如何优化 TensorFlow Lite 运行时内存?
由于资源有限 , 在移动和嵌入式设备上运行推理很有挑战性 。 人们必须在严格的能耗要求下使用有限的硬件 。 在本文中 , 我们希望展示 TensorFlow Lite(TFLite)内存使用方面的改进 , 这些改进使其更适合在边缘设备运行推理 。
中间张量通常情况下 , 神经网络可以被认为是计算图 , 由运算符(如CONV_2D或FULLY_CONNECTED)和包含中间计算结果的张量(称为中间张量)组成 。 这些中间张量通常是预先分配的 , 以减少推理等待时间 , 而代价是存储空间 。 然而 , 如果天真地实现了这个代价 , 那么在资源受限的环境中就不能掉以轻心:它可能会占用大量的空间 , 有时甚至比模型本身还要大好几倍 。 例如 , MobileNet V2 中的中间张量占用了 26MB 内存(见图 1) , 大约是模型本身的两倍 。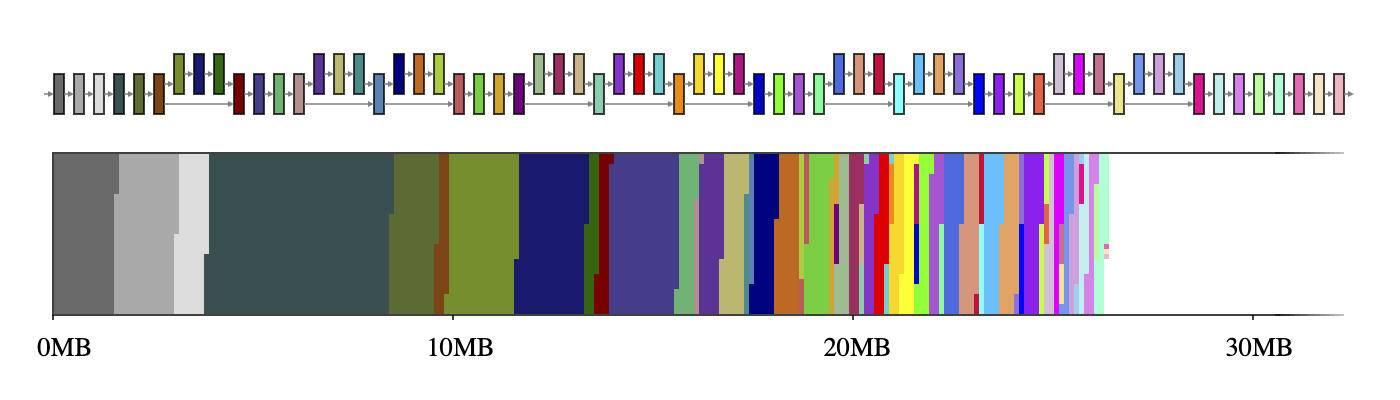 文章插图
文章插图
图 1
图 1:MobileNet V2 的中间张量(上)及其在 2D 存储空间(下)上的映射 。 如果每个中间张量使用专用的内存缓冲区(用 56 种不同的颜色表示) , 它们将占用约 26MB 的运行时内存
好消息是 , 由于数据相关性分析 , 这些中间张量不必在内存中共存 。 这允许我们可以重用中间张量的内存缓冲区 , 并减少推理机的总内存占用 。 如果网络具有简单链的形状 , 那么两个大的内存缓冲区就足够了 , 因为它们可以在整个网络中来回互换 。 然而 , 对于构成复杂图的任意网络 , 这种 NP 完全(NP-Complete , 缩写为 NP-C 或 NPC)资源分配问题需要一个良好的近似算法 。
我们为这个问题设计了许多不同的近似算法 , 它们的执行方式都取决于神经网络和内存缓冲区的属性 , 但它们都使用一个共同点:张量使用记录 。 一个中间张量的张量使用记录是一个辅助数据结构 , 它包含关于张量有多大 , 以及在网络的给定执行计划中第一次和最后一次使用的时间信息 。 在这些记录的帮助下 , 内存管理器能够在网络执行的任何时刻计算中间张量的使用 , 并优化其运行时内存以获得尽可能小的占用空间 。
共享内存缓冲区对象在 TFLite GPU OpenGL 后端 , 我们为这些中间张量采用 GL 纹理 。 这些都有一些有趣的限制:(a)纹理的大小在创建之后便无法修改 , 并且(b)在给定的时间只有一个着色器程序获得对纹理对象的独占访问权 。 在这种共享内存缓冲区对象模式中 , 目标是最小化对象池中所有创建的共享内存缓冲区对象的大小之和 。 这种优化类似于众所周知的寄存器分配问题 , 只不过由于每个对象的大小不同 , 这种优化要复杂得多 。
根据前面提到的张量使用记录 , 我们设计了 5 种不同的算法 , 如表 1 所示 。 除了最小成本流之外 , 它们都是贪心算法(Greedy algorithm) , 每种算法使用了不同的启发式算法 , 但仍然非常接近或接近理论下限 。 根据网络拓扑的不同 , 一些算法比其他算法执行得更好 , 但通常情况下 ,GREEDY_BY_SIZE_IMPROVED和GREEDY_BY_BREADTH产生的对象分配占用的内存最少 。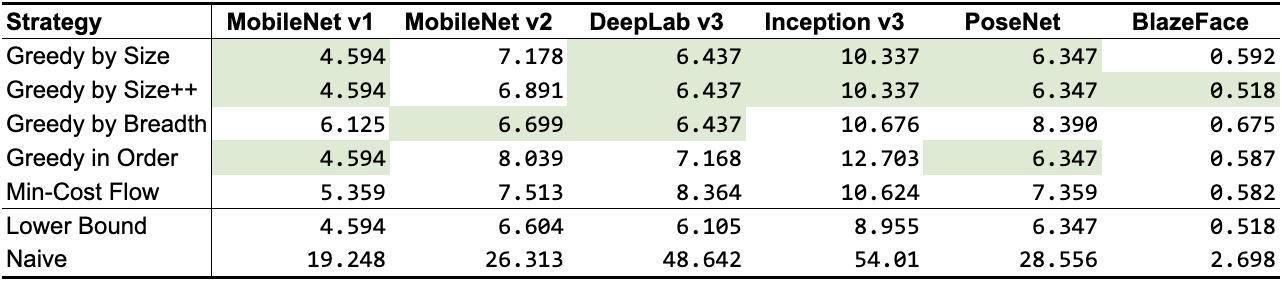 文章插图
文章插图
表 1
表 1:共享对象策略的内存占用(以 MB 为单位;最佳结果以绿色高亮显示) 。 前 5 行是我们的策略 , 后 2 行作为基线(下限表示可能无法实现的最佳数值的近似值 , Naive 表示每个中间张量分配自己的内存缓冲区时可能出现的最差数值)
回到前面的示例 , GREEDY_BY_BREADTH在 MobileNet V2 上执行得最好 , 它利用了每个运算符的宽度 , 即运算符配置文件中所有张量的总和 。 图 2 , 特别是与图 1 相比时 , 突出显示了使用智能内存管理器时 , 可以获得多大的收益 。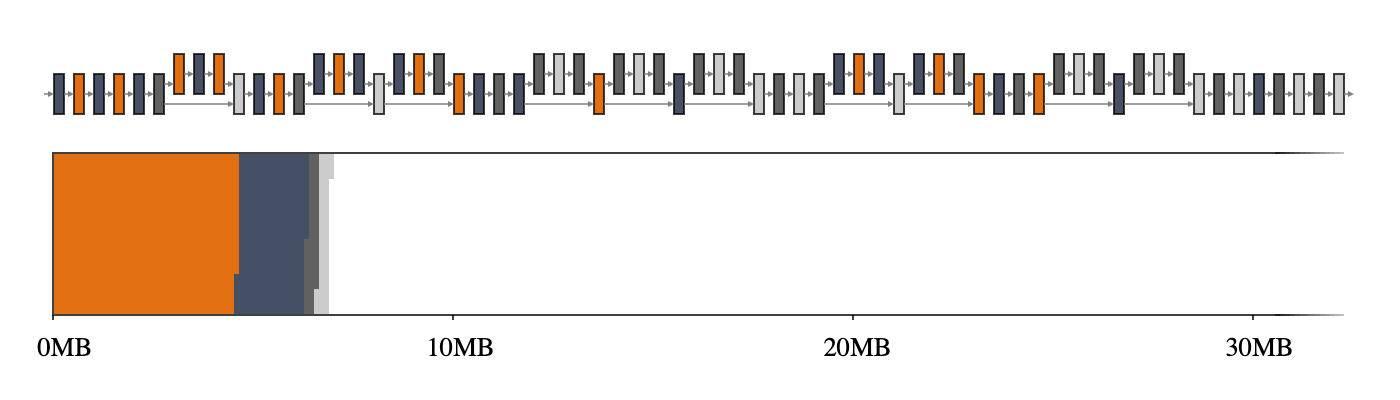 文章插图
文章插图
图 2
图 2:MobileNet V2 的中间张量(上)及其在 2D 存储空间(下)上的映射 。 如果中间张量共享内存缓冲区(用 4 种不同的颜色表示) , 它们只占用约 7MB 的运行时内存
内存偏移量计算对于在 CPU 上运行的 TFLite , 适用于 GL 纹理的内存缓冲区属性并不适用 。 因此 , 更常见的做法是预先分配一个巨大的内存空间 , 并让所有访问它的读取器和写入器共享它 , 这些读取器和写入器通过给定的偏移量访问它 , 而不会干扰其他读取和写入 。 这种内存偏移量计算方法的目标是最大程度地减少内存空间 。
我们已经为这个优化问题设计了 3 种不同的算法 , 并探索了先前的研究工作( Sekiyama 等人在 2018 年提出的 Strip Packing ) 。 与共享对象方法类似 , 有些算法的性能优于其他算法 , 具体取决于网络 , 如表 2 所示 。 从这个调查中我们可以看出 , 偏移量计算方法比一般的共享对象方法占用的空间更小 , 因此 , 如果可行的话 , 我们应该选择前者而非后者 。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!