五种IO模型详解( 二 )
2 I/O模型所谓的IO模型 , 描述的是出现I/O等待时进程的状态以及处理数据的方式 。 围绕着进程的状态、数据准备到kernel buffer再到app buffer的两个阶段展开 。 其中数据复制到kernel buffer的过程称为数据准备阶段 , 数据从kernel buffer复制到app buffer的过程称为数据复制阶段 。 请记住这两个概念 , 后面描述I/O模型时会一直用这两个概念 。
本文某些地方以httpd进程的TCP连接方式处理本地文件为例 , 请无视httpd是否真的实现了如此、那般的功能 , 也请无视TCP连接处理数据的细节 , 这里仅仅只是作为方便解释的示例而已 。
再次说明 , 从硬件设备到内存的数据传输过程是不需要CPU参与的 , 而内存间传输数据是需要内核线程占用CPU来参与的 。
2.1 Blocking I/O模型如图: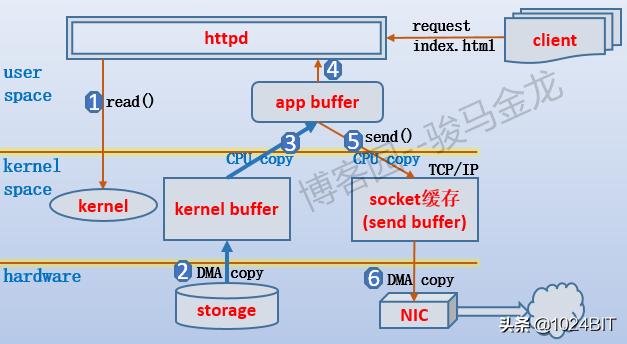 文章插图
文章插图
假设客户端发起index.html的文件请求 , httpd需要将index.html的数据从磁盘中加载到自己的httpd app buffer中 , 然后复制到send buffer中发送出去 。
但是在httpd想要加载index.html时 , 它首先检查自己的app buffer中是否有index.html对应的数据 , 没有就发起系统调用让内核去加载数据 , 例如read() , 内核会先检查自己的kernel buffer中是否有index.html对应的数据 , 如果没有 , 则从磁盘中加载 , 然后将数据准备到kernel buffer , 再复制到app buffer中 , 最后被httpd进程处理 。
如果使用Blocking I/O模型:
(1).当设置为blocking i/o模型 , httpd从到都是被阻塞的 。
(2).只有当数据复制到app buffer完成后 , 或者发生了错误 , httpd才被唤醒处理它app buffer中的数据 。
(3).cpu会经过两次上下文切换:用户空间到内核空间再到用户空间 , 第一次是发起系统调用的切换 , 第二次是内核将数据拷贝到app buffer完成后的切换 。
(4).由于阶段的拷贝是不需要CPU参与的 , 所以在阶段准备数据的过程中 , cpu可以去处理其它进程的任务 。
(5).阶段的数据复制需要CPU参与 , 将httpd阻塞 。
(6).这是最省事、最简单的IO模式 。
如下图: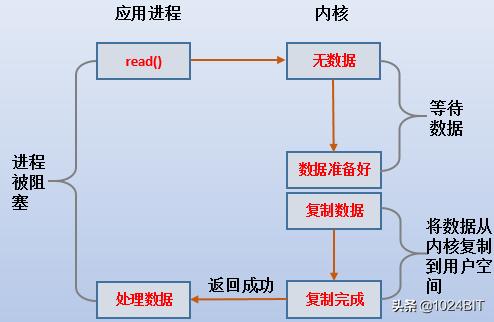 文章插图
文章插图
2.2 Non-Blocking I/O模型(1).当设置为non-blocking时 , httpd第一次发起系统调用(如read())后 , 立即返回一个错误值EWOULDBLOCK , 而不是让httpd进入睡眠状态 。 UNP中也正是这么描述的 。
When we set a socket to be nonblocking, we are telling the kernel "when an I/O operation that I request cannot be completed without putting the process to sleep, do not put the process to sleep, but return an error instead.
(2).虽然read()立即返回了 , 但httpd还要不断地去发送read()检查内核:数据是否已经成功拷贝到kernel buffer了?这称为轮询(polling) 。 每次轮询时 , 只要内核没有把数据准备好 , read()就返回错误信息EWOULDBLOCK 。
(3).直到kernel buffer中数据准备完成 , 再去轮询时不再返回EWOULDBLOCK , 而是将httpd阻塞 , 以等待数据复制到app buffer 。
(4).httpd在到阶段不被阻塞 , 但是会不断去发送read()轮询 。 在被阻塞 , 将cpu交给内核把数据copy到app buffer 。
如下图: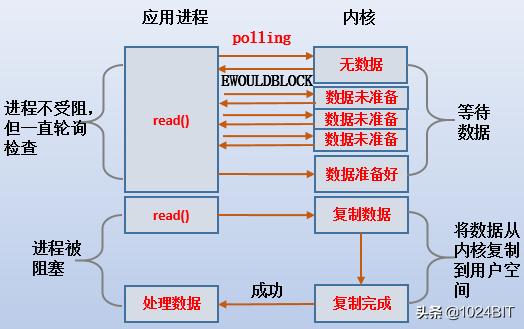 文章插图
文章插图
2.3 I/O Multiplexing模型称为多路IO模型或IO复用 , 意思是可以检查多个IO等待的状态 。 有三种IO复用模型:select、poll和epoll 。 其实它们都是一种函数 , 用于监控指定文件描述符的数据是否就绪 。
就绪指的是对某个系统调用不再阻塞了 , 可以直接执行IO 。 例如对于read()来说 , 数据准备好了就是就绪状态 , 此时read()可以直接去读取数据且能立即读取到数据 , 对write()来说 , 就是有空间可以写入数据了(比如缓冲区未满) , 此时write()可以直接写入 。
就绪种类包括是否可读、是否可写以及是否异常 , 其中可读条件中就包括了数据是否准备好 , 也即数据是否已经在kernel buffer中 。 当就绪之后 , 将通知进程 , 进程再发送对数据操作的系统调用 , 如read() 。
所以 , 这三个函数仅仅只是处理了数据是否准备好以及如何通知进程的问题 。 可以将这几个函数结合阻塞和非阻塞IO模式使用 , 但通常IO复用都会结合非阻塞IO模式 。
select()和poll()差不多 , 它们的监控和通知手段是类似的 , 只不过poll()要更聪明一点 , 某些时候效率也更高些 , 此处仅以select()监控单个文件请求为例简单介绍IO复用 , 至于更具体的、监控多个文件以及epoll的方式 , 在本文的最后专门解释 。
(1).当想要加载某个文件时 , 假如httpd要发起read()系统调用 , 如果是阻塞或者非阻塞情形 , 那么read()会根据数据是否准备好而决定是否返回 。 是否可以主动去监控这个数据是否准备到了kernel buffer中呢 , 亦或者是否可以监控send buffer中是否有新数据进入呢?这就是select()/poll()/epoll的作用 。
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 编程猫领衔,9家编程app测评一览详解
- 详解m3u8协议
- Django实战016:django中使用redis详解
- 「数据架构」TOGAF建模:概念数据模型图
- redis 数据类型详解 以及 redis适用场景场合
- 安卓面试必备的JVM虚拟机制详解,看完之后简历上多一个技能
- 这样和妻子解释:Java动态代理机制详解(JDK和CGLIB
- 详解command设计模式,解耦操作和回滚
- 详解mysql执行计划