按关键词阅读:
小编提示您本文标题是:深度学习深度学习(三十六)LSTM实践,自己创建文章。来源是。
原理介绍完了,下面看看怎么实现LSTM。一如既往的使用tensorflow。
这个小的应用是输入一篇文章,当然,是英文的,然后通过机器学习后,我们可以复原一个类似的文章。这里说明一下,这篇文章的处理单元是单个字符。通过长短期记忆,来完成对一篇文章的内容进行学习。实际上就是任意输入一个字符,然后判断一下,这个字符后面最有可能出现的下一个字符是什么。那么下一个字符,就是本次字符的标签了。好了原理就是这样,我们直接看看如何实现吧。
首先,读入文本内容:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

注意,凡是文本处理,一定是编码,就是把出现的内容进行0-n的编码,假设,我们只有26个小写的英文字符,那么我们可以让a=0,b=1...z=25。类似,我们在这个例子也是如此,为此,我们要做一个字典,就是哪个字符用哪个数字表示,很显然数字序号是经过排序的。
那么这个字典实际上就是vocab_to_int以及int_to_vocab这两个,一个数字编码到字符,一个是字符到编码。
好字典有了,那么原文,就可以翻译成全编码状态了,这个就是encode变量了。
下面就要进行批量处理了:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

参见上图,我们通过编码后的文本是一个单线的一维数字数组,类似如上图第一个序列。
而我们处理的时候,通常是按照批次来完成的,这里就有了batch的概念,这就是上图第二个图的实例,
而批次,比如两个批次只是很粗暴的将原来的序列由一行等分成两行,而我们每次是多个批次,同时取n个,这个就是上图的第三层图,就是黄色部分的示意图了,这里每个批次取的长度,我们叫做step又叫上图所标识的sequence length。实现代码如下:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
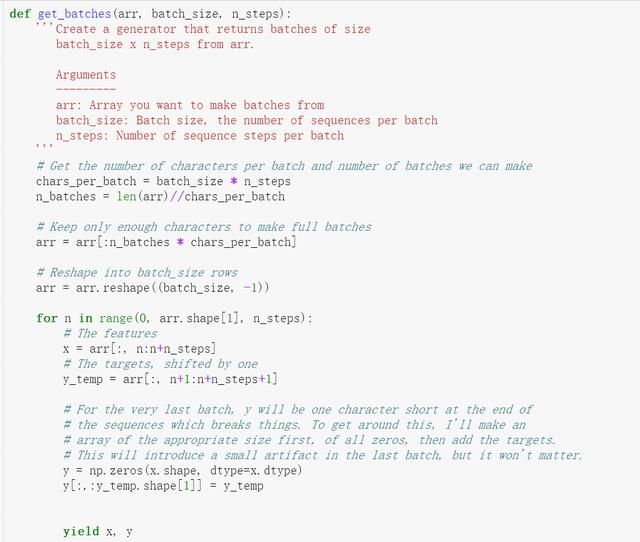
好下面,我们就要创建LSTM层了,LSTM层,在tensorflow里面是有现成的创建过程的。(LSTM是啥,出门左转吧,看本系列的上一篇文章介绍)
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
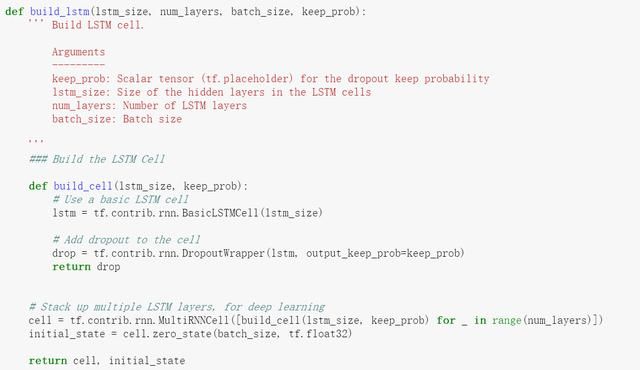
我们创建LSTM层,其实重点是两个参数,一个LSTM有多少层,一个是一层有多少个单元。
这里注意两点:
LSTM的创建,是先单独建立一层(输入一层有多少个单元),然后在通过tf.contrib.rnn.MultiRNNCell函数将多层堆叠起来。是分开两步创建的。
LSTM创建好后,经过LSTM计算(下面有对应的代码)后,输出的那个单元的长度,实际就是LSTM一层的单元数量
另外,LSTM因为是长期记忆,所以,是有对应状态的,这个也很重要。
然后,我们就开始计算结果了:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
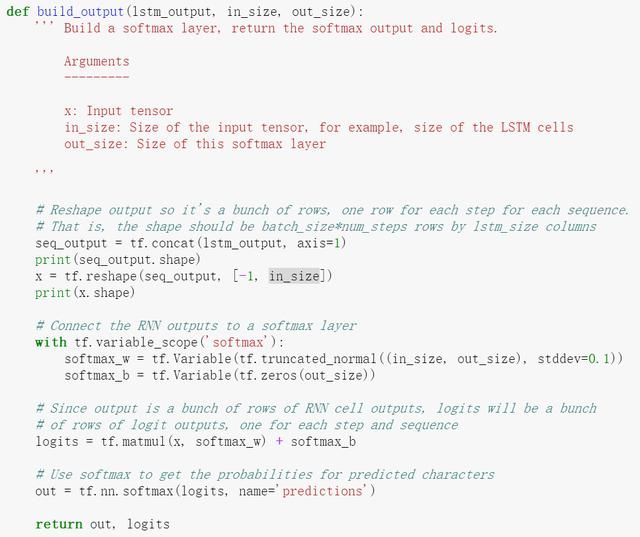
这个代码,重点是结果的处理。参数:lstm_output其实就是刚刚LSTM层计算的结果。
这个结果是一个三维的张量[batch*step*LSTMUnit]前两维,代表之前说的,一次输入的批次的字符,而最后一维,实际上就是单个字符,经过一次LSTM计算后,得出的数量,上面也说过了,这个数量就是LSTM的单层单元长度。
好,了解了这个以后,下面要做的其实就是要把这个结果进行一次展平层的神经网络计算(就是普通的隐藏层)而普通隐藏层只支持二维的,所以上面代码,头几步就是要把这个三维的张量转成二维的。怎么转呢?当然是把batch*step个字符数组部分拉平变成一维的就行了,所以转换后的张量就变成了[batch*step,LSTMUnit]的张量了。
后面的代码好动了启动单层Y=X*W+B模式,进行神经网络计算。
下面要计算lost了
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
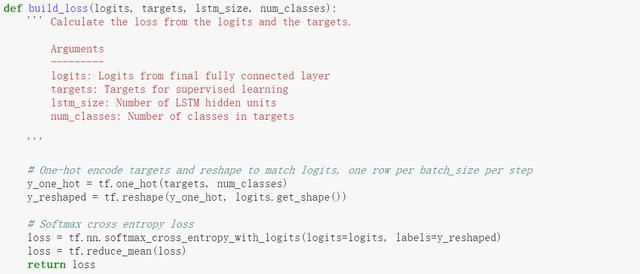
这个很传统了,不解释。
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
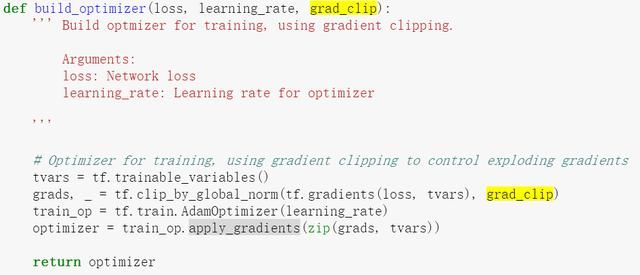
然后进行梯度下降,优化。
这里值得说明的是,这里有一个叫做grad_clip的参数和处理,这里就是要保证,进行梯度下降的时候,偏差不能太大。
好下面我们把它拼凑在一起:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

上述代码中,有一个判断,就是sampling是否为true,这是用于区分当前是训练状态还是使用状态。可以看出,训练状态是按照batch进行的,而使用状态呢,实际上每次只输入一个字符。
关键点是outputs, state = tf.nn.dynamic_rnn(cell, x_one_hot, initial_state=self.initial_state)
RNN的LSTM是要手动计算的,这个和我们熟悉的展平层和卷积层都不大一样,LSTM从建立模型开始,到后面的计算都要手动进行。
好完事后,我们进行训练:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

注意,懒得改了,上面是调试时候的,epochs改成20才能真正训练
这里,当然了,训练的参数是这些:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

好了,为了便于理解,上述创建模型的时候,有三处打印,分别将某些参数的形状打印出来了。
分别是:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

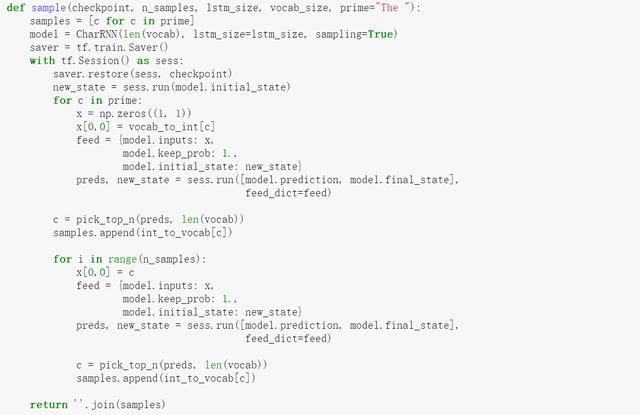
从上面代码也可以看到,当每次训练后,都会把sess记录下来,便于后面使用,使用的代码如下:
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词

文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
文章|实践|创建|张量|字符|深度学习---小编总结的本文关键词
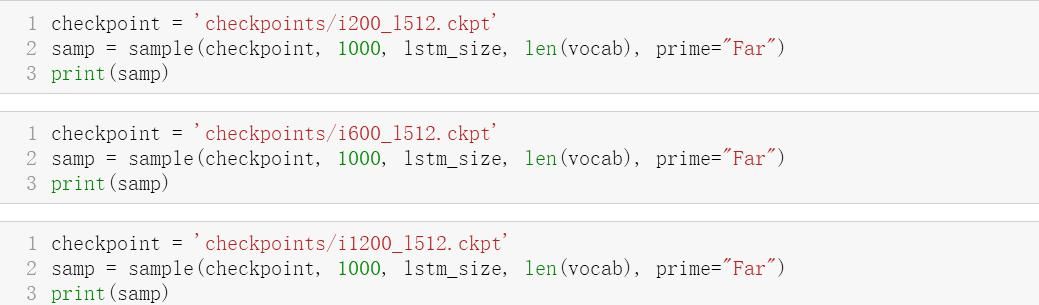
哈哈,不同的输入情况下,都会给你来上一段输出的,挺有意思,有兴趣就试试吧。
这篇文章介绍了最基础的LSTM如何使用,下一篇文章介绍Embedding的用法,例子很有意思是一个词语的向量分析,用于分析同义词的时候蛮有效果的。
稿源:(深度学习深度学习)
【】网址:http://www.shadafang.com/c/sc202342.html
标题:深度学习深度学习(三十六)LSTM实践,自己创建文章
