Python网络爬虫快速上手
环境准备:事先安装好 , pycharm打开File——>Settings——>Projext——>Project Interpriter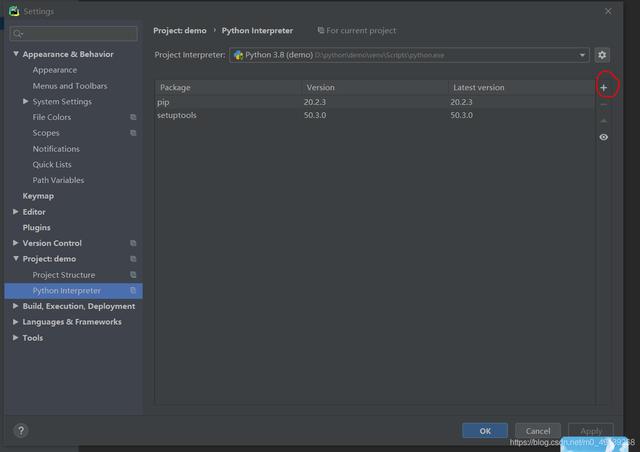 文章插图
文章插图
点击加号(图中红圈的地方)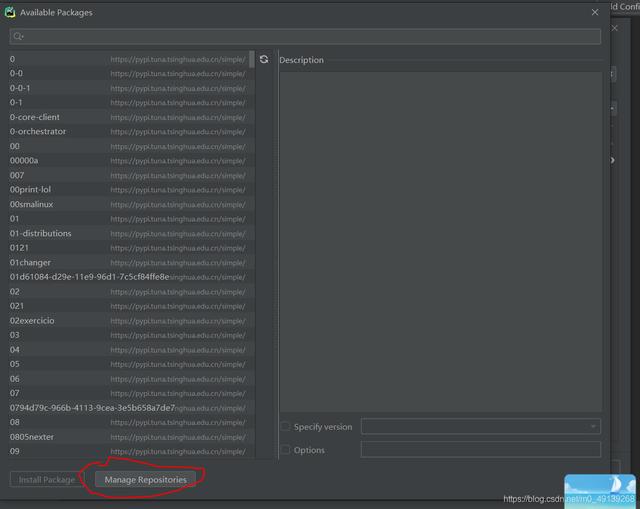 文章插图
文章插图
点击红圈中的按钮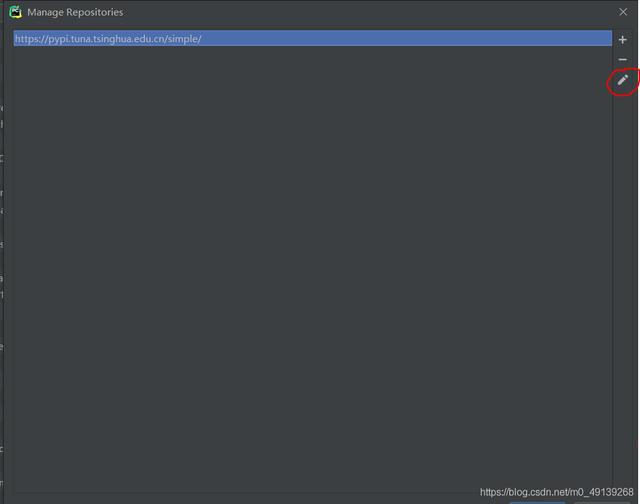 文章插图
文章插图
选中第一条 , 点击铅笔 , 将原来的链接替换为(这里已经替换过了):点击OK后 , 输入requests-html然后回车选中requests-html后点击Install Package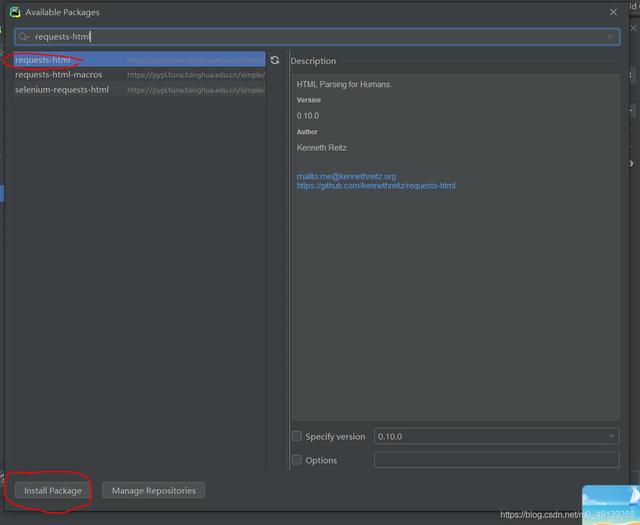 文章插图
文章插图
等待安装成功 , 关闭
通过解析网页源代码实例内容:从某博主的所有文章爬取想要的内容 。 实例背景:从()博主的所有文章获取各文章的标题 , 时间 , 阅读量 。
- 导入requests_html中HTMLSession方法 , 并创建其对象
from requests_html import HTMLSessionsession = HTMLSession()123- 使用get请求获取要爬的网站,得到该网页的源代码 。
html = session.get("").html12- 找到所有文章
allBlog=html.xpath("//dl[@class='tab_page_list']") 1- 进入网站主页(本例: )
- 文章空白处右键检查可以定位到这文章的标签
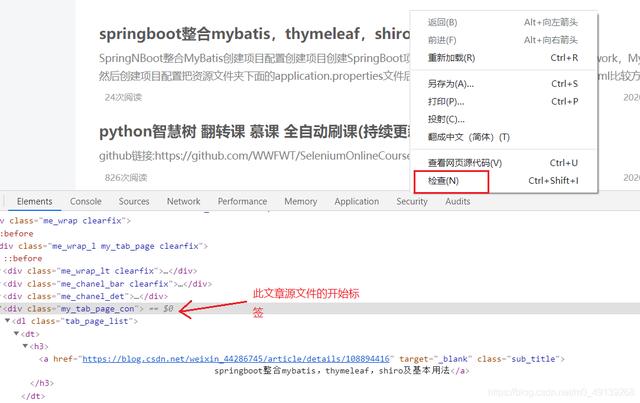 文章插图
文章插图- 其他文章一样操作 , 然后找到所有文章共同的标记(这里所有文章的class都是‘my_tab_page_con’)
- xpath 可以遍历html的各个标签和属性 , 来定位到我们需要的信息的位置 , 并提取 。
- 网页分析获取标题 , 阅读量 , 日期 。
for i in allBlog:title = i.xpath("dl/dt/h3/a")[0].textviews = i.xpath("//div[@class='tab_page_b_l fl']")[0].textdate = i.xpath("//div[@class='tab_page_b_r fr']")[0].textprint(title +' ' +views +' ' + date )12345网页分析:- 因为有多篇文章 , 分别获取使用for循环 , 上述代码已得到所有文章所以i表示一篇文章
- 第二行代码获取文章标题 , 于获取文章类似 , 鼠标放到标题上右键检查 , 因为文章只有一个标题所以用绝对路径也可以按标签一层层进到标题位置 。
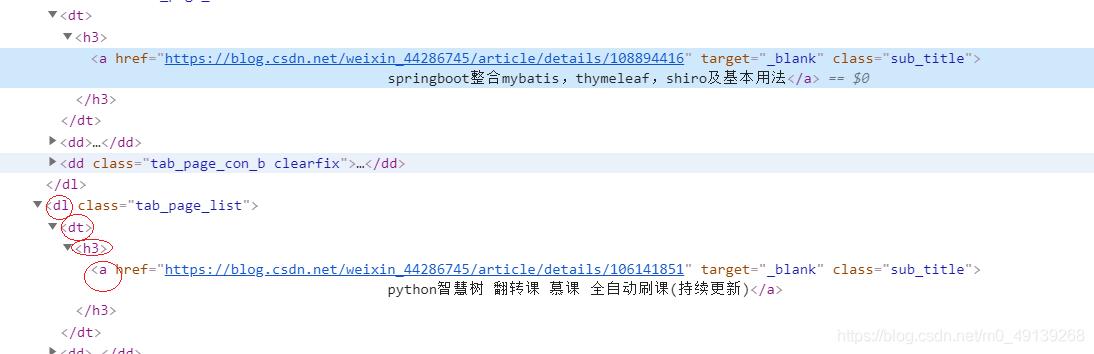 文章插图
文章插图- xpath返回的是列表 , 我们要第一个所以要加下标(列表里也只有一个元素) , 要输出的是文本 , 所以,text获取文本 。
- 阅读量和时间也是重复的操作
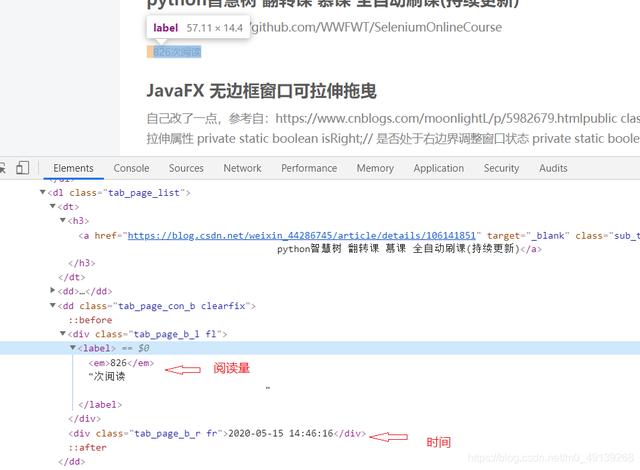 文章插图
文章插图- 可以用相对路径也可以用绝对路径 , 一般都是用相对路径 , 格式仿照代码 。
- 第五行代码 , 每得到一篇文章的信息就输出 , 遍历完就可以获得全部的信息 。
from requests_html import HTMLSessionsession = HTMLSession()html = session.get("").htmlallBlog=html.xpath("//dl[@class='tab_page_list']")for i in allBlog:title = i.xpath("dl/dt/h3/a")[0].textviews = i.xpath("//div[@class='tab_page_b_l fl']")[0].textdate = i.xpath("//div[@class='tab_page_b_r fr']")[0].textprint(title +' ' +views +' ' + date )1234567891011121314- 可以自己爬其他东西 , 如文章图片 , 动手试试吧!!!未完待续
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 。
- Python|OriginOS Ocean新特性:隐私保护、锁屏界面挂起应用都有了
- 杜比|2021年度排名TOP5的网络机顶盒,买哪个最靠谱?
- Python|联想真的没有问题?中国院士公布数据,胡锡进改变立场
- GPU|python装饰器一篇看懂
- Python|截止12月份 最值得入手的三款手机 款款极致性价比随便买一款用几年
- 电信运营商|民航局:鼓励航司、电信运营商和互联网企业开发空中网络服务
- Python|编程语言也环保?C 语言领跑,Python、Perl 和 Ruby 表现不佳
- Python|小米 CyberDog 机器人将运行 Ubuntu 操作系统
- 联想|保安大叔谈联想爆红网络,言辞犀利,一句话道出了背后的本质
- Python|曾占中国30%市场,百年日企衰落,半年亏562亿,只怪智能机太畅销