AI|腾讯微视AI新技术曝光:斩获VCR榜单第一
杨净 萧箫 发自 凹非寺
近日,视觉常识推理任务VCR(Visual Commonsense Reasoning)榜单又被刷新了。
腾讯微视视频理解团队在多模态领域长期耕耘,此次以BLENDer单模型,夺得高分「81.6,86.4,70.8」,占领榜首。据团队介绍,BLENDer研发时间不到3个月。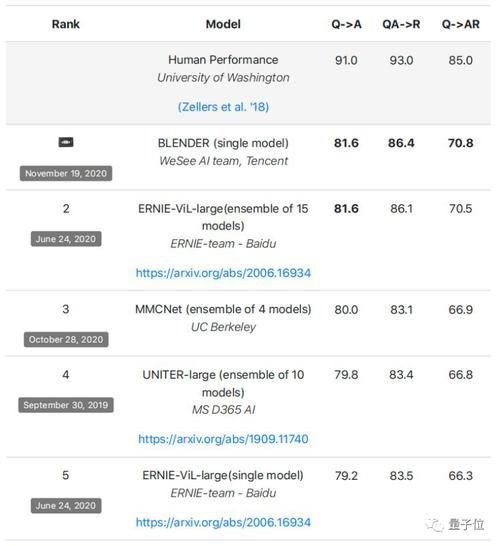
文章插图
百度微软曾称霸的VCR榜单被微视刷新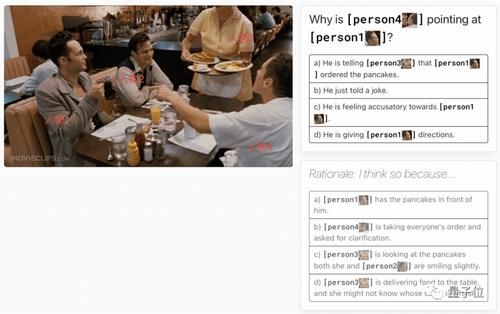
文章插图
【 AI|腾讯微视AI新技术曝光:斩获VCR榜单第一】这就要求机器同时理解图像中的视觉内容以及问题对应的文本内容。
目前,VCR榜单上的任务给出的场景图片有11万张,问题一共有29万个。而给出的问题,都需要对图片中的人物和场景进行一定程度的理解和推理,才能得到正确的答案。
正因如此,VCR任务对机器的多模态理解和推导能力提出了相当大的挑战,是当前图像理解和多模态领域层次最深、门槛最高的任务之一。
在此之前,包括谷歌、Facebook、微软、百度在内的很多企业和团队曾参与VCR竞赛,但以往最好效果都是基于多模型融合,包括百度(15个模型)、微软(10个模型)。腾讯微视的BLENDer单模型超越了此前榜单上的多模型提交结果,让这项技术有了更强的应用价值。
腾讯微视如何凭单模型霸榜?
团队参赛成员介绍到,BLENDer是在流行的视觉-语言Bert模型的基础上进行了改进。
文章插图
△BLENDer第一阶段算法模型
训练主要分为三个阶段:
- 以NLP BERT为起点,采用150万张图像+文本,采用词语/物体掩膜等技术,进行预训练,使模型能够学习到图像和文本两个模态的语义信息和关联。
- 在VCR数据集上进行类似第一阶段的预训练,使模型熟悉VCR的图像和语料,为第三阶段的特定任务训练做准备。
- 针对最终的视觉常识推理任务,进行微调训练。

文章插图
在模型训练的过程中,该团队也解决了很多难题。
例如,在第一和第二阶段的预训练,团队为每一个子任务设计了权重和训练参数能够自动调节的算法机制。让模型能够有效地从各个任务中学到有价值信息。
为了让模型能够更加有的放矢地训练,团队设计了更有针对性的文本和图像的掩膜技术,提升了重要词汇和物体的预测精度。
而只是预训练效果好,还不够。在最终的任务训练时,模型又出现了过拟合现象。为了解决过拟合的问题,团队用反向翻译技术对文本进行了扩增,还加入了对抗噪声进行训练。
腾讯微视团队还透露,目前团队还在对模型进行优化,也是为了日后更好地将模型应用到业务中。而BLENDer模型,还不是该团队的最优模型。
本次竞赛夺得榜首,得益于技术方案的创新、以及团队长期基于短视频业务场景所积累的海量跨模态数据。
微视语义理解团队输出的多项技术,已经应用在包括审核、推荐、多媒体信息挖掘等多个微视业务场景中,此次的BLENDer方案赋予了机器更强大的理解和认知能力,将进一步推动AI技术在短视频业务中智能交互场景的落地。
在更好地服务产品的同时,团队也计划向业界开源相关技术方案,助力多模态语义理解领域的技术研究和落地,进一步提高AI能力的通用性。
据了解,腾讯微视技术团队关于AI相关研究还有很多,也希望吸引更多技术精英人才加入。
—完—
量子位QbitAI · 头条号签约作者
?'?' ? 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~
- 世代|Z星球——腾讯布局Z世代教育社交的新尝试
- 中国视频|人日评论点赞!OPPO成视频手机先行者,新技术或下月发布
- 展开|天地在线联合腾讯广告在京展开“附近推” 构建黄金5公里营销体系
- 价值观|马化腾:正直是腾讯最基本的价值观
- 个性|腾讯QQ上线QID服务 自定义专属ID创造个性社交体验
- 研发|腾讯成立云计算西安分公司,将成总部之外最大云研发中心
- 全新|液体相机登场!华为P50采用新技术,摄像头模组大改
- 腾讯|酒水外卖平台“酒小二”获腾讯、红杉中国A轮融资
- 动作|OPPO 又有大动作,新技术与OPPO Star来临
- 上线|腾讯上线新功能:看看你的 QQ 值多少?