Elasticsearch查询速度为什么这么快?( 二 )
这个数据结构不像是二叉树那样大学老师当做基础数据结构经常讲到 , 由于这类数据结构都是在实际工程中根据需求场景在基础数据结构中演化而来 。
比如这里的 B+ 树就可以认为是由平衡二叉树演化而来 。 刚才我们提到二叉树的区间查询效率不高 , 针对这一点便可进行优化: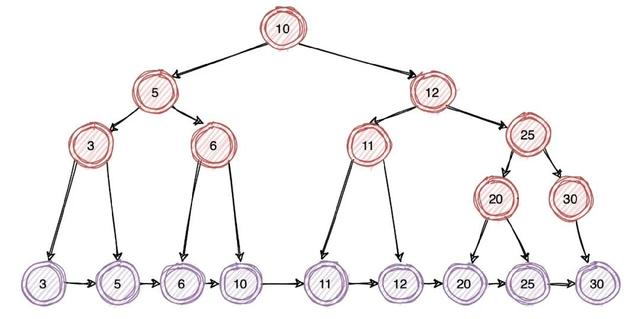 文章插图
文章插图
在原有二叉树的基础上优化后:所有的非叶子都不存放数据 , 只是作为叶子节点的索引 , 数据全部都存放在叶子节点 。
这样所有叶子节点的数据都是有序存放的 , 便能很好的支持区间查询 。 只需要先通过查询到起始节点的位置 , 然后在叶子节点中依次往后遍历即可 。
当数据量巨大时 , 很明显索引文件是不能存放于内存中 , 虽然速度很快但消耗的资源也不小;所以 MySQL 会将索引文件直接存放于磁盘中 。
这点和后文提到 Elasticsearch 的索引略有不同 。 由于索引存放于磁盘中 , 所以我们要尽可能的减少与磁盘的 IO(磁盘 IO 的效率与内存不在一个数量级) 。
通过上图可以看出 , 我们要查询一条数据至少得进行 4 次IO , 很明显这个 IO 次数是与树的高度密切相关的 , 树的高度越低 IO 次数就会越少 , 同时性能也会越好 。
那怎样才能降低树的高度呢?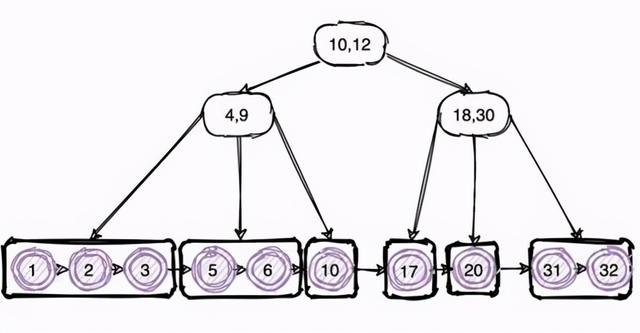 文章插图
文章插图
我们可以尝试把二叉树变为三叉树 , 这样树的高度就会下降很多 , 这样查询数据时的 IO 次数自然也会降低 , 同时查询效率也会提高许多 。 这其实就是 B+ 树的由来 。
使用索引的一些建议其实通过上图对 B+树的理解 , 也能优化日常工作的一些小细节;比如为什么需要最好是有序递增的?
假设我们写入的主键数据是无序的 , 那么有可能后写入数据的 id 小于之前写入的 , 这样在维护 B+树索引时便有可能需要移动已经写好数据 。
如果是按照递增写入数据时则不会有这个考虑 , 每次只需要依次写入即可 。 所以我们才会要求数据库主键尽量是趋势递增的 , 不考虑分表的情况时最合理的就是自增主键 。
整体来看思路和跳表类似 , 只是针对使用场景做了相关的调整(比如数据全部存储于叶子节点) 。
ES 索引MySQL 聊完了 , 现在来看看 Elasticsearch 是如何来使用索引的 。
正排索引在 ES 中采用的是一种名叫倒排索引的数据结构;在正式讲倒排索引之前先来聊聊和他相反的正排索引 。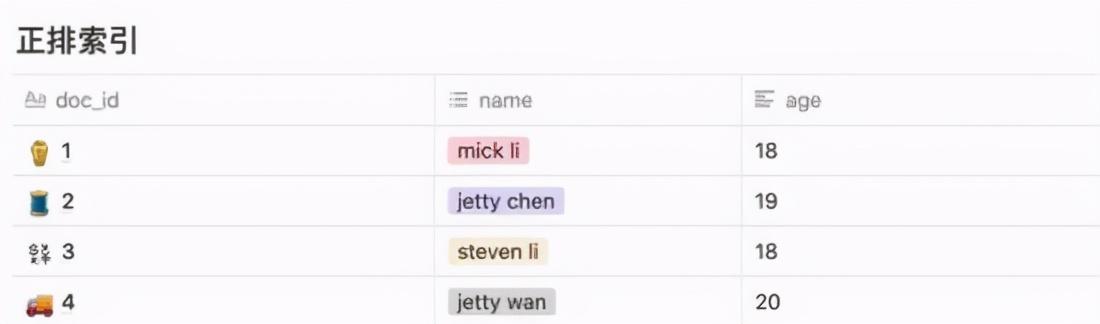 文章插图
文章插图
以上图为例 , 我们可以通过 doc_id 查询到具体对象的方式称为使用正排索引 , 其实也能理解为一种散列表 。
本质是通过 key 来查找 value 。 比如通过 doc_id=4 便能很快查询到 name=jetty wang , age=20 这条数据 。
倒排索引那如果反过来我想查询 name 中包含了 li 的数据有哪些?这样如何高效查询呢?
仅仅通过上文提到的正排索引显然起不到什么作用 , 只能依次将所有数据遍历后判断名称中是否包含 li ;这样效率十分低下 。
但如果我们重新构建一个索引结构: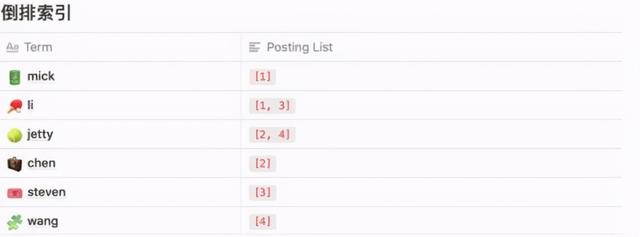 文章插图
文章插图
当要查询 name 中包含 li 的数据时 , 只需要通过这个索引结构查询到 Posting List 中所包含的数据 , 再通过映射的方式查询到最终的数据 。
这个索引结构其实就是倒排索引 。
Term Dictionary但如何高效的在这个索引结构中查询到 li 呢 , 结合我们之前的经验 , 只要我们将 Term 有序排列 , 便可以使用二叉树搜索树的数据结构在 o(logn) 下查询到数据 。
将一个文本拆分成一个一个独立Term 的过程其实就是我们常说的分词 。
而将所有 Term 合并在一起就是一个 Term Dictionary , 也可以叫做单词词典 。
英文的分词相对简单 , 只需要通过空格、标点符号将文本分隔便能拆词 , 中文则相对复杂 , 但也有许多开源工具做支持(由于不是本文重点 , 对分词感兴趣的可以自行搜索) 。
当我们的文本量巨大时 , 分词后的 Term 也会很多 , 这样一个倒排索引的数据结构如果存放于内存那肯定是不够存的 , 但如果像 MySQL 那样存放于磁盘 , 效率也没那么高 。
Term Index所以我们可以选择一个折中的方法 , 既然无法将整个 Term Dictionary 放入内存中 , 那我们可以为 Term Dictionary 创建一个索引然后放入内存中 。
这样便可以高效的查询 Term Dictionary, 最后再通过 Term Dictionary 查询到 Posting List 。
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 硬盘|七八年前的电脑,运行速度缓慢,卡顿,更换两个硬件就能快如闪电
- 加急|古代8百里加急究竟有多快?需要骑马20个小时,速度媲美顺丰快递!
- 公园|长沙五一广场、烈士公园…湖南5G速度最快的地方是?
- P50|全新液体镜头专利:华为P50系列首发人眼级对焦速度
- 5G|5G速度到底有多快?用过这些手机你才知道
- 对焦速度|Mate40Pro之后,华为还有“硬菜”,或将再次领先行业?
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 不到|半分钟不到,一部手机生产出来了,这就是中国速度、华为速度