按关键词阅读:
上边说得都很好,我总结一下:靠经(xia)验(meng),也就是把这东西又变成一个art… 这其实也是knn之类被人诟病的一点。当然的确有一些思路,比如上边提到的各种。
■网友
可以试试用 Rough set来确定一个K
■网友
经验就是k=3,上限k=sqrt(n)
■网友
正好也遇到这个问题,看到research gate上也有人讨论,很有意思。先看你需要提取什么信息进行分析,K值到底取多少合适貌似没有定论。采用的方法各种,有人用Cross Validation,有人用贝叶斯,还有的用bootstrap,链接:https://www.researchgate.net/post/How_can_we_find_the_optimum_K_in_K-Nearest_Neighbor
■网友
已故的 Peter Hall 教授在这方面做过一些很重要的工作,比如以下两篇文章:
Hall, P., \u0026amp; Samworth, R. J. (2005). Properties of bagged nearest neighbour classifiers. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(3), 363–379.
Hall, P., Park, B. U., \u0026amp; Samworth, R. J. (2008). Choice of neighbor order in nearest-neighbor classification. The Annals of Statistics, 36(5), 2135–2152.
这里简单说一下每篇文章的内容(符号和原文略有不同),具体还是要参考原文。
第一篇文章探讨的是
-NN 分类器(classifier)。对于每一个测试样本点(testing data point),
-NN 用离它最近的训练样本点(testing data point)的类别(class label)作为对该测试样本点类别的预测。然而
-NN 在样本量
趋于无穷的时候是不具有一致性(consistency)的——也就是说
-NN 的精度不会收敛到(理论上最优的)贝叶斯分类器(Bayes classifier)的精度。一般的改进方法是利用 bagging,也就是利用原始的训练数据集产生若干 bootstrap 样本(bootstrap resample),从每一个 bootstrap 数据集中训练出一个
-NN 分类器,然后用这些分类器进行投票。Leo Breiman 告诉我们,一般来说对于不稳定的分类器(比如分类树以及这里的
-NN),bagging 产生的集成分类器(aggregated classifier)比单个分类器的精度要高。然而 Hall \u0026amp; Samworth (2005) 指出,如果 bootstarp 样本的样本量过大,那么 bagging 产生的集成分类器仍然不具有一致性。这时候就需要做 subsampling,也就是 bootstrap 样本的样本量
需要小于原始数据集的样本量
。不仅如此,为了使得集成分类器具有一致性,
和
必须要满足
当
时,
且
也就是说每一个 bootstrap 样本的样本量发散到无穷,但比例
收敛到
。在操作层面,原文还讨论了在
有限时如何利用 cross-validation 选择
的问题。
第二篇文章直接讨论了当
趋于无穷时
-NN 中的
应该怎么选的问题。前面说了
-NN 是不具有一致性的,而事实上如果
不发散到无穷,任何
-NN 都不具有一致性(比如
-NN)。Hall et al. (2008) 对
-NN 分类器的风险函数(risk function)
(
指原始训练集的样本量)进行了展开,发现最优(使得 【KNN算法中K是 咋决定的】
最小)的
应该满足
其中
为常数项,
是指数据的维度。此时最小的风险
则满足
此中
表示(理论上最优的)贝叶斯分类器的风险。也就是说,当
以一定的速度发散到无穷时, 分页标题#e#
-NN 的风险收敛到贝叶斯分类器的风险。这里我们可以看到维度
对于
-NN 方法的风险的收敛速度的负面影响。当然到这里问题并没有完全解决,因为我们并不知道 (1) 式中的常数项
怎么选(一般来讲这类常数项的准确表达都很难得到,除非是有很具体的参数假设)。因此原文还讨论了如何在这些理论基础上利用 cross-validation 选择
的问题。
如果题主对
-NN 的理论有兴趣,可以进一步搜索这两篇文章引用的以及引用这两篇文章的文献。关于 Peter Hall 教授在分类问题上的其他贡献,可以参考这一篇综述:
Samworth, R. J. (2016). Peter Hall’s work on high-dimensional data and classification. The Annals of Statistics, 44(5), 1888–1895.
■网友
按照前几天组会交流的方法,
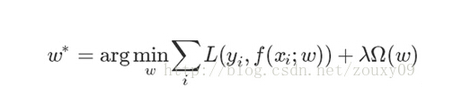
采用岭回归,并将L2范式换用L1范式,得到W*矩阵。行是测试样本,列是训练样本,举个例子

那么
(观察列的非零元素个数),其中第二行是噪声 。
对了,忘记说了可以对距离加权,从而降低k值设定产生的影响
![]()

来源:(未知)
【】网址:/a/2020/0416/gd399533.html
标题:KNN算法中K是 咋决定的
