Rust能不能做后端开发语言?( 二 )
VS Code的Rust插件
RESTful vs GraphQL通过Rust实现RESTful规范的接口 , 整体来说还是比较直观的 , Rust下比较流行的第三方Web开发框架都会支持路由功能 , 虽然不同的框架支持的方式不同 , 不过本质上都是通过挂载一个根路径 , 然后通过框架支持的Macro来将不同路径来指向不同函数来处理 , 我是用Rocket来做这个RESTful接口的Demo的 , 除了Rocket服务器启动和根目录挂载基本上 , 就是三行如下的代码就可以设置好一条路径:
#[get("/herb/当然可以将所有路由放在一个模块内 , 然后在主程序内调用 , 类似如下的启动Rocket服务器就可以运行了
fn main() {rocket::ignite().mount("/", routes![routes::get_herb]).launch();}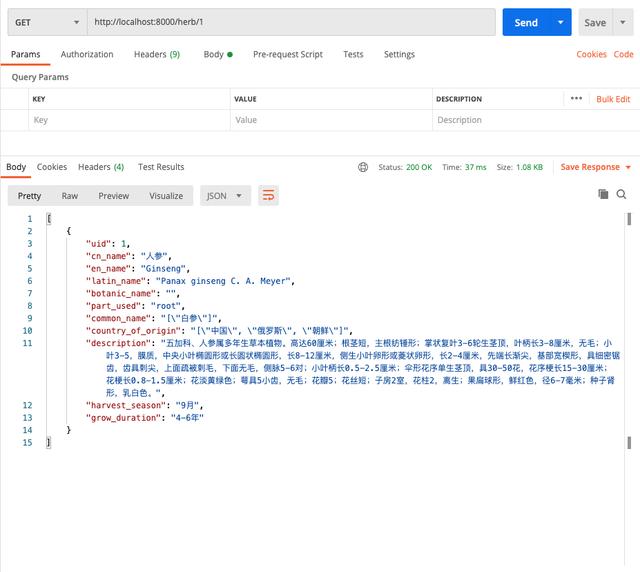 文章插图
文章插图
RESTful接口demo的测试结果
对于GraphQL来说设置上会稍微复杂一点 , 需要通过第三方的GraphQL库来实现 , 我使用了Juniper , 同时尝试了另一个Web开发框架Actix-Web , 整体开发效率还是非常快的 , 主要还是得益于Rust的Macro机制 , 基本上很多方法都通过Macro来关联到了相应的对象上 , 直接在需要的地方调用就可以了 。 不过对于GraphQL要多一步设置Schema的过程 , 不过对于处理函数的添加还是比较直观的 , 比之前使用Go的时候要更便于维护 。 在设置完Schema之后 , 只需要在RootQuery中添加相应的函数就能实现不同的业务逻辑 , 如下面包含两个函数 , 调用全部对象和查询单一对象的函数:
#[juniper::object]impl QueryRoot {fn herbs() -> Vec {use crate::schema::herbs::dsl::*;let connection = establish_connection();herbs.limit(100).load::(let connection = establish_connection();herbs.filter(uid.eq(_uid)).load::( --tt-darkmode-bgcolor: #161616;">经过这两个不同规范的 , Rust高开发效率的特性非常好的体现了 , 只要熟悉了Rust语言规范之后 , 整体开发效率还是非常高的 , 很多代码会通过Macro机制省略了 。 如果选择Rust的话 , 感觉使用GraphQL的机会会更高 , 毕竟RESTful和GraphQL之间的开发成本差不多 , 那么GraphQL的自由度就更高了 。
数据库连接 文章插图
文章插图
Diesel使用起来还是比较方便的
我使用了Diesel这个比较流行的数据库连接框架 , 是设置和初始化的过程中 , 体现出了Rust比较类似其他系统语言的地方 , 在安装了Diesel命令行工具之后 , 只需要通过下面几行命令行就能直接设置好数据库以及migration的配置
//安装diesel_cli , 最后的参数是根据使用的数据库来设置的>cargo install diesel_cli --no-default-features --features mysql//将数据库连接数据添加到项目根目录的.env文件中>echo DATABASE_URL=mysql://username:password@localhost/database_name > .env//然后设置就可以了>diesel setup这样diesel会了连接到数据库服务器 , 如果数据库不存在的时候 , 会自动生成一个数据库 。 然后通过新建一个migration来添加数据库中的表
【Rust能不能做后端开发语言?】>diesel migration generate migration_name这样就会在项目根目录下migrations文件下生成当前时间为前缀的文件夹 , 其中有两个文件 , up.sql 存放新建表需要的sql语句 , down.sql存放up.sql内相关新建语句的销毁语句 , 例如:
//up.sqlCREATE TABLE IF NOT EXISTS herbs (uid int PRIMARY KEY AUTO_INCREMENT,cn_name varchar(255) NOT NULL,en_name varchar(255) DEFAULT NULL,latin_name varchar(255) NOT NULL,botanic_name varchar(255) DEFAULT NULL,part_used varchar(255) NOT NULL,common_name json DEFAULT NULL,country_of_origin json DEFAULT NULL,description text,harvest_season varchar(255) DEFAULT NULL,grow_duration varchar(255) DEFAULT NULL)//down.sqlDROP TABLE herbs添加好相应的SQL语句 , 在运行如下命令就基本上设置好了Diesel
>diesel migration run也可以通过以下命令来重置数据库
>diesel migration redoDiesel会直接在项目根目录下的schema.rs文件中根据数据库表的结构生成好相应的数据结构 。 然后通过diesel支持的Macro , 建立同样结构的struct就可以直接调用数据库中的数据条了 。 例如对于可以查询的数据条 , 可以在struct定义之上添加如下的Macro
#[derive(Queryable)]struct Herb {uid: i32,cn_name: String,en_name: String,latin_name: String,botanic_name: String,part_used: String,common_name: String,country_of_origin: String,description: String,harvest_season: String,grow_duration: String,}这样就可以直接通过在相应的业务逻辑中通过filter , load等查询函数了 。
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- Note9|0点首销!Redmi Note9系列这几点你怎能不心动?
- 盒马鲜生能不能逃过易果生鲜的下场?
- 明基E582智能投影仪上手体验,无智能不商务的办公新宠儿
- 第23问:3节点MGR集群,能不能将一个节点放在地球另一端?
- Rust的不足之处,让它无法成为一门成熟的编程语言
- 域名|【声音】美国到底能不能给中国断网?
- 3块多的PSP卡套能不能用?实测很好用,让我的PSP又复活了
- 台积|台积电、中芯国际、ASML三家的大股东是谁?说出来你可能不信
- 不行|电脑运行慢并不是它的性能不行,关掉一个开关,让你电脑飞起来