Python数据分析:Jupyter Notebook 讲解( 二 )
在启动MongoDB服务后 , 运行Python代码 , 运行完成后 , 再通过Robo 3T查看数据库如下: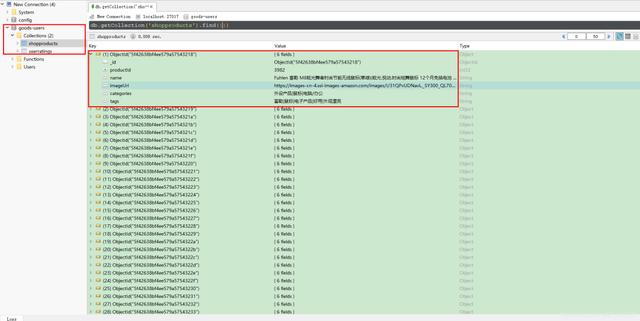 文章插图
文章插图
显然 , 保存数据成功 。
使用Jupyter处理商铺数据
待处理的数据是商铺数据 , 如下: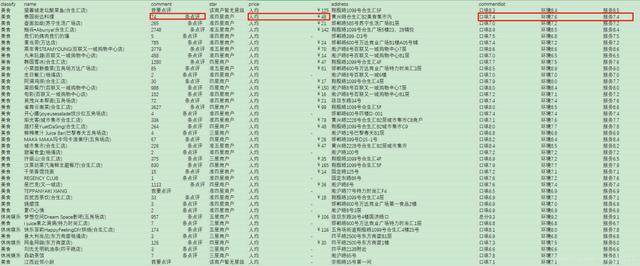 文章插图
文章插图
包括名称、评论数、价格、地址、评分列表等 , 其中评论数、价格和评分均不规则、需要进行数据清洗 。
Jupyter中处理如下: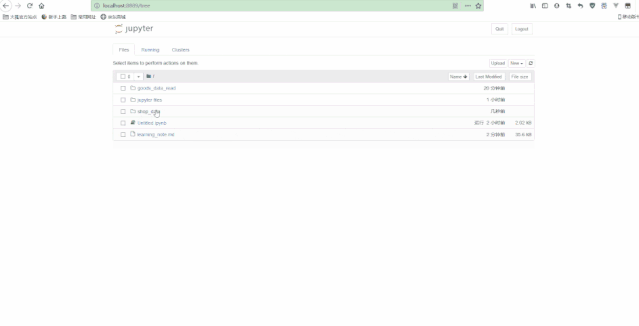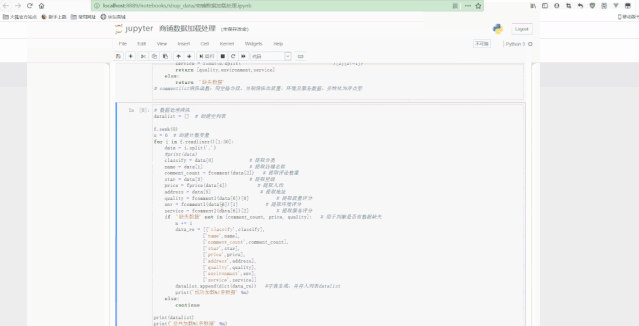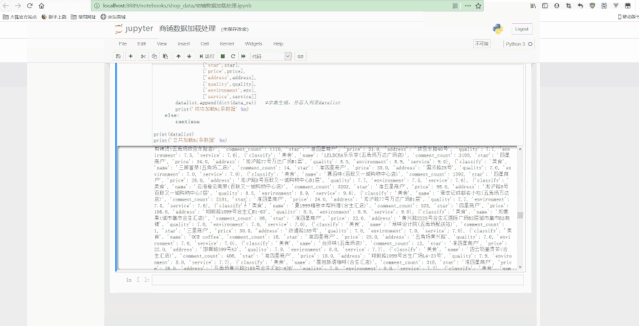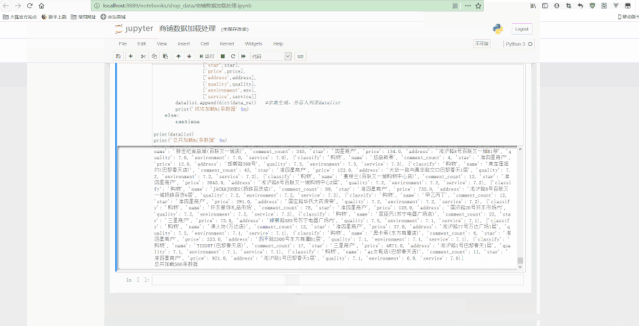 文章插图
文章插图
可以看到 , 最后得到了经过清洗后的规则数据 。
完整Python代码如下:
## 数据读取f = open('商铺数据.csv', 'r', encoding='utf8')for i in f.readlines()[1:15]:print(i.split(','))## 创建comment、price、commentlist清洗函数def fcomment(s):'''comment清洗函数:用空格分段 , 选取结果list的第一个为点评数 , 并且转化为整型'''if '条' in s:return int(s.split(' ')[0])else:return '缺失数据'def fprice(s):'''price清洗函数:用¥分段 , 选取结果list的最后一个为人均价格 , 并且转化为浮点型'''if '¥' in s:return float(s.split('¥')[-1])else:return '缺失数据'def fcommentl(s):'''commentlist清洗函数:用空格分段 , 分别清洗出质量、环境及服务数据 , 并转化为浮点型'''if ' ' in s:quality = float(s.split('')[0][2:])environment = float(s.split('')[1][2:])service = float(s.split('')[2][2:-1])return [quality, environment, service]else:return '缺失数据'## 数据处理清洗datalist = []## 创建空列表f.seek(0)n = 0## 创建计数变量for i in f.readlines():data = http://kandian.youth.cn/index/i.split(',')## print(data)classify = data[0]## 提取分类name = data[1]## 提取店铺名称comment_count = fcomment(data[2])## 提取评论数量star = data[3]## 提取星级price = fprice(data[4])## 提取人均address = data[5]## 提取地址quality = fcommentl(data[6])[0]## 提取质量评分env = fcommentl(data[6])[1]## 提取环境评分service = fcommentl(data[6])[2]## 提取服务评分if '缺失数据' not in [comment_count, price, quality]:## 用于判断是否有数据缺失n += 1data_re = [['classify', classify],['name', name],['comment_count', comment_count],['star', star],['price', price],['address', address],['quality', quality],['environment', env],['service', service]]datalist.append(dict(data_re))## 字典生成 , 并存入列表datalistprint('成功加载%i条数据' % n)else:continueprint(datalist)print('总共加载%i条数据' % n)f.close()
- 框架|三种数据分析思维框架的构建方法
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?