每日一个爬虫练习:爬取喜马拉雅音频
前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 。
本次目标爬取喜马拉雅音频
 文章插图
文章插图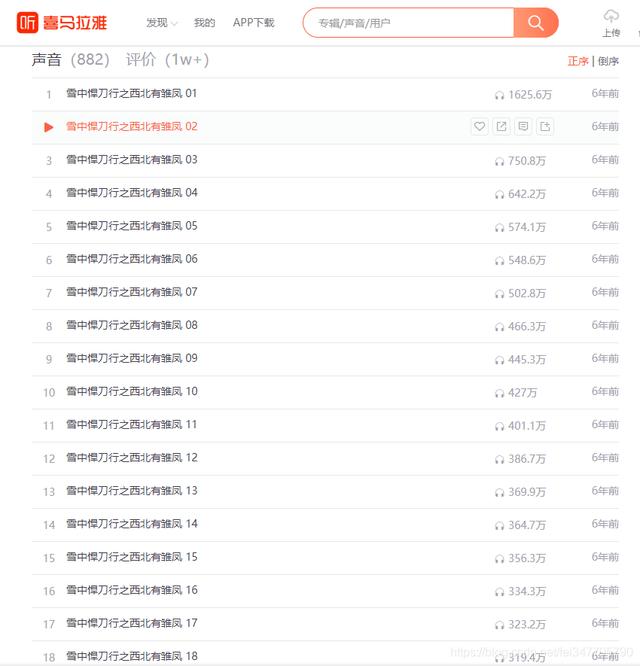 文章插图
文章插图
开发工具
- python 3.6.5
- pycharm
import requestsimport reimport time请求网页headers = {'cookie': 'device_id=xm_1596531699133_kdfpr35pt5o0on; _xmLog=h5 x_xmly_traffic=utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A; Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070=1600235340,1600499992,1602060323,1602060364; Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070=1602060571','user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'url = 'youshengshu/2684034/p{}/'.format(page)response = requests.get(url=url, headers=headers)【每日一个爬虫练习:爬取喜马拉雅音频】解析网页数据lis = re.findall('', response.text, re.S)[4:-1]for i in lis:title = i[0]num_id = i[1].split('/')[-1]mp3_url = 'revision/play/v1/audio?id={}&ptype=1'.format(num_id)response_2 = requests.get(url=mp3_url, headers=headers)data = http://kandian.youth.cn/index/response_2.json()保存数据def download(url, title):filename = 'D:\\python\\demo\\喜马拉雅\\FM\\' + title + '.mp3'response = requests.get(url=url, headers=headers)with open(filename, mode='wb') as f:f.write(response.content)print('{}下载完成'.format(title))运行代码 , 效果如下图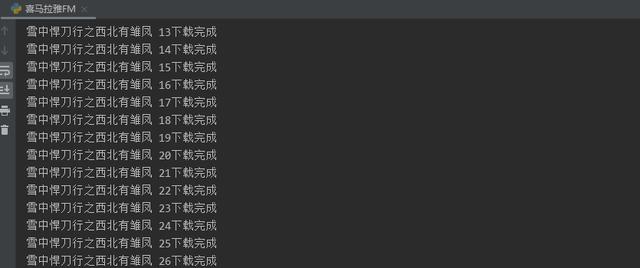 文章插图
文章插图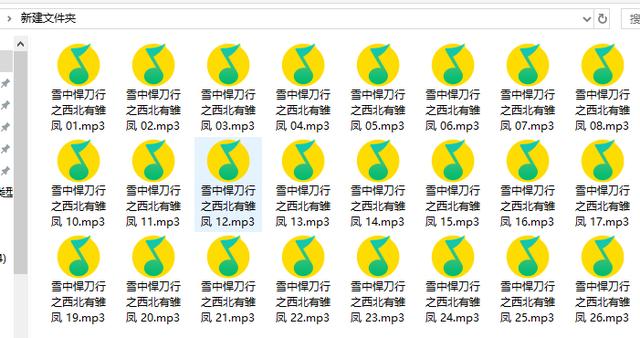 文章插图
文章插图- 苹果|要是不看真实数据,我还以为国产机将iPhone打成下一个三星了呢
- 量子计算|从微商到直播,一个顶流江湖的兴衰
- 倪光南|一个伟大的院士和真正的股东被欺负到扫地出门地步,公理何在?
- 小米科技|瑞典网友黑五网购电子产品,却只收到一个黑色小信封
- 酷睿处理器|华东理工耳机事件:学校“宽容”一个人,惹怒一群人,官媒沦陷
- 武汉|纸箱疯狂:诞生中国第一个女首富,电商一年要发百亿件
- 陈炳耀|39岁富三代靠开出租送外卖,拿下一个上市公司,市值400亿美金
- 龚文祥|从微商到直播,一个顶流江湖的兴衰
- iphone6|C++为什么比不上Java?
- nova|突发重磅:滴滴退市!这仅仅只是一个开始!