机器学习之Hyperparameter Tuning
机器学习时模型训练非常简单 , 将数据分成训练集(training set)和测试集(testing set) , 用training set训练模型 , 然后将模型应用到testing set上评估模型的好坏 。
怎么优化模型 , 使得模型更加稳定有效呢?
方法是超参数优化(Hyperparameter tuning) 。 比如我们有3个hyperparameter , 每个Hyperparameter可以设置3个数值 , 这样我们就可以得到3X3X3=27个组合 , 然后用相同的训练集分别训练27个模型 , 将这27个模型分别应用在testing set上 , 就可以比较出那组Hyperparameter组合比较好 。
但是 , 当我们把模型应用到真实场景的时候 , 往往会发现模型效果比在testing set上差很多 。 为什么会出现这样的问题呢?原因是我们调整参数的时候都是用的一套testing set , 所以我们选择的参数只是适应这个特殊的数据集 。 这时候validation set就该上场了!
这次数据就不能只分为训练集和测试集了 , 而是在训练集和测试集之外再分出验证集(validation set) 。 在Hyperparameter tuning时将训练的模型应用到validation set上挑选出最好的Hyperparameter 组合 , 然后将最好组合的模型应用到testing set上 , 得到模型的最终效果 。
【机器学习之Hyperparameter Tuning】这时候另外一个问题出现了 , 由于我们这次将模型应用在一个固定validation set上 , 而validation set 有可能太大或者太小 , 这次得到的模型很有可能不是模型的最优解 , 怎么办呢?我们可以用k fold cross validation来解决这个问题 。 如下图 , 首先将数据分为训练集和测试集 , 训练集再分为k份(例子中是5份) , 模型训练的时候用其中的k-1份作为训练集 , 用剩下的一份数据作为验证集 , 这样训练k个模型 , 将k次建模结果的平均数作为这个Hyperparameter组合的最终结果 , 这样得到模型的最优解 。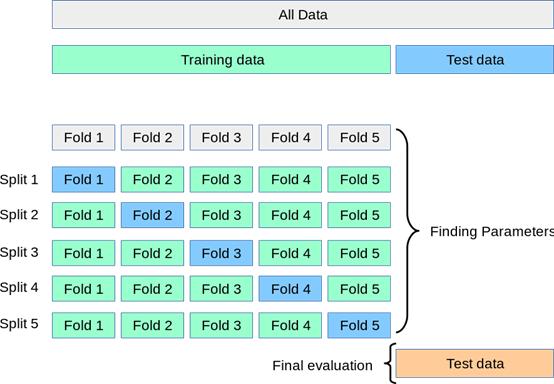 文章插图
文章插图
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 跑腿|机器人“小北”上岗 让办事群众少跑腿
- 计算机学科|机器视觉系统是什么
- 阿尔法|击败李世石的AI公司,又研发出生物版“阿尔法狗”:破解50年生物学难题
- 机器人|外骨骼康复训练机器人助力下肢运动功能障碍患者康复训练
- 互联网|政企学界人士西安共议数字经济 产业互联网发展向“西”行
- 高学历|薇娅一夜带货53.2亿,少不了这支高学历团队!
- 教学|机器人教学的目标方案
- 体验|VR\/AR体验、3D打印、机器人“对决”……松江这所中学人工智能创新实验室真的赞