大数据入门—读取12.5亿行数据的简单代码
大数据意义 , 使用Python有效读取和可视化12.5亿行Galaxy模拟数据如今 , 我们正在进入许多时代 。有人说我们处于颠覆时代 。为了理解这一点 , 我们可以使用Schwartz(1999)在他的书《数字达尔文主义》中使用的术语 。该术语描述了我们正在进入一个企业无法适应技术和科学发展的时代 。数字平台和全球化改变了客户的范式并改变了他们的需求 。
另一方面 , 有人说我们正在进入大数据时代 。几乎所有学科都对数据蓬勃发展具有经验 。天文学就是其中之一 。世界各地的天文学家意识到 , 他们需要建造越来越大的望远镜或天文台 , 以在一个财团中收集更多数据 。例如 , 在2000年初 , 一项名为2 Micron All Sky Survey(2MASS)的全天空调查收集了大约4.7亿个对象 。2016年中 , 天文望远镜盖亚(Gaia)发布了第二次数据发布 , 其中包含约17亿个对象 。天文学家如何处理呢?
在本文中 , 我们将讨论如何实际处理大数据 。我们将使用来自盖亚宇宙模型快照(GUMS)的银河模拟数据 。它具有约35亿个对象 。您可以在这里访问它 。例如 , 我们将仅读取12.5亿行 。
用Vaex读取10亿行
首先 , 我必须感谢Maarten Breddels构建了Vaex , 这是一个用于读取和可视化大数据的python模块 。它可以在一秒钟内读取10亿行 。您可以在此处阅读文档 。
Vaex将有效地读取hdf5和arrow格式的文件 。在这里 , 我们将使用一些hdf5文件 。要在Vaex中读取文件 , 您可以使用以下代码
import vaex as vx
df = vx.open('filename.hdf5')
但是 , 如果您想同时读取一些hdf5文件 , 请使用此代码
df = vx.open_many(['file1.hdf5', 'file2.hdf5'])
您可以分析下图 。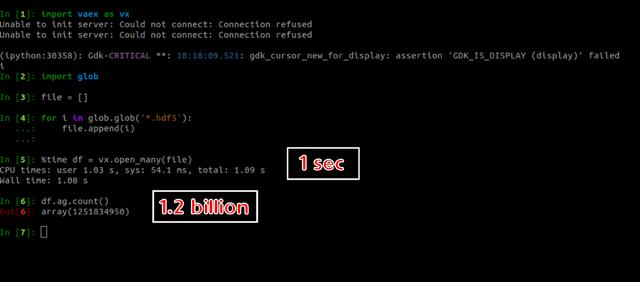 文章插图
文章插图
> Read 1.2 billion of rows (Image by author)
变量文件是工作目录中所有hdf5文件的数组 。您可以检查所需的时间以在1秒内读取所有文件 。在下一行中 , 我检查行的总数 。它是12.5亿行 。
Vaex中的算术运算和虚拟列
您还可以快速对所有行进行一些算术运算 。这是例子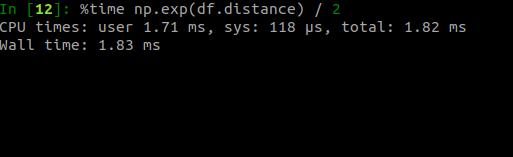 文章插图
文章插图
> Arithmetical operation in Vaex (Image by author)
Vaex可以以毫秒为单位执行算术运算 , 将其应用于所有行(12.5亿) 。如果要在Vaex数据框中分配列 , 则可以使用此代码
df['col_names'] = someoperations
这是例子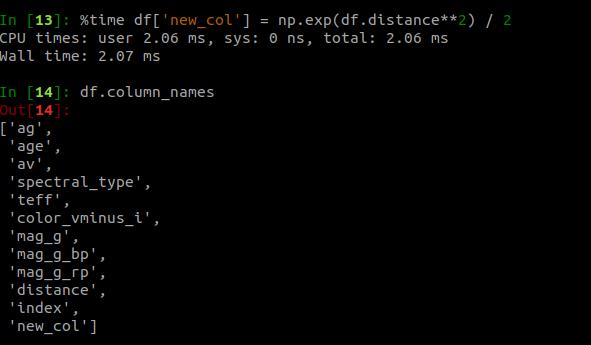 文章插图
文章插图
> Arithmetical operation in Vaex (Image by author)
如果仔细阅读 , 代码类似于Pandas API 。是的 , 据我所知 , Vaex正在与Pandas使用相同的API 。您也可以像在Pandas中一样选择列 , 例如此代码
df_selected = df[df.ag, df.age, df.distance]
返回上图 , 在第14行 , 添加了新列 , 名称为" new_col" 。 仅需2.07毫秒 。
一维和二维合并
您是否需要将装仓统计信息快速应用于大数据中? Vaex也将是答案 。要进行一维装仓和打印 , 可以使用以下代码
df.plot1d(x-axis, shape=(number_of_bin))
这是我们数据的例子 文章插图
文章插图
> 1D binning with Vaex (Image by author)
我们将一格数为25的一列距离绘制为一维(直方图) 。 它将产生一个这样的数字 。Vaex大约需要2秒钟才能可视化一维绘图 。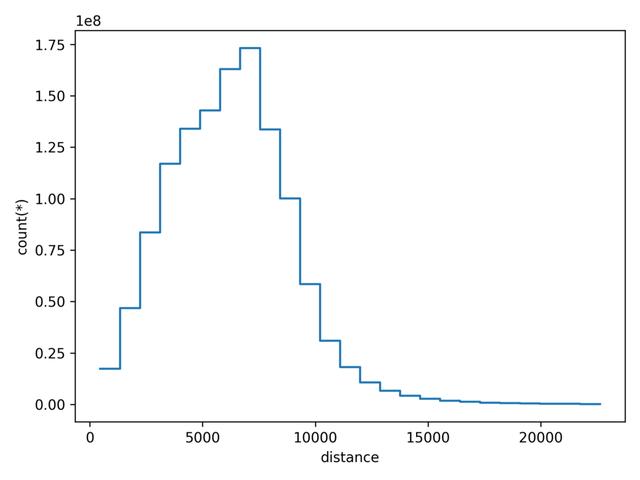 文章插图
文章插图
> 1D plot (histogram) in Vaex (Image by author)
要应用2D分箱和可视化 , 可以使用以下代码
df.plot(x-axis, y-axis, shape(shape_x, shape_y))
这是要在我们的数据中应用的示例 文章插图
文章插图
> 2D binning with Vaex (Image by author)
可视化2D图大约需要4分钟 。这是非常可以接受的 。您想象另一个模块以2D图的密度可视化12亿行需要多长时间 。它会给你这样的数字 。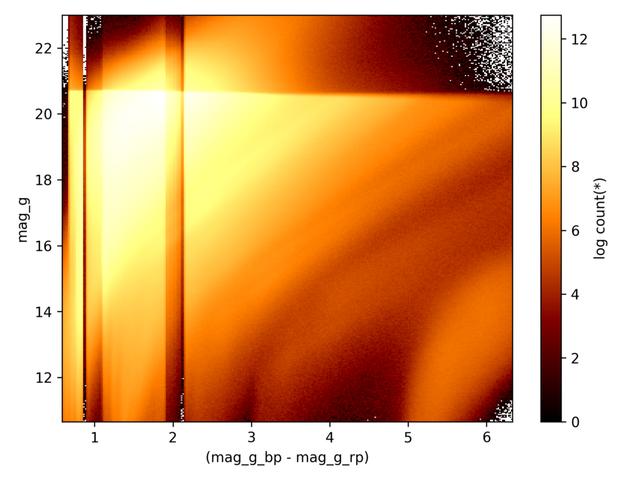 文章插图
文章插图
> 2D density plot in Vaex (Image by author)
结论未来就在这里 , 大数据时代已经来临 。我们必须准备所需的所有技术 。准备工作之一是建立一个Python库 , 该库可以有效地读取和可视化大数据 。Vaex即将为此提供解决方案 。它声称Vaex可以在一秒钟内读取10亿行 。
我希望您可以学习本故事中提到的示例并将其详细说明给您的数据 。就这样 。谢谢 。
参考文献:
[1] Schwartz , E 。 I. , 《数字达尔文主义》(1999) , 百老汇书刊
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 痛点|首个OTA智能社区诞生 解决行业四大痛点
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 长安|长安傍上华为这个大腿,市值暴涨500亿!可见华为影响力之大?
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰