Python爬虫采集网易云音乐热评实战( 二 )
到此为止 , 我们如何抓取网易云音乐的热门评论已经分析完了 , 我们再分析一下如何获取云音乐热歌榜中所有歌曲的信息 。
我们需要获取云音乐热歌榜中的所有歌曲的歌曲名和对应的id值 。 跟上面的分析步骤类似 , 我们先进入热歌榜的网址 , 如图: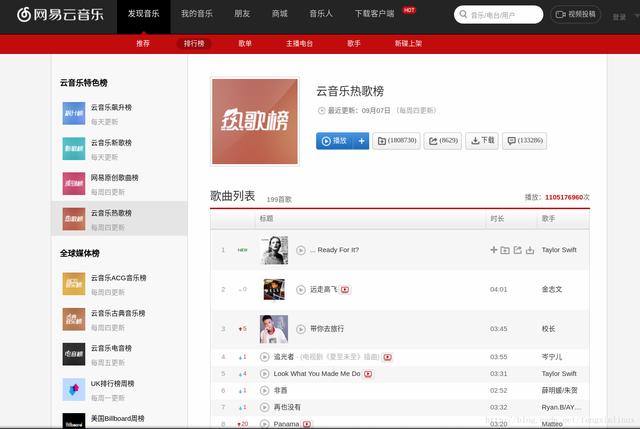 文章插图
文章插图
?
按F12 , 进入WEB工作台 , 如图: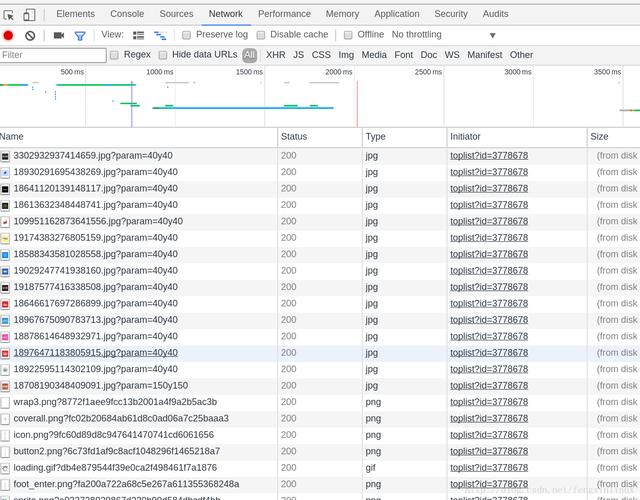 文章插图
文章插图
?
我们在一个名为toplist?id=3778678的GET请求中 , 找到了该榜单的所有歌曲信息 。
请求对应的信息如图: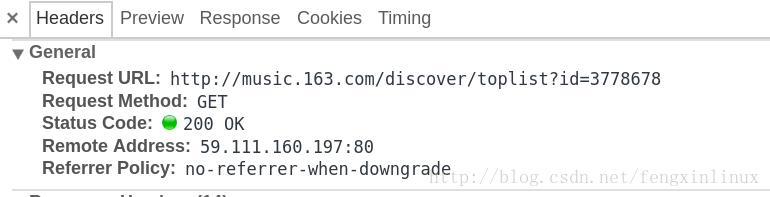 文章插图
文章插图
?
我们预览一下该请求返回的结果 , 如图: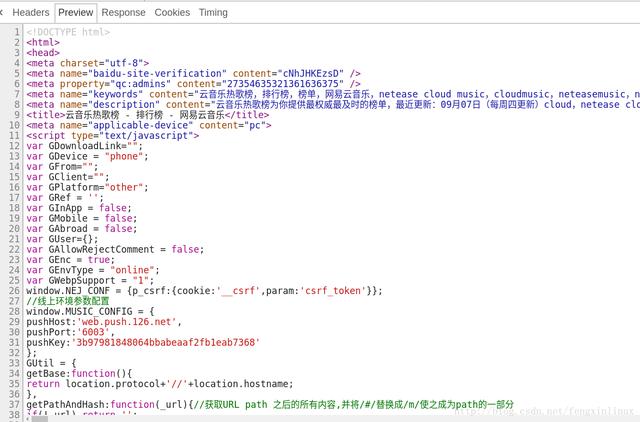 文章插图
文章插图
?
我们在代码的第524行我们找到了包含歌曲信息的代码 , 如图: 文章插图
文章插图
?
因此 , 我们只需要将该请求的代码中 , 将包含信息的代码筛选出来 。 我们在这里使用正则表达式进行数据筛选 。 通过观察特点 , 我们可以通过两次正则表达式的筛选 , 将我们需要的歌曲信息提取出来 。 第一次正则表达式我们将该请求返回的所有代码中 , 提取出第525行代码 。 第一次正则表达式如下:
- .*
第二次正则表达式我们将该第524行中我们需要的歌曲信息提取出来 , 我们需要歌曲的歌名和id , 对应的正则表达式如下:获取歌名:
到此 , 我们整个过程已经分析完了 , 上代码看具体细节~~代码如下:
#!/usr/bin/env python3# -*- coding: utf-8 -*-import reimport urllib.requestimport urllib.errorimport urllib.parseimport jsondef get_all_hotSong():#获取热歌榜所有歌曲名称和idurl=''#网易云云音乐热歌榜urlheader={#请求头部'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}request=urllib.request.Request(url=url, headers=header)html=urllib.request.urlopen(request).read().decode('utf8')#打开urlhtml=str(html)#转换成strpat1=r'- .*
'#进行第一次筛选的正则表达式result=re.compile(pat1).findall(html)#用正则表达式进行筛选result=result[0]#获取tuple的第一个元素pat2=r'(.*?) ' #进行歌名筛选的正则表达式pat3=r'.*? '#进行歌ID筛选的正则表达式hot_song_name=re.compile(pat2).findall(result)#获取所有热门歌曲名称hot_song_id=re.compile(pat3).findall(result)#获取所有热门歌曲对应的Idreturn hot_song_name,hot_song_iddef get_hotComments(hot_song_name,hot_song_id):url='' + hot_song_id + '?csrf_token='#歌评urlheader={#请求头部'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}#post请求表单数据data=http://kandian.youth.cn/index/{'params':'zC7fzWBKxxsm6TZ3PiRjd056g9iGHtbtc8vjTpBXshKIboaPnUyAXKze+KNi9QiEz/IieyRnZfNztp7yvTFyBXOlVQP/JdYNZw2+GRQDg7grOR2ZjroqoOU2z0TNhy+qDHKSV8ZXOnxUF93w3DA51ADDQHB0IngL+v6N8KthdVZeZBe0d3EsUFS8ZJltNRUJ','encSecKey':'4801507e42c326dfc6b50539395a4fe417594f7cf122cf3d061d1447372ba3aa804541a8ae3b3811c081eb0f2b71827850af59af411a10a1795f7a16a5189d163bc9f67b3d1907f5e6fac652f7ef66e5a1f12d6949be851fcf4f39a0c2379580a040dc53b306d5c807bf313cc0e8f39bf7d35de691c497cda1d436b808549acc'}postdata=http://kandian.youth.cn/index/urllib.parse.urlencode(data).encode('utf8')#进行编码request=urllib.request.Request(url,headers=header,data=http://kandian.youth.cn/index/postdata)reponse=urllib.request.urlopen(request).read().decode('utf8')json_dict=json.loads(reponse)#获取jsonhot_commit=json_dict['hotComments']#获取json中的热门评论num=0fhandle=open('./song_comments','a')#写入文件fhandle.write(hot_song_name+':'+'\n')for item in hot_commit:num+=1fhandle.write(str(num)+'.'+item['content']+'\n')fhandle.write('\n==============================================\n\n') fhandle.close()hot_song_name,hot_song_id=get_all_hotSong()#获取热歌榜所有歌曲名称和idnum=0while num < len(hot_song_name):#保存所有热歌榜中的热评print('正在抓取第%d首歌曲热评...'%(num+1))get_hotComments(hot_song_name[num],hot_song_id[num])print('第%d首歌曲热评抓取成功'%(num+1))num+=1代码运行结果如下: 文章插图
文章插图?
对比一下网页上《如果我爱你》这首歌的歌评和我们保存下的歌评:
 文章插图
文章插图
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?
- 十分钟教会你使用Python操作excel,内附步骤和代码