a2489|谷歌 DeepMind MuZero 人工智能可以不学规则掌握游戏
IT之家12月24日消息 谷歌的 DeepMind 人工智能目前已经进化到第四代,名为 MuZero。最新的版本可以无需学习棋类等游戏规则便能掌握游戏。该技术能够应用于机器人技术、工业系统以及混乱的现实世界。
文章插图
早在 2016 年,AlphaGo 先后击败围棋世界冠军李世石、柯洁,这仅仅是 DeepMind 人工智能的初代版本,需要事先输入大量人类对弈数据、规则数据进行训练,然后才可以进行实战。AlphaGo 是首个能够利用神经网络、树状搜索完全掌握围棋的人工智能。
此后于 2017 年推出的第二代 AlphaGo Zero,能够不借助人类对弈数据,仅仅事先输入规则便可自行训练,最终掌握围棋。
谷歌第三代的人工智能 AlphaZero,不仅可以自主学会围棋,也仅仅依靠事先了解规则,掌握了国际象棋、日本将棋。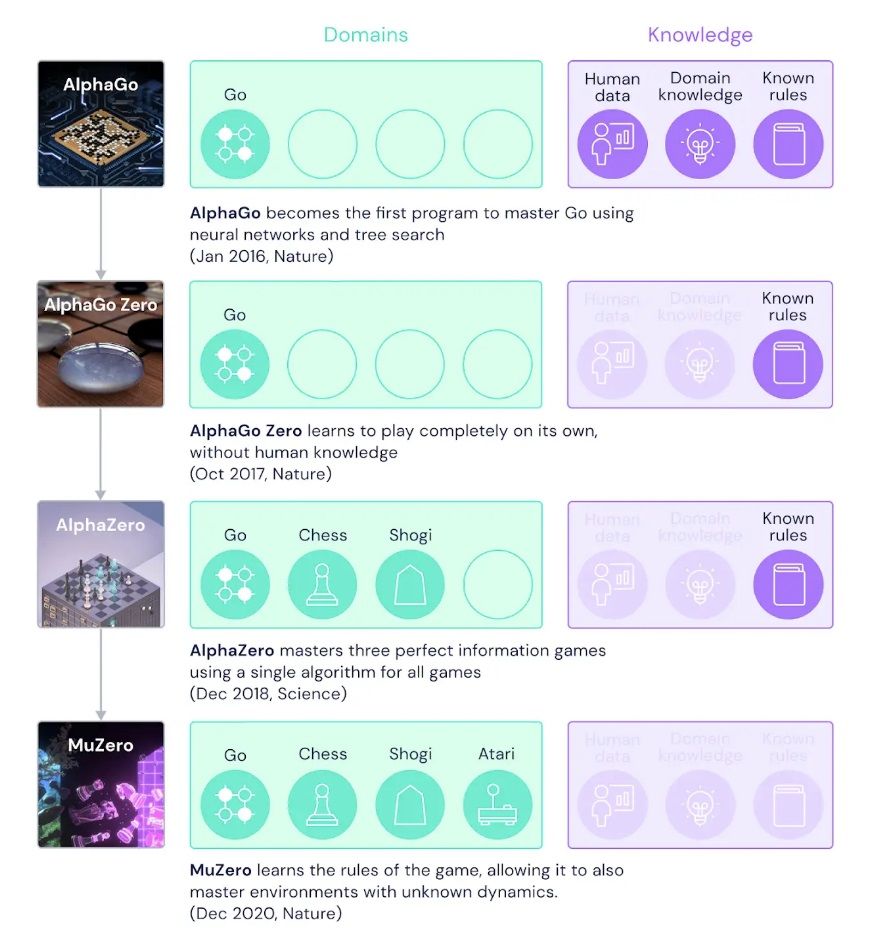
文章插图
根据谷歌发表在《自然》杂志的文章显示,第四代人工智能 MuZero 可以在未知规则的情况下学会上述四种棋类,规划制胜策略。此外,还能够掌握掌机游戏 Atari。
DeepMind 公司表示,多年来研究人员一直在寻找一种方法,既可以学习建立用于解释目前环境的模型,也能够利用这个模型来进行最好的决策。直到今天,大多数方法都难以在 Atari 这种游戏中进行有效规划。
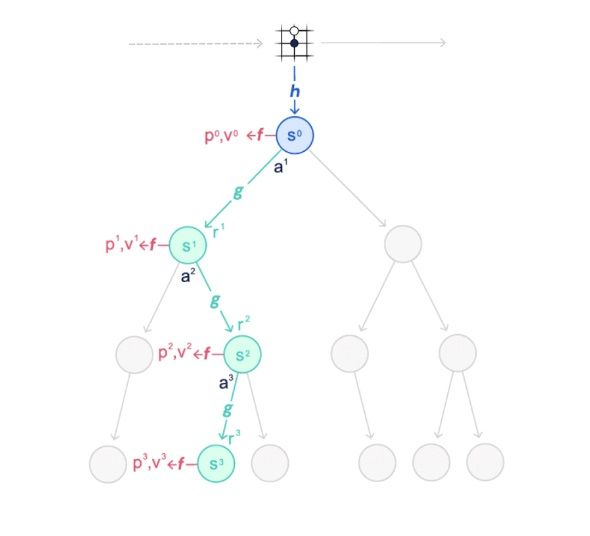
MuZero 首先在 2019 年推出,通过只关注环境中最重要的一个方面,来学习建立一个模型,并解决问题。通过将这种方法与 AlphaZero 强大的搜索树技术相结合,MuZero 的能力实现了重大飞跃。此外,MuZero 还利用了前瞻搜索、基于模型的规划来解决问题。具体来说,MuZero 对环境中至关重要的三个问题来计划:
- 价值:现在所处的位置有多好?
- 策略:哪一种行动是最好的?
- 奖励:最后一步的动作结果有多好?
文章插图

文章插图
【 a2489|谷歌 DeepMind MuZero 人工智能可以不学规则掌握游戏】IT之家了解到,Atari 公司于 1976 年在美国推出了 Atari 2600 游戏机,这是史上第一部真正意义上的家用游戏主机,其整个生命周期持续到 1992 年,共售出三千万台。
- 监管机构|谷歌和Meta被俄罗斯监管机构告上法庭,或面临巨额罚款
- 华为mate|谷歌Pixel Watch最新消息,有望明年初发布
- 谷歌|奥密克戎来袭,谷歌称复工计划无限推迟
- 谷歌|科技巨头创始人正退出舞台!谷歌阿里字节等10大创始人退出史
- 验证码|如何把谷歌两步验证设计到产品中
- 英特尔|微软、谷歌、IBM之后,印度人又掌管一家美国科技公司,年仅37岁
- 苹果|曾被美国拒签8次,山东程序员打败谷歌苹果,靠螺丝刀身家涨200亿
- 操作系统|谷歌浏览器操作系统
- 红米手机|全球搜索引擎市场份额:谷歌搜索92.54%,百度搜索1.08%
- 计算机科学|推特首席科学家Michael Bronstein加入牛津大学任职DeepMind教授