Lock、Synchronized锁区别解析( 三 )
1、 存活 , 判断该线程是否正在执行锁住的代码
1、 正在执行 , 升级为轻量级锁 , 然后执行轻量级锁的相关策略(为该线程的栈中开启一片区域来保存复制的 mark work 记作 lock record, 然后将锁对应的对象对象头的 mark word 部分的指针指向该线程 , 然后唤醒该线程继续执行 , 在此期间当前线程也会在栈中拷贝一份 mark word然后使用自旋锁+ CAS乐观锁尝试将该对象的 mark word 指针指向当前的 lock record, 执行完轻量级锁后 mark word 指针会删除 , 以便后面的线程重新指向)
2、 没有执行 。 检查是否开启重偏向 。
1、 开启了 , 先设置为匿名偏向状态 , 然后将 mark word 的 threadId 写入当前的线程 ID位置 , 然后再唤醒线程 , 继续执行
2、 没有开启 , 先撤销偏向锁 , 将 mark word 设置为无锁状态 , 然后升级轻量级锁 , 执行轻量级锁的执行策略
2、没有存活 , 检查是否开启重偏向 。
从上面的执行策略来看 , 偏向锁下是没有加锁、释放锁的操作的 , 这样就加快了对 某段一段时间内只有一个线程执行的代码 的执行效率 。 上面还提到自旋锁 , 乐观锁 。 这里是准备后面再开一篇多线程的博客专门来说这些 , 现在先简单说一下 。
自旋锁 :由于线程切换需要进行 "上下文切换" , 这个过程一次两次可能不算耗时 , 但是在多线程下 , 特别是在高并发场景下大量线程频繁地进行线程切换 , 就会出现大量的 "上下文切换" , 这中间消耗的时间是非常长的 , 所以对于这部分代码就使用 "自旋锁" , 它的特点是不会保存当前线程状态 , 也不会进入 "睡眠状态" , 而是一直尝试获取 CPU 调度 , 保持一种 "运行" 状态 , 这样就省去了 "上下文切换" 的时间 , 当然 , 这只适用于多核 CPU, 单核 CPU 是不能发挥 "自旋锁" 的作用的 , 因为它在一直尝试 , 这个尝试的过程也会占用 CPU。
乐观锁: 先保存一个参考数据 , 然后修改当前线程空间的变量 , 然后准备更新到主内存中去 , 在更新之前检查主内存对应的参考数据是否与之前保存的参考数据一致 , 如果一致更新到主内存 , 如果不一样那么此次更新作废 。
2、轻量级锁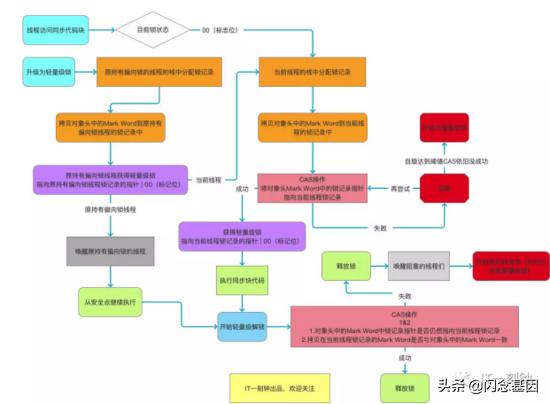 文章插图
文章插图
轻量级锁适用于线程数量少且执行时间短的代码块 。 在线程还未得到CPU调度时 , 首先会在该线程的栈中开启一块区域作为lock record , 然后将对象头的 Mark Word 部分拷贝到 lock record 位置 , 然后尝试将对象对象头 Mark Word 轻量级锁部分的指向栈的指针指向自己线程的lock record , 如果成功就表明该线程得到了锁 , CPU就会调度 。 详细的执行过程是:
1.如果这个对象锁是刚刚升级到轻量级锁且锁对应对象的mark word的偏向锁部分存储的 threadId 对应的线程没有执行完当前对应的代码 , 那么系统就会先将CPU交给 threadId 对应的线程 , 让他先执行完 。 过程就是先在该线程的栈中开启一块区域作为lock record , 然后将mark word拷贝到 lock record , 再将轻量级锁部分的指针指向 lock record 。 随后开始执行锁修饰的代码块 , 执行完毕后会进行两次检查:1.对象头的Mark Word中锁记录指针是否还是指向当前线程的lock record部分 2.lock record是否还与对象头的Mark Word一致 。 如果一致 , 就释放锁资源 。 如果不一致就将锁升级为重量级锁 , 然后释放 。
2.如果是普通的线程 , 那么首先还是在当前线程的栈中开启一块区域作为lock record , 然后将对象头的 Mark Word 部分拷贝到 lock record 位置 , 然后尝试将对象对象头 Mark Word 轻量级锁部分的指向栈的指针指向自己线程的lock record ,
1.如果成功 , 就继续执行后面代码 ,
2.如果失败就以自旋锁方式继续尝试 ,
1.如果一定次数还是没有获取到锁 , 那么就将锁膨胀为重量级锁 。
2.如果成功执行锁修饰的代码 , 执行完会再进行两个检查 , 如果符合就释放锁 。 不符合就膨胀成重量级锁 , 然后再释放 。
3、重量级锁重量级锁前面也说过了 , 就是一个线程在执行时 , 其他线程就先保存当前线程状态 , 然后进入 "休眠" 状态 , 乖乖等待CPU分配 , 得到CPU后才会读取上一次保存的状态 , 然后继续执行 。 它的执行逻辑还是先判断Mark Word部分的锁标志位 , 是10就说明是重量级锁 , 然后先来的尝试获取 , 得到CPU , 继续执行 , 后面的线程就需要等待进行一次上下文切换 。
总结:正是因为 synchronized 锁升级机制的存在 , 使得 synchronized 的效率不再那么低 。
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 占营收|华为值多少钱
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 操盘|中兴统一操盘中兴、努比亚、红魔三大品牌
- 印度|拒绝华为后,印度、英国斥资数十亿求助日本
- 华为|台积电、高通、华为、小米接连宣布!美科技界炸锅:怎么会这样!
- 拍照|iPhone12还没捂热13就曝光了,屏幕、信号、拍照均有升级!
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 一图看懂!数字日照、新型智慧城市这样建(上篇)|政策解读 | 新型