DeepMind秀出最强游戏AI!57场Atari游戏超过人类,复盘游戏AI进化史( 三 )
为了克服耗时长的局限性 , 研究人员引入内在奖励机制 , 使代理在短时间内访问尽可能多的部分 。 内在奖励机制分为长期新颖性奖励和短期新颖性奖励 。
2、长期新颖性奖励
当代理遇到其从未处理过的情况时 , 就会触发长期新颖性奖励(Long-term novelty rewards) 。
算法依据状态密度函数来判定代理是否处于全新的环境中 , 即算法会依据代理当前状态在总体状态中发生的频率进行调整 。 如果密度较高 , 长期型新颖性奖励就低 , 反之则高 。
这个模型也存在一些问题 。 在高维空间中 , 学习密度模型常由于维度灾难而出现问题 。 在代理模型中表现为灾难性遗忘(catastrophic forgetting) , 即遇到新情况时 , 代理会忘记之前的信息 。 还有可能发生无法为所有的输入提供精准输出的情况 。
3、短期新颖性奖励
短期新颖性奖励(Short-term novelty rewards)则用于鼓励代理去探索近期没有遇到过的状态 。 情境记忆能力与短期新奇奖励相关性较高 。
NGU可以快速学习一种实时调整的非参数密度模型(non-parametric density model) 。 在这种情况下 , 奖励的大小是通过测量当前状态与以往状态之间的差距来决定的 。
但是 , 并不是所有较大的差距都指向有意义的探索 。 假设被应用于导肮 , 运行短期奖励机制的代理将关注每一个微小的变化 , 造成很大的计算量 。
为了避免无用计算 , 代理需要学习与探索目标相关的特征 , 并且只计算这些特征之间的差距 。
通过这些改造 , NGU在《陷阱》游戏中取得了高分 。 就是说 , 智能代理在探索类游戏中的表现有所提升 。 但是 , NGU在那些简单游戏中的表现则不太好 。 平均而言 , NGU的表现不如R2D2 。
四、Agent57:NGU+自适应元控制器在NGU的基础上 , 智能代理继续迭代 。
除了上述已有的能力 , 研究人员还希望新一代智能代理能够判断在什么时候应该探索、什么时候应该进行开发 , 为此引入了元控制器(meta-controller)的概念 。
元控制器允许代理的每个参与者在近期和长期新颖性奖励之间进行权衡 , 同时探索新状态和利用已知状态 。
将NGU与元控制器结合 , Agent57横空出世 。
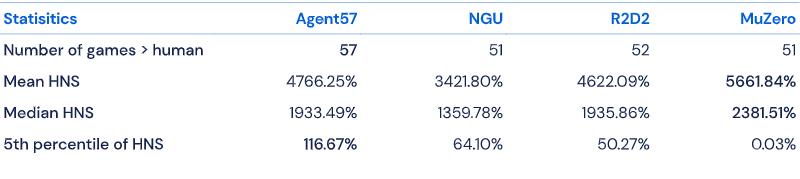
数据显示 , Agent57在57款测试游戏中的表现均超越人类基准 , 平均得分为4766.25% , 中位得分为1933.49% , 在难度排名前五的困难游戏中分数则为116.67% 。 这已经优于以往的所有智能代理模型 。
 文章插图
文章插图
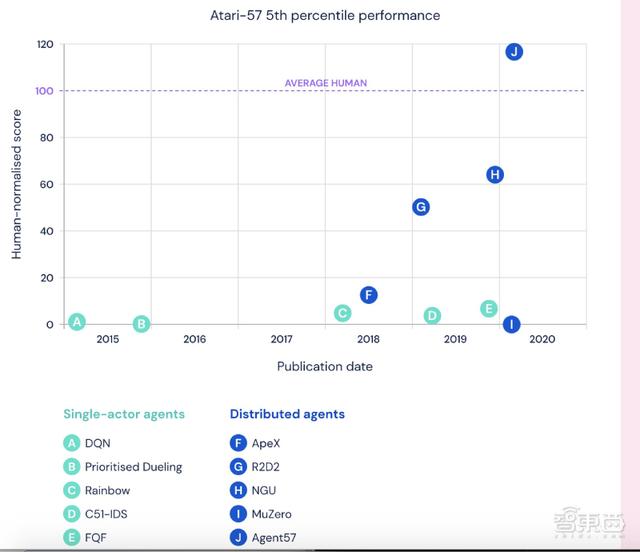
总的来说 , Agent57在简单游戏和困难游戏中均表现优异 , 强化学习能力有普遍提升 。
 文章插图
文章插图
结语:Agent57成RL能力最强智能代理从2015年起 , 经过多次迭代 , 智能代理Agent57横空出世 。 Agent57在NGU基础上添加了元控制器 , 可以判断什么时候该探索、什么时候该开发 , 还具备时间敏感性 。
目前 , Agent57在Atari57中每项游戏的表现都超过了人类基准 , 是史上最为智能的人工代理 。
如果加大计算量 , Agent57还能达到更优的表现 , 这说明它有着超强的学习能力 。 研究人员称 , 经过进一步完善 , Agent57或能落地 , 应用于勘探、规划及信用赋值(credit assignment) 。
【DeepMind秀出最强游戏AI!57场Atari游戏超过人类,复盘游戏AI进化史】文章来源:DeepMind , arXiv
 文章插图
文章插图
- 抢跑上市最强5G芯片系列新机,败走中国的三星让价换销量
- 目前续航能力最强的五款手机,过年回家不怕电不够用
- 神思电子入选AI中国·最强人工智能公司TOP30
- 中国最强芯片巨头,一年花1098亿,2022年量产3nm芯片
- DeepMind巨亏42亿、独角兽惨遭3折贱卖,AI公司为何难有“好下场”?
- 三星最强5G SoC来了!Galaxy S21首发
- 边缘|边缘计算将取代云计算?5G时代的最强黑马出现了吗?
- 中国影响力最强的企业榜单出炉,马云、马化腾不在列,榜首是雷军
- iPhone 13屏幕曝光:搭载三星最强120Hz屏
- DeepMind新AI无需提前知晓规则也能掌握游戏:无论视觉简单还是复杂