KANO|如何利用 KANO 模型计算需求优先级( 二 )
比如 我曾经之前在 P2P 行业针对某一功能点做过的调研数据:
A:15.6% ;O:40.1% ;M:37.5% ;I:1.5% ;R:4.5% ;Q:0.8%。
显然占比最高的是 O (期望型需求)。
那么问题来了,如果几个需求都是一个类别,那么怎么区分优先级呢?
这时候我们可以引入 Better-Worse 系数来进行分析,Better-Worse 系数表示的是某个功能可以增加或者消除不喜欢的影响程度。
Better-Worse 系数公式如下: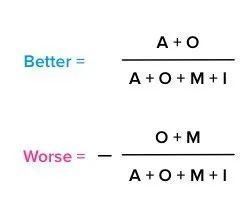
文章插图
通过计算,每一个需求点都会得到 Better/SI 和 Worse/DSI 两个系数;其中 Better/SI 被理解为增加后的满意系数,数值通常为正数。
代表如果提供某种功能属性的话,用户满意度会提升;正值越大/越接近1,表示对用户满意上的影响越大,用户满意度提升的影响效果越强,上升的也就更快。
Worse/DSI 则可以被叫做消除后的不满意系数,其数值通常为负,代表如果不提供某种功能属性的话,用户的满意度会降低;值越负向/越接近-1,表示对用户不满意上的影响最大,满意度降低的影响效果越强,下降的越快。
既然有了两个系数,我们就可以做一个平面直角坐标系了。
文章插图
根据这个坐标系,我们可以按照如下排序规则进行排序:必须 > 期望 > 魅力 > 无差异。
文章插图
对于在同一象限中的功能点,以 Better系数/|Worse 系数|的大小排序,越大越靠前。
三、最后上边说到了,KANO 模型仅仅关注的是产品性能和用户满意度的非线性关系,并没有衡量实现该功能对于企业的收益和成本(商业价值)。
在实际使用上,我之前还推荐过《需求管理之价值 vs 复杂度矩阵》,通过价值和成本的对比进行需求的排序。
不过 KANO 和价值 VS 复杂度矩阵都是一种工具,具体怎么用还得在实际业务中选择最合适的。
#专栏作家#张小璋,公众号:张小璋碎碎念(ID:SylvainZhang),人人都是产品经理专栏作家。野蛮生长的产品经理,专注于互联网金融领域。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
【 KANO|如何利用 KANO 模型计算需求优先级】题图来自 Unsplash,基于 CC0 协议
- 抖音|抖音如何获取更多流量?一文读懂直播自然流量提升技巧
- 东芝|如何分辨手机配置的“好坏”?认清这四点,你也能成为行家
- iqoo neo|一部手机可以用多久?来看下iQOO次旗舰是如何解答的
- 人机|人机融合时代,中国机器人如何弯道超车
- 显卡|显卡和处理器如何组合?
- 小米科技|别吵!理性分析:i5-12600K和锐龙7 5800X该如何选择呢?
- 骁龙870|骁龙778G和骁龙870的差距究竟有多大?作为消费者应该如何选择?
- 芯片|算力的阿克琉斯之踵,阿里达摩院如何破局?
- 机器|工业触摸屏一旦出现了失灵,我们要如何处理你知道吗?
- 验证码|如何把谷歌两步验证设计到产品中