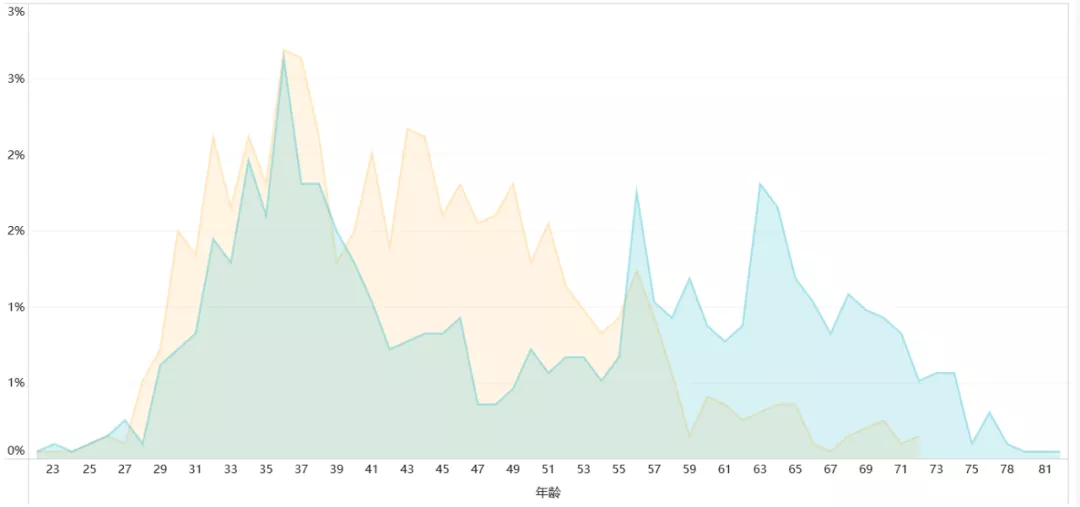
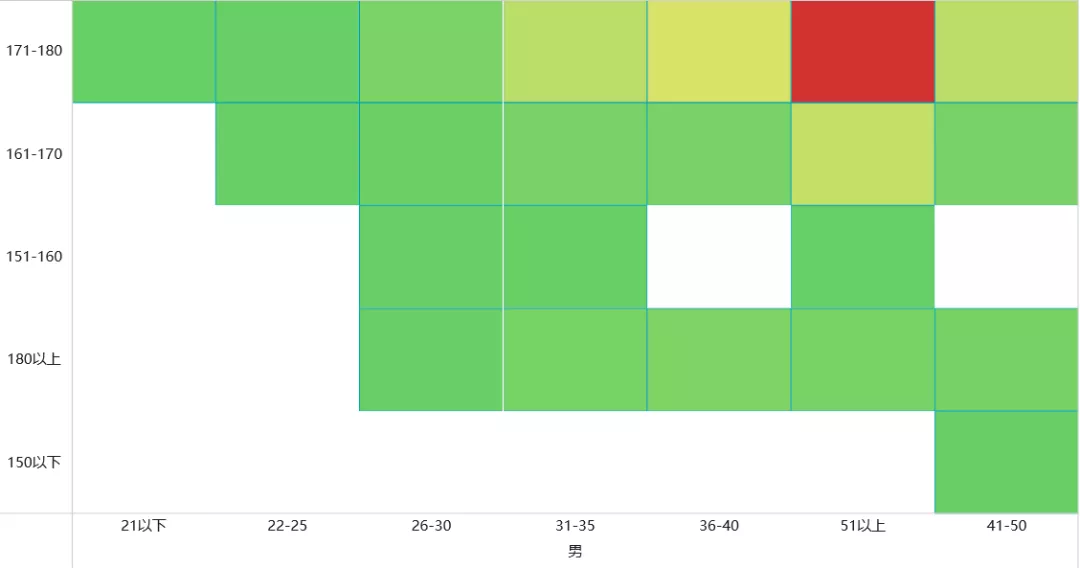
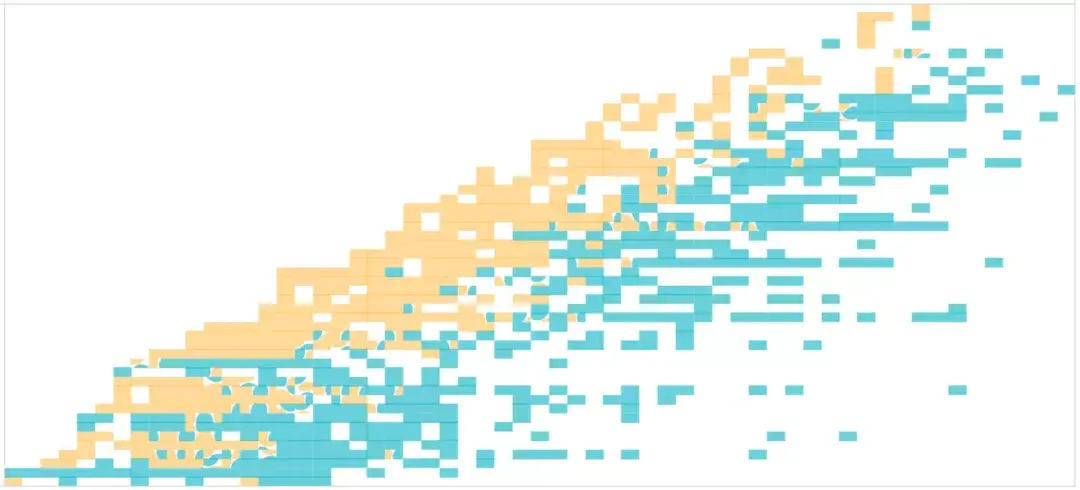
想必昨天的七夕节 , 一定是有人欢喜有人忧的一天 , 朋友圈里的晒照惹恼了我的一个程序员朋友 , 在昨晚怒爬2万条相亲网站数据 , 做了一次相亲男女画像!
话不多说 , 我们今天就以某相亲网站为例子 , 爬取搜索页面当中所有的用户信息 , 包括“用户ID”、“年龄”、“城市”、“学历”、“属相”等内容 , 使用的工具是爬虫工具pycharm 。
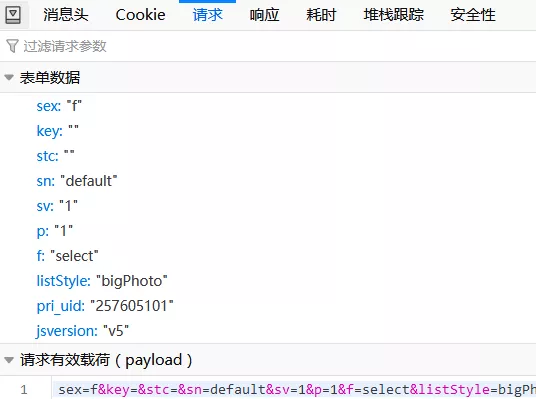
首先老规矩 , 爬虫之前我们先分析一些目标网页的构成 , 我们进入网站的搜索页面 , 摁下F12打开开发者工具 , 找到网页选项 , 看一下网页的Request URL和请求方式、user-agent等基本信息:
请求方式是post , 说明我们不用去源代码里找标签了 , 所有的数据都存放在网页的json文件当中 , 这倒是方便很多 , 我们直接通过链接直接获取API文件 , 不需要进行网页解析 , 点击HTR后点击“请求”就能看到表单数据了 。
很显然 , “sex”就是性别 , “f”是“female”的缩写 , “p”代表着页码 , 因为搜索页面一共有10页 , 所以我们需要构造一下完整的请求url 。
当网页页码发生变化的时候 , 我们发现url当中只有p值发生了变化 , 因此只需要改变p值就能构造对应的URL 。
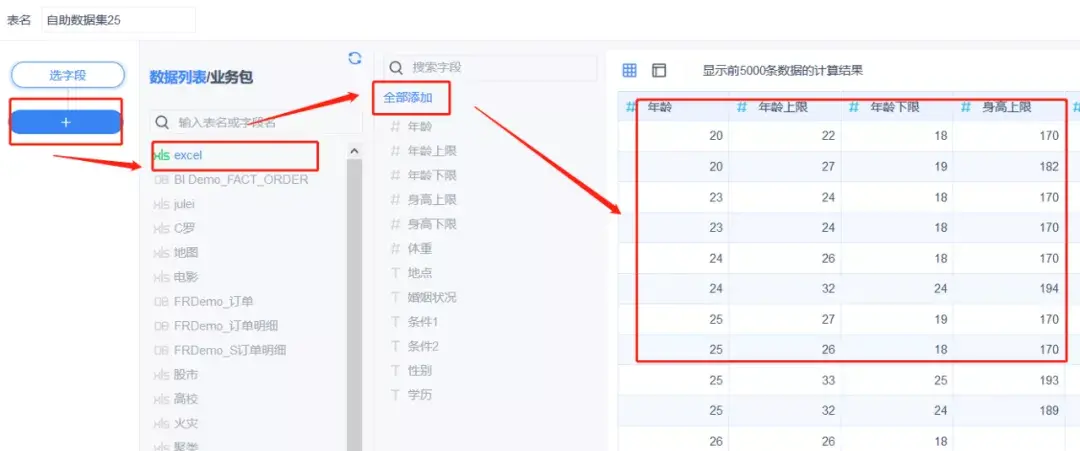
好了 , 网页的构成都分析好了 , 下一步就要开始在pycharm当中写爬虫了 , 通过上面的url , 我们可以获取到服务器返回的 json格式的用户信息 , 部分源代码如下:
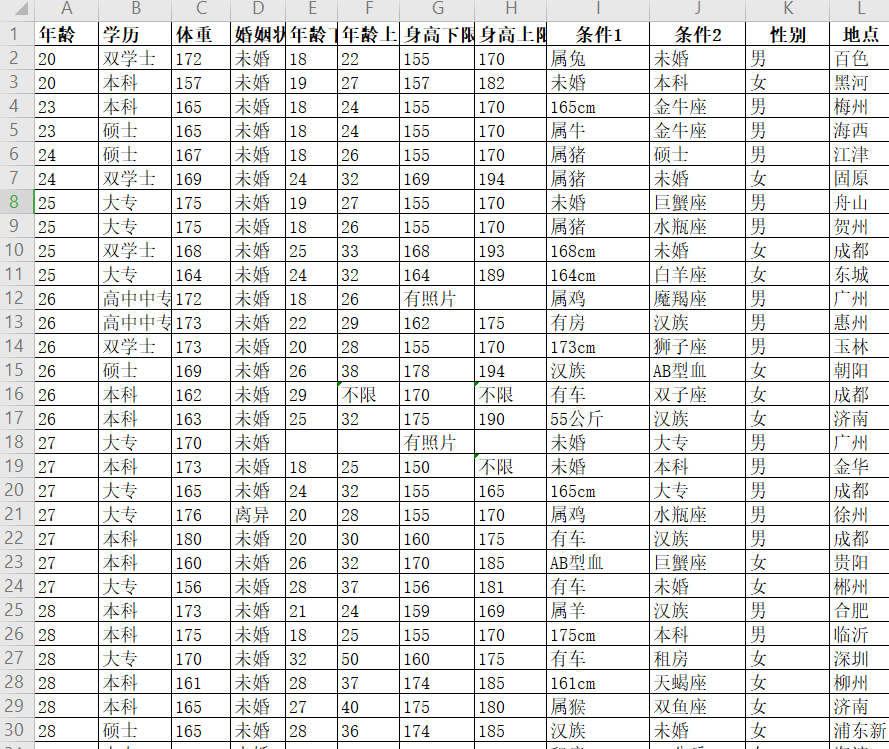
爬取的过程就不详细讲解了 , 因为这个网站还需要进行模拟登陆 , 所以需要登陆后将 cookie 放入爬虫的请求头中 , 这样便可正确访问数据 。 经过爬取后的数据清洗后如下:
- 韭菜花音乐|英国亚马逊删除2万条可,在证据显示“好评师”通过虚假评论获利后
- Python|python到底是强类型语言,还是弱类型语言?
- 产业气象站|Python数据可视化之Excel气泡图
- 青灯教育Python学院|学会这几招可以假装是Python高手,精华技巧
- 莫小帅|还在等什么,100本最前沿的Python编程电子书免费下载
- Python|老程序员:这是我见过最牛的代码,切勿模仿
- 产业气象站|崛起最快却是它,编程语言后浪:Java、Python热度不减
- Python|Julia 要凉?76%的 Julia 用户将 Python 作为首选替代语言
- 稚久|Python数据分析之Seaborn(回归分析绘图)
- Python|快速提高Python编程能力的一招鲜吃遍天