『算法』面试常见问题jvm的调优思路
文章图片

文章图片
前言:
上期我们说到了为了降低oom的几率 , 1.7开始将常量池放入堆中 , 并在1.8中移除了方法区 , 这期我们介绍下为什么放入堆中可以达到效果 , 这也和jvm调优相关
堆内存模型:
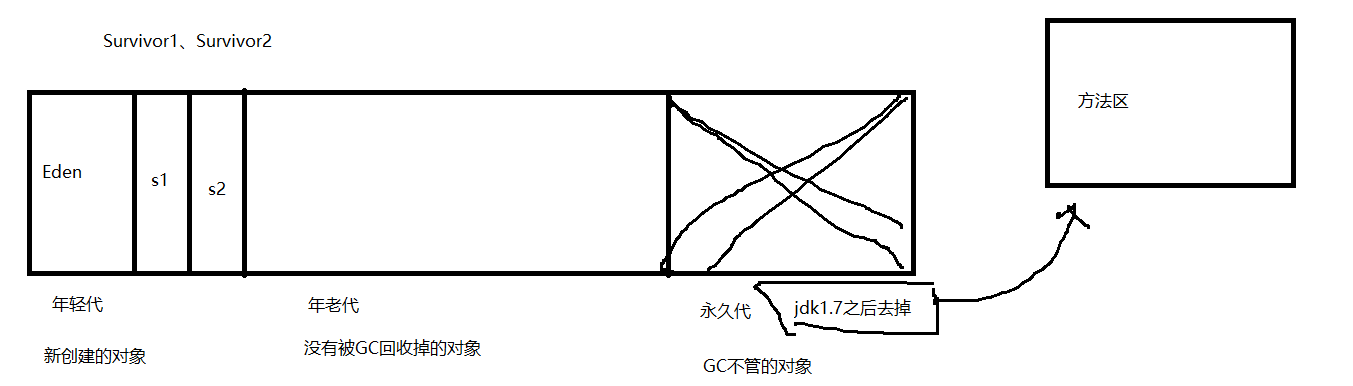
首先我们看一下堆的内存模型
年轻代(Eden区)(复制整理算法)
对象的诞生会保存在Eden区 。 经历过一次gc还存在的放入Survivor区 , 该区分为两个相同大小的区域 , 如图上所示s1 , s2
S1区(from)
GC第一次回收没有回收掉的对象进行S1区 。 岁数+1
S2区(to)
GC第二次还是没有回收掉就会进入S2区 。 岁数+1
当对象岁数超过15岁时或Survivor区满时 , 转入年老代
三部分内存占比为Eden:S1:S2 是8:1:1
因为Eden区存放所有新建的对象 , S1和S2仅仅是存放部分没有被回收的对象 , 这部分没有被回收的对象一定小于新建的对象总数 。
从上面的比例我们发现s1和s2的空间是1:1 , 这是什么原因?
这是因为年轻代的gc回收算法是复制回收算法 , 什么叫复制回收算法 , 顾名思义 , 就是用复制的方式来回收垃圾的算法 ,
复制回收算法会将没有回收掉的对象在S1和S2之间反复复制 , 如果反复复制多次还是没有被回收则进去年老代 。 这样 , 就存在两个问题:
1.有没有可能S1中没有一个对象被回收?如果一个都没有被回收 , 也需要把S1区的对象挪到S2 。
2.内存中移除一个对象 , 会空出一个空间 , 如果移除对象不连续 , 就会导致空出的空间不连续 , 如果此时要有一个3k的内存存一个文件 , 但是有两个不连续的空间合起来为4k , 一个是2k , 另一个也是2k , 就无法存3k的文件 。
解决方式就是复制回收算法:
每次的移除 , 就全部清场重置 , 这样就可以充分利用空间 。
所以 , 需要有两个一模一样大小的空间 , S1和S2区域的空间大小一模一样 。
年老代:标记清除算法或者标记-压缩算法
以标记清除算法为例
标记阶段:给引用的对象添加标记可以参考下面的伪代码
为了能够区分对象是live的可以为每个对象添加一个marked字段 , 该字段在对象创建的时候 , 默认值是false
假设有一个对象p , p对象还间接的引用了其他对象 , 那么可以使用一个递归算法去进行标记 , 例如以下代码
只有当所有对象已经被mark后才会退出 。
清除阶段:
遍历根对象的集合 , 把未被标记的对象回收可以参考下面的伪代码
此时会去遍历堆中所有对象 , 并找出未被mark的对象 , 进行回收 。 与此同时 , 那些被mark过的对象的marked字段的值会被重新设置为false , 以便下次的垃圾回收 。
优点:能够进入老年代的对象 , 一般都相对稳定 , 所有被回收的数量较少 , 减少对磁盘的清理 , 如果采用复制整理算法 , 被复制的对象会有很多 。
缺点:虽然垃圾得到了回收 , 但是回收以后 , 堆内存中出现了不连续的现状---内存碎片 , 导致大对象无法创建
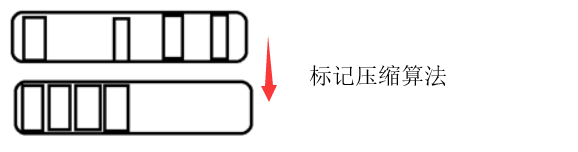
标记压缩算法正好可以解决内存空间这一问题 , 和标记清除算法基本相同 , 唯一不同的就是 , 在清除完成之后 , 会把存活的对象向内存的一边进行压缩 , 这样就可以解决内存碎片问题 。
- #程序员#?8年经验程序员跳槽,2个月面试腾讯百度京东等70家公司,总结出4个共同点
- 爱小楠聊科技|三者缺一不可,手机拍照的未来在哪里?CMOS、芯片和算法
- 少年帮|新氧升级算法加强人工审核规避黑产入侵,疫情加速消费决策线上化
- 驱动之家|没办法啊!,华为:数据存储芯片、算法都是自己做
- 『阿里巴巴』阿里巴巴“面试三分钟,年薪500万”的由来!
- 阿里巴巴:42岁阿里程序员去小公司面试被淘汰:年龄太大,网友:这是借口
- #腾讯#男子面试腾讯挂了,去小公司上班后,入职不到一周接到腾讯电话愣了
- 科技小丸家|花粉:AI算法太爱了,华为最强黑科技神机!麒麟985+50倍数字变焦
- 驱动之家资讯|Waymo自动驾驶算法挑战赛结果出炉:中国企业地平线4项全球第一
- 科技生活大侠|R-CNN,识别迷雾中的物体,谷歌提出最新目标检测算法Context