深入理解Netty编解码、粘包拆包、心跳机制( 三 )
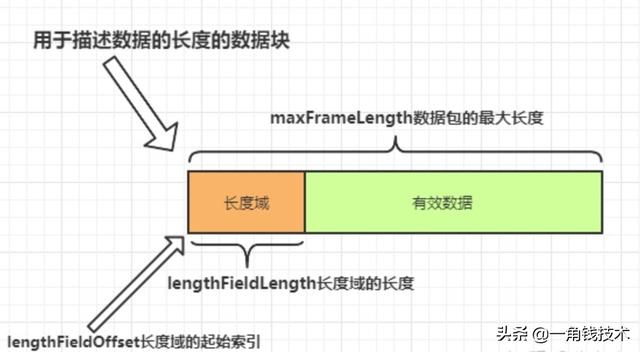 文章插图
文章插图矫正偏移量是什么意思呢?
是假设你的长度域设置的值除了包括有效数据的长度还有其他域的长度包含在里面 , 那么就要设置这个值进行矫正 , 否则解码器拿不到有效数据 。
丢弃的起始字节数 。 这个比较简单 , 就是在这个索引值前面的数据都丢弃 , 只要后面的数据 。 一般都是丢弃长度域的数据 。 当然如果你希望得到全部数据 , 那就设置为0 。
下面就在消息接收端使用自定义长度帧解码器 , 解决粘包的问题:
@Overrideprotected void initChannel(SocketChannel ch) throws Exception { //数据包最大长度是1024//长度域的起始索引是0//长度域的数据长度是4//矫正值为0 , 因为长度域只有 有效数据的长度的值//丢弃数据起始值是4 , 因为长度域长度为4 , 我要把长度域丢弃 , 才能得到有效数据ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024, 0, 4, 0, 4));ch.pipeline().addLast(new TcpClientHandler());}接着编写发送端代码 , 根据解码器的设置 , 进行发送:@Overridepublic void channelActive(ChannelHandlerContext ctx) throws Exception { for (int i = 1; i <= 5; i++) {String str = "msg No" + i;ByteBuf byteBuf = Unpooled.buffer(1024);byte[] bytes = str.getBytes(Charset.forName("utf-8"));//设置长度域的值 , 为有效数据的长度byteBuf.writeInt(bytes.length);//设置有效数据byteBuf.writeBytes(bytes);ctx.writeAndFlush(byteBuf);}}然后启动服务端 , 客户端 , 我们可以看到控制台打印结果: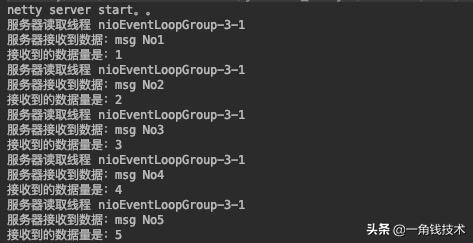 文章插图
文章插图可以看到 , 利用自定义长度帧解码器解决了粘包问题 。
使用Google Protobuf编解码器Netty官网上是明显写着支持Google Protobuf的 , 如下图所示:
 文章插图
文章插图Google Protobuf是什么官网的原话: Protocol buffers are Google's language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
翻译一下:Protocol buffers是Google公司的与语言无关、平台无关、可扩展的序列化数据的机制 , 类似XML , 但是更小、更快、更简单 。 您只需定义一次数据的结构化方式 , 然后就可以使用特殊生成的源代码 , 轻松地将结构化数据写入和读取到各种数据流中 , 并支持多种语言 。
在rpc或tcp通信等很多场景都可以使用 。 通俗来讲 , 如果客户端和服务端使用的是不同的语言 , 那么在服务端定义一个数据结构 , 通过protobuf转化为字节流 , 再传送到客户端解码 , 就可以得到对应的数据结构 。 这就是protobuf神奇的地方 。 并且 , 它的通信效率极高 , “一条消息数据 , 用protobuf序列化后的大小是json的10分之一 , xml格式的20分之一 , 是二进制序列化的10分之一” 。
Google Protobuf 官网 :
为什么使用Google Protobuf在一些场景下 , 数据需要在不同的平台 , 不同的程序中进行传输和使用 , 例如某个消息是用C++程序产生的 , 而另一个程序是用java写的 , 当前者产生一个消息数据时 , 需要在不同的语言编写的不同的程序中进行操作 , 如何将消息发送并在各个程序中使用呢?这就需要设计一种消息格式 , 常用的就有json和xml , protobuf出现的则较晚 。
Google Protobuf优点
- protobuf 的主要优点是简单 , 快;
- protobuf将数据序列化为二进制之后 , 占用的空间相当小 , 基本仅保留了数据部分 , 而xml和json会附带消息结构在数据中;
- protobuf使用起来很方便 , 只需要反序列化就可以了 , 而不需要xml和json那样层层解析 。
安装最新版本的protoc
- 从github上下载 protobuf3
Mac系统选择第一个 , 如下图所示:
 文章插图
文章插图