史上最全Python反爬虫方案汇总
通过User-Agent来控制访问无论是浏览器还是爬虫程序 , 在向服务器发起网络请求的时候 , 都会发过去一个头文件:headers , 比如知乎的requests headers
这里面的大多数的字段都是浏览器向服务器”表明身份“用的
对于爬虫程序来说 , 最需要注意的字段就是:User-Agent
很多网站都会建立 user-agent白名单 , 只有属于正常范围的user-agent才能够正常访问 。
爬虫方法:【史上最全Python反爬虫方案汇总】可以自己设置一下user-agent , 或者更好的是 , 可以从一系列的user-agent里随机挑出一个符合标准的使用 。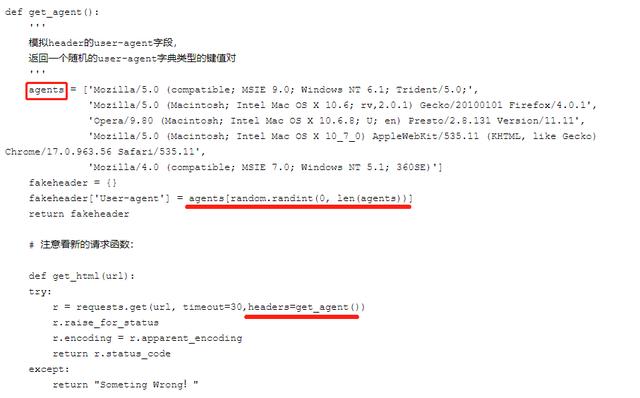 文章插图
文章插图
缺点:容易容易伪造头部 , github上有人分享开源库fake-useragent
实现难度:★IP限制如果一个固定的ip在短暂的时间内 , 快速大量的访问一个网站 , 后台管理员可以编写IP限制 , 不让该IP继续访问 。
爬虫方法:比较成熟的方式是:IP代理池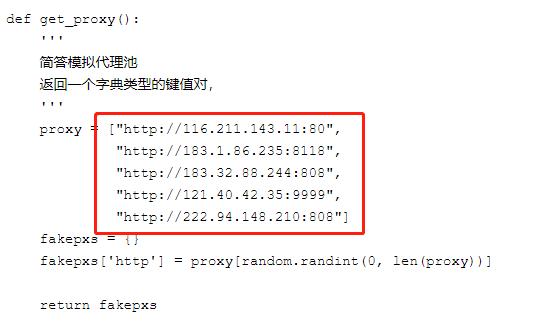 文章插图
文章插图
简单的说 , 就是通过ip代理 , 从不同的ip进行访问 , 这样就不会被封掉ip了 。
可是ip代理的获取本身就是一个很麻烦的事情 , 网上有免费和付费的 , 但是质量都层次不齐 。 如果是企业里需要的话 , 可以通过自己购买集群云服务来自建代理池 。
缺点:可以使用免费/付费代理 , 绕过检测 。
实现难度:★SESSION访问限制后台统计登录用户的操作 , 比如短时间的点击事件 , 请求数据事件 , 与正常值比对 , 用于区分用户是否处理异常状态 , 如果是 , 则限制登录用户操作权限 。
缺点:需要增加数据埋点功能 , 阈值设置不好 , 容易造成误操作 。
爬虫方法:注册多个账号、模拟正常操作 。
实现难度:★★★Spider Trap蜘蛛陷阱导致网络爬虫进入无限循环之类的东西 , 这会浪费蜘蛛的资源 , 降低其生产力 , 并且在编写得不好的爬虫的情况下 , 可能导致程序崩溃 。 礼貌蜘蛛在不同主机之间交替请求 , 并且不会每隔几秒钟从同一服务器请求多次文档 , 这意味着“礼貌”网络爬虫比“不礼貌”爬虫的影响程度要小得多 。
反爬方式:
- 创建无限深度的目录结构
- 动态页面 , 为网络爬虫生成无限数量的文档 。 如由算法生成杂乱的文章页面 。
- 文档中填充了大量字符 , 使解析文档的词法分析器崩溃 。
爬虫方法:把网页按照所引用的css文件进行聚类 , 通过控制类里最大能包含的网页数量防止爬虫进入trap后出不来 , 对不含css的网页会给一个penalty , 限制它能产生的链接数量 。 这个办法理论上不保证能避免爬虫陷入死循环 , 但是实际上这个方案工作得挺好 , 因为绝大多数网页都使用了css , 动态网页更是如此 。
缺点:反爬方式1 , 2会增加很多无用目录或文件 , 造成资源浪费 , 也对正常的SEO十分不友好 , 可能会被惩罚 。
实现难度:★★★验证码验证验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写 , 是一种区分用户是计算机还是人的公共全自动程序 。 可以防止:恶意破解密码、刷票、论坛灌水 , 有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试 , 实际上用验证码是现在很多网站通行的方式 , 我们利用比较简易的方式实现了这个功能 。 这个问题可以由计算机生成并评判 , 但是必须只有人类才能解答 。 由于 计算机无法解答CAPTCHA的问题 , 所以回答出问题的用户就可以被认为是人类 。
1. 图片验证码
- 复杂型
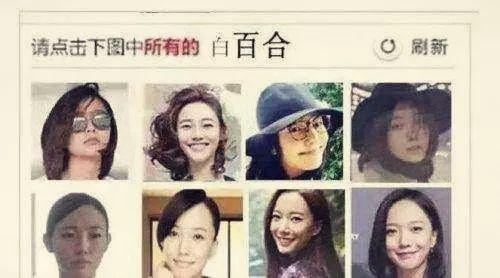 文章插图
文章插图打码平台雇佣了人力 , 专门帮人识别验证码 。 识别完把结果传回去 。 总共的过程用不了几秒时间 。 这样的打码平台还有记忆功能 。 图片被识别为“锅铲”之后 , 那么下次这张图片再出现的时候 , 系统就直接判断它是“锅铲” 。 时间一长 , 图片验证码服务器里的图片就被标记完了 , 机器就能自动识别了 。
- 简单型
 文章插图
文章插图
- 广告点击|广告效果评估:30天的广告时间评估最全面
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析
- 史上最短命旗舰!为了华为P50:Mate40部分机型疑似停产
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础