元数据管理-技术元数据解决方案
前言概念元数据是描述企业数据相关的数据 , 指在IT系统建设过程中所产生的有关数据定义 , 目标定义 , 转换规则等相关的关键数据 , 包括对数据的业务、结构、定义、存储、安全等各方面对数据的描述
元数据是数仓建设环节中不可缺少的一部分(尤其是在数据治理环节) , 是数据管理、数据内容、数据应用的基础 。 通过元数据可以打通数据源、数据仓库、数据应用、记录了数据流向的完整链路 。 它可以说是企业的数据地图 , 可以直接反映了企业中有什么样的数据 , 这些数据是如何存放的 , 以及数据之间的关系是如何的 。
分类参考Kimball的数仓模型理论 , 可以把元数据分为三类:
技术元数据 , 比如表结构、字段定义、文件存储等信息
业务元数据 , 比如业务定义、业务术语、业务规则、业务指标等
管理元数据 , 比如数据所有者、数据质量定责、数据安全等级等
链路整个元数据链路分为元数据采集、元数据管理、元数据应用 。
基于获取到的元数据可以实现血缘关系、权限的监控、全局监控数据完整生命周期等等 。
最后通过这些功能实现一般会形成产品化 , 比较常见的就是数据地图、数据检索和数据质量分析 。
技术元数据目前大多数公司的数仓建设是基于Hive进行的 , 而Hive又是依托于hadoop为引擎做存储计算 , 当然Hive元数据默认是存储在Derby数据库中的 , 不过在生产环境下一般都是改为mysql存储 。 本篇先为大家介绍一下技术元数据相关内容 , 以及结合笔者实际工作中使用到的场景进行结合讲解 。
首先大家先看一下整体的ER模型图(这里主要是想告诉大家涉及到表非常多 , 大家可以自行连接元数据库进行查看) , 不过这里只讲解几个比较常用的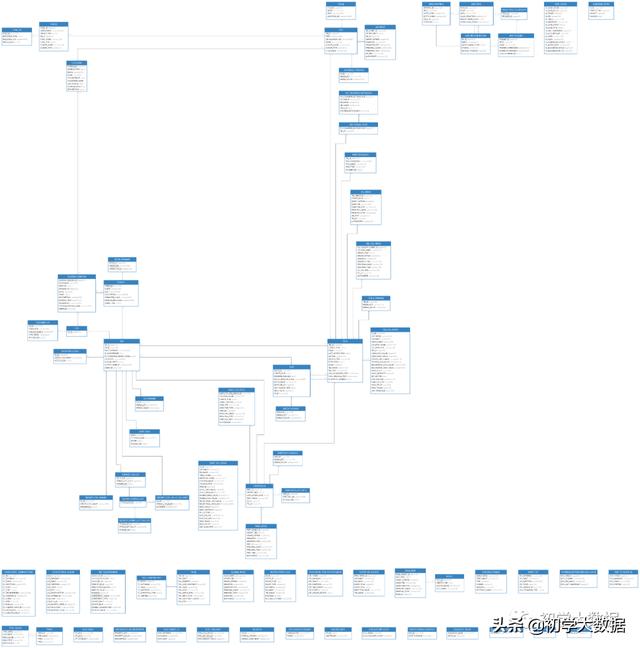 文章插图
文章插图
应用场景刚才简单提及到了元数据的相关应用 , 比如血缘关系、权限的监控、全局监控数据完整生命周期等等 。
这里笔者给出公司目前基于元数据所实现的一些功能 , 例如数据质量监控、数据地图等 。 因涉及到隐私安全问题 , 笔者给出一些截图供读者参考 , 主要是一些质控、元数据信息管理的功能 文章插图
文章插图 文章插图
文章插图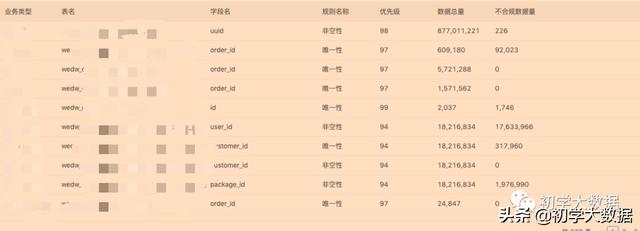 文章插图
文章插图
关于数据质量这块 , 后面会有单独的篇幅文章进行讲解 , 主要涉及到一些质控规则的内容
需求背景这里给出一个笔者正在做的一个需求并结合元数据进行讲解 , 以此来简述在日常工作中是如何使用元数据来帮助我们提升效率的 。
早期公司使用ELK采集日志并入仓 , 但随着业务规模扩张以及数据量的暴涨 , ELK这套体系显得过于笨重 , 且日志出入口比较复杂 , 为了统一采集入口 , 规范日志流程 , 提升日志数据质量 , 现将日志采集由logstash迁移至日志中心 , 由于采集的数据直接写入到了ods层 , 基于数据可靠性以及用户无感知的原则 , 在正式切换新老程序之前 , 需要比对数据一致(这里对原始ods表复制了一个新表 , 来存储新采集流程的数据) 。
那么这里就有了两个问题
如何对新老表进行比对来验证两个表数据一致呢?
由于ods层的表不止一两张 , 如何快速的比对呢?
需求开发基于上面的两个问题 , 笔者这里给出目前的解决方案 , 可能不是最优解 , 如果读者有好的解决方案可以随时交流
针对第一个问题 , 当两个表的数据量一致 , 且每个字段值也一致 , 那么才说明是两个表是一致的
对于数据量 , 其实就是通过count计算
对于每个字段的值比较 , 不可能人肉去比对 , 笔者这里是将所有字段做了一个拼接 , 然后取md5值 , 最后对md5值作比较
针对第二个问题 , 当对大量表做比对的时候 , 人肉方式是不可能的 , 否则绝对加班到昏天暗地 , 只能通过自动化脚本来实现 。
笔者将需要比对的表进行手动配置到一个文件 , 然后通过读取元数据的方式来自动完成拼接比对
那么具体的流程如下:
读取配置文件 , 获取新老表(即原表和新迁移后的表)
根据表名读取元数据获取所有的字段进行拼接(这里需要保证字段的顺序,而且需要注意元数据的更新情况) , 然后取md5值
然后就是sql拼接了 , 执行sql得到最后的比对结果 , 笔者这里是采用邮件发送的方式(整个耗时大概不到十分钟就完成了)
- OPPO|2199元,OPPOReno7SE,值得入手吗?
- saas|上半年的Redmi K40 Pro,现在入手2500元不到,还等?
- 酷比魔方|持续推进技术储备,网易星球区块链技术或成元宇宙入场券
- 彼尔姆|机器人公司想用 20 万美元「买断」你的脸,如果它足够友好
- 小米科技|顶级旗舰价格下跌,12GB+256GB+2K+50倍变焦,官方直降1300元
- OPPO|OPPO未来科技大会正式官宣,官方明示将有旗舰新品和创新技术亮相
- 索尼Xperia|力压iPhone13 Pro Max,续航排名第一,仅售1699元
- airpods3|这才是真相:柳传志退休金不是1亿,杨元庆年薪1.7亿比库克低,总部不在美国
- 支付宝|突破2项关键技术,中科院又立功了,事关量子计算和3D打印
- |跌至3099元!8GB运存+128GB+骁龙865,唯一缺陷不是新手机