技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡评测:性能飞跃 温度更“嘉”( 二 )
在供电方面 , 技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡采用的是单6Pin+单8Pin的设计 。 同时在显卡的上方搭载了一个RGB LOGO灯 。
关于显卡的外观 , 相信大家已经有所了解 , 接下来带大家了解一下NVIDIA Ampere架构 。
02 NVIDIA Ampere架构下RTX 3060 Ti
技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡采用了NVIDIA Ampere架构 , 我们首先来看一下RTX 3060 Ti的提升 。
第一代RTX架构 Turing下的RTX 2060 SUPER
第二代RTX架构 Ampere下的RTX 3060 Ti
相较于初代的Turing RTX架构 , NVIDIAAmpere架构在算力上有着成倍的增长 , 这一点在RTX 3060 Ti中依旧有体现 , 每个时钟执行2次着色器运算 , 而Turing为1次 , RTX 3060 Ti的着色器性能达到16.2 TFLOPS单精度性能 , 而Turing为7.2 TFLOPS 。
NVIDIAAmpere架构翻倍了光线与三角形的相交吞吐量 , RT Core达到31.6 RTTFLOPS , 而Turing为21.7 RT TFLOPS 。
全新的Tensor Core可自动识别并消除不太重要的DNN权重 , 处理稀疏网络的速率是Turing的两倍 , 算力高达129.6 TensorTFLOPS , 而Turing为57.4 TensorTFLOPS 。 文章插图
文章插图
技嘉RTX 3060 Ti GAMING OC PRO 魔鹰显卡采用GA104核心拥有174亿个晶体管 , 392平方毫米的面积 , 基于三星的8nm NVIDIA定制工艺 , 另外在RTX 3060 Ti中我们都知道仍然采用了GDDR6显存 , 不过不同于RTX 3080的Micron , RTX 3060 Ti采用了三星的GDDR6显存 。
我们在发布会中经常听到性能翻倍的说法 , 其实是因为本次NVIDIAAmpere的SM在Turing基础上增加了一倍的FP32运算单元 , 这就使得每个SM的FP32运算单元数量提高了一倍 , 同时吞吐量也就变为了一倍 。
而通常我们计算显卡的CUDA数量 , 并不是把SM中的所有单元加起来计数 , 而是只统计FP32单元的数量 , 所以这样一来 , SM中的【FP32 : INT32】 从 1:1 变为 2:1 。
RTX 3060 Ti共有4864个CUDA , 其实它有2432个INT32单元 , 但由于内部的FP32数量翻了一倍 , 所以最终实现了4864这个惊人的数字 。
而这样粗暴的提升CUDA数量对于游戏其实有着非常大的帮助 , 通常在游戏中浮点运算相比整数计算要常用的多 , 图形、算法以及各种计算操作中着色器工作负载通常需要混合使用FP32算数指令 , 而FP32的加速也有助于光线追踪降噪着色器 。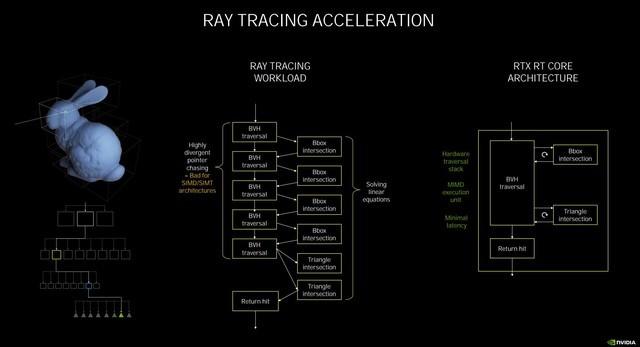 文章插图
文章插图
光追工作原理示意
在此次的NVIDIAAmpere架构中 , NVIDIA官方宣布为第二代RT Core , 它和第一代有什么不同呢 。 首先要知道RT Core的工作原理是 , 着色器发出光线追踪的请求 , 交给RT Core来处理 , 它将进行两种测试 , 分别为边界交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersectiontesting) 。 基于BVH算法来判断 , 如果是方形 , 那么就返回缩小范围继续测试 , 如果是三角形 , 则反馈结果进行渲染 。
而光线追踪最耗时的正是求交计算 , 因此 , 要提升光线追踪性能 , 主要是对两种求交(BVH/三角形求交)进行加速 。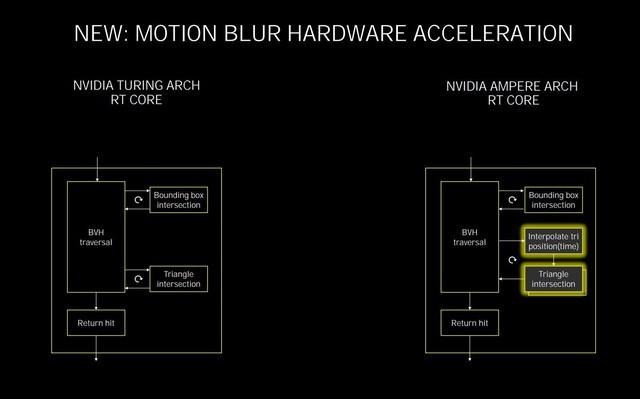 文章插图
文章插图
RT Core的变化
在Turing的RT Core中 , 可以每个周期完成5次BVH遍历、4次BVH求交以及一次三角形求交 , 在第二代RT Core 里 , NVIDIA增加了一个新的三角形位置插值模块以及一个的额外的三角形求交模块 , 这样做的目的是为了提升诸如运动模糊特效时候的光线追踪性能 。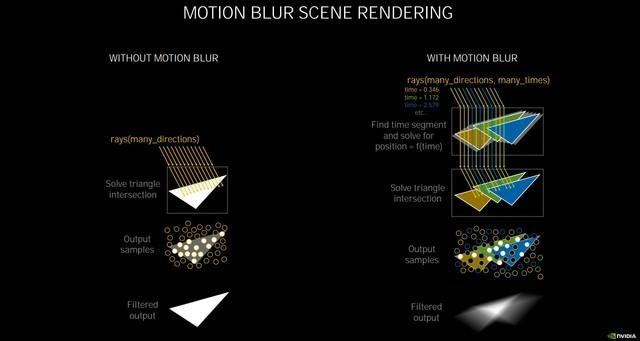 文章插图
文章插图
运动模糊渲染原理
第二代RT Core可以让光线追踪与着色同时进行 , 进行的光线追踪越多 , 加速就越快 , 它将光线相交的处理性能提升了一倍 , 在渲染有动态模糊的影像时 , 按照NVIDIA自己的实测 , 比Turing快8倍 。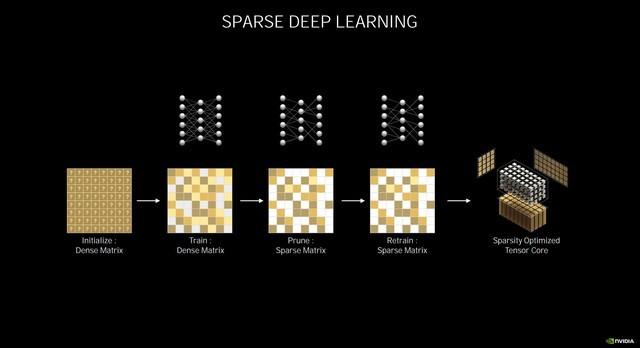 文章插图
文章插图
稀疏深度学习
Tensor Core可以看作是GeForce RTX GPU上的AI大脑 。 可加速用于深度神经网络处理功能的线性代数 , 这是现代AI的基础 。 例如用于AI超分辨率的NVIDIA DLSS和用于AI增强的声画处理技术NVIDIA Broadcast应用 。
在本次的NVIDIA Ampere架构的Tensor Core也得到了极大地加强 , 在第三代Tensor Core中 , NVIDIA引入了稀疏化加速 , 可自动识别并消除不太重要的DNN(深度神经网络)权重 , 同时依然能保持不错的精度 。
首先原始的密集矩阵会经过训练 , 删除掉稀疏矩阵 , 再经过训练稀疏矩阵 , 从而实现稀疏优化 , 进而提高Tensor Core的性能 。
- 显卡|田言梦语:你会买RTX 40系列“空气”显卡吗?
- 显卡|?灵耀Pro14 流星白惊艳登场, RTX 30系显卡的14寸轻薄本,赚翻!
- 三星|4200元高端迷你RTX3060显卡开箱,小机箱专属,颜值超高
- 台积电|「资讯」RTX 40的面貌逐渐清晰:确认使用台积电5nm制程、性能提升明显
- RTX2060|Intel新独显最新消息:性能相当于GTX 1650 SUPER
- RTX2060|NVIDIA 于官网列出 GeForce RTX 2060 12GB 规格!
- 诺基亚|6999的神车又回来了!十一代i7+3060性价比炸裂
- 荣耀|最后一波促销别错过,双十二天选RTX30游戏本迎好价,最低6K入手
- nas|缺芯涨价又如何?老黄还要发布RTX 3090Ti,一堆新技术加持
- iPhone|一“Ti”之差,差之千里,RTX3060和3060TI性能差距总结