不想手动再配置logging?那可以试试loguru( 二 )
最后呈现如下: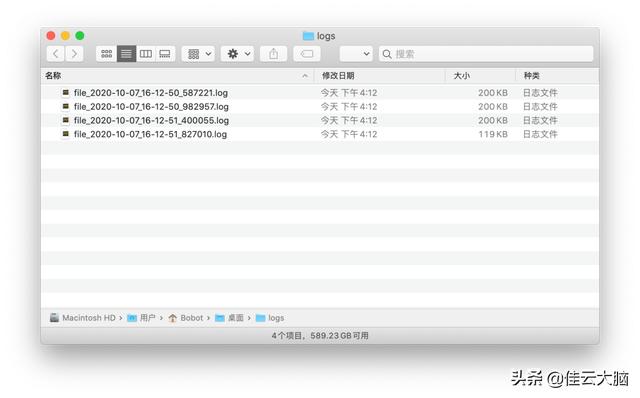 文章插图
文章插图
02-rotation
随着分割文件的数量越来越多之后 , 我们也可以进行压缩对日志进行留存 , 这里就要使用到compression 参数 , 该参数只要你传入通用的压缩文件扩展名即可 , 如 zip、tar、gz等 。
import osfrom loguru import loggerLOG_DIR = os.path.expanduser("~/Desktop/logs")LOG_FILE = os.path.join(LOG_DIR, "file_{time}.log")if os.path.exits(LOG_DIR):os.mkdir(LOG_DIR)logger.add(LOG_FILE, rotation = "200KB", compression="zip")for n in range(10000):logger.info(f"test - {n}")从结果可以看到 , 只要是满足了 rotation 分割后的日志文件都被直接压缩成了 zip 文件 , 文件大小由原本的 200kb 直接减少至 10kb , 对于一些磁盘空间吃紧的 Linux 服务器来说是则是很有必要的 。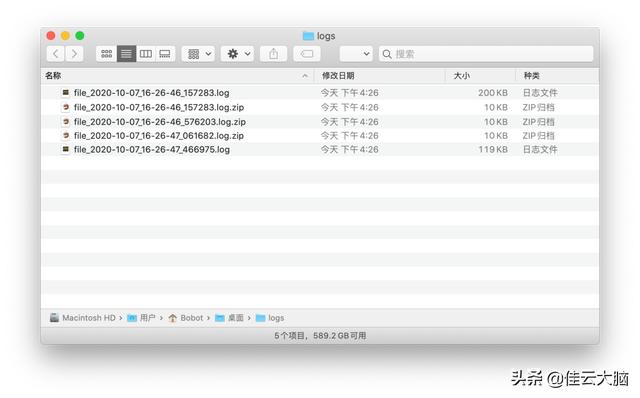 文章插图
文章插图
03-compression
当然了 , 如果你不想对日志进行留存 , 或者只想保留一段时间内的日志并对超期的日志进行删除 , 那么直接使用 retention 参数就好了 。
这里我们可以将之前的结果随意复制 N 多份在 logs 文件夹中 , 然后再执行一次加上 retension 参数后代码:
from loguru import loggerLOG_DIR = os.path.expanduser("~/Desktop/logs")LOG_FILE = os.path.join(LOG_DIR, "file_{time}.log")if not os.path.exists(LOG_DIR):os.mkdir(LOG_DIR)logger.add(LOG_FILE, rotation="200KB",retention=1)for n in range(10000):logger.info(f"test - {n}")当然对 retention 传入整数时 , 该参数表示的是所有文件的索引 , 而非要保留的文件数 , 这里是个反直觉的小坑 , 用的时候注意一下就好了 。 所以最后我们会看到只有两个时间最近的日志文件会被保留下来 , 其他都被直接清理掉了 。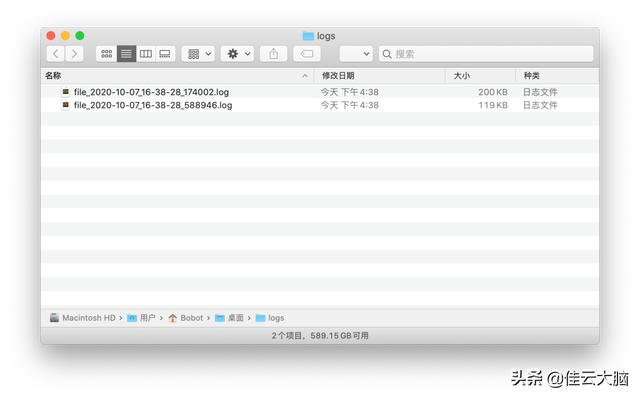 文章插图
文章插图
04-retention
3、序列化如果在实际中你不太喜欢以文件的形式保留日志 , 那么你也可以通过 serialize 参数将其转化成序列化的 json 格式 , 最后将导入类似于 MongoDB、ElasticSearch 这类数 NoSQL 数据库中用作后续的日志分析 。
from loguru import loggerimport oslogger.add(os.path.expanduser("~/Desktop/testlog.log"), serialize=True)logger.info("hello, world!")最后保存的日志都是序列化后的单条记录:
{"text": "2020-10-07 18:23:36.902 | INFO| __main__:4、异常追溯当异常和错误不可避免时 , 最好的方式就是让我们知道程序到底是哪里出了错 , 或者是因为什么导致错误 , 这样才能更好地让开发人员及时应对并解决 。
loguru 集成了一个名为 better_exceptions 的库 , 不仅能够将异常和错误记录 , 并且还能对异常进行追溯 , 这里是来自一个官网的例子
import osimport sysfrom loguru import loggerlogger.add(os.path.expanduser("~/Desktop/exception_log.log"), backtrace=True, diagnose=True)def func(a, b):return a / bdef nested(c):try:func(5, c)except ZeroDivisionError:logger.exception("What?!")if __name__ == "__main__":nested(0)最后在日志文件中我们可以得到以下内容:
2020-10-07 21:14:11.830 | ERROR| __main__:nested:16 - What?!Traceback (most recent call last):File "/Users/Bobot/PycharmProjects/docs-python/src/loguru/log_test.py", line 20, in 与 Logging 完全兼容(Entirely Compatible)尽管说 loguru 算是重新「造轮子」 , 但是它也能和 logging 库很好地兼容 。 到现在我们才谈论到 add() 方法的第一个参数 sink 。
这个参数的英文单词动词有「下沉、浸没」等意 , 对于外国人来说在理解上可能没什么难的 , 可对我们国人来说 , 这可之前 logging 库中的 handler 概念还不好理解 。 好在前面我有说过 , loguru 和 logging 库的使用上存在相似之处 , 因此在后续的使用中其实我们就可以将其理解为 handler , 只不过它的范围更广一些 , 可以除了 handler 之外的字符串、可调用方法、协程对象等 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 再见|2020年:三星S20再见了!2021年:三星S21我来了!
- 任正非|任正非:“谁再建言造车,直接调离岗位!”华为为何这么做?
- 屏幕|不想换iPhone 12手机就等一等吧!iPhone 13开始露出峥嵘
- 对焦速度|Mate40Pro之后,华为还有“硬菜”,或将再次领先行业?
- 关闭|虾米音乐的关闭,再次应证了互联网下竞争的规则,小而精很难生存