如何实现 MySQL 删除重复记录并且只保留一条( 二 )
dt.minno FROM ( SELECT MIN(deptno) AS minno FROM dept GROUP BY dname ) dt )c. 补充第三种方法(评论区推荐的一种方法)DELETE FROM table_name AS ta WHERE ta.唯一键 <> (SELECT t.maxid FROM ( SELECT max( tb.唯一键 ) AS maxid FROM table_name AS tb WHERE ta.判断重复的列 = tb.判断重复的列 ) t );二、多个字段的操作单个字段的如果会了 , 多个字段也非常简单 。 就是将group by 的字段增加为你想要的即可 。
此处只写一个 , 其他方法请仿照一个字段的写即可 。
DELETEFROM deptWHERE (dname, db_source) IN ( SELECT t.dname, t.db_source FROM ( SELECT dname, db_source FROM dept GROUP BY dname, db_source HAVING count(1) > 1 ) t )AND deptno NOT IN ( SELECT dt.mindeptno FROM ( SELECT min(deptno) AS mindeptno FROM dept GROUP BY dname, db_source HAVING count(1) > 1 ) dt)总结其实上面的方法还有很多需要优化的地方 , 如果数据量太大的话 , 执行起来很慢 , 可以考虑加优化一下:
- 在经常查询的字段上加上索引
- 将*改为你需要查询出来的字段 , 不要全部查询出来
- 小表驱动大表用IN , 大表驱动小表用EXISTS 。 IN适合的情况是外表数据量小的情况 , 而不是外表数据大的情况 , 因为IN会遍历外表的全部数据 , 假设a表100条 , b表10000条那么遍历次数就是100*10000次 , 而exists则是执行100次去判断a表中的数据是否在b表中存在 , 它只执行了a.length次数 。 至于哪一个效率高是要看情况的 , 因为in是在内存中比较的 , 而exists则是进行数据库查询操作的
每天进步一点点
慢一点才能更快
第一本是程序员必知的硬核基础知识 , 这是一本非常入门的经典 PDF , 看完能让你对计算机有一个基础的了解和入门 , 是培养你
内核的基础 , 我们看下目录大纲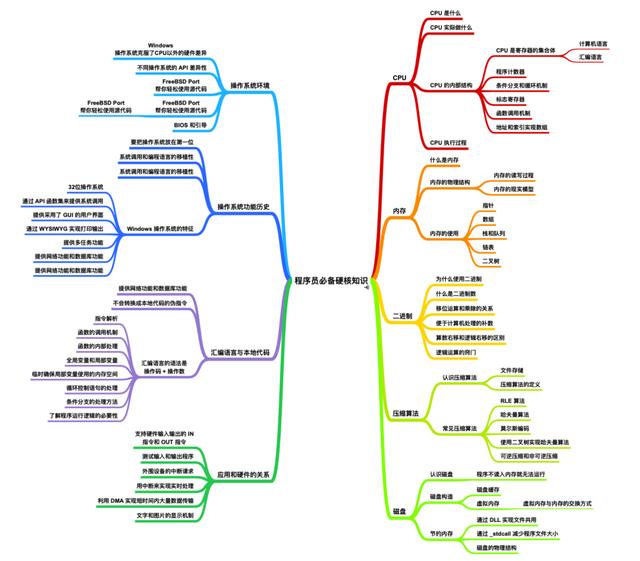 文章插图
文章插图【如何实现 MySQL 删除重复记录并且只保留一条】回复「os」 , 获取PDF
 文章插图
文章插图- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 与用户|掌握好这4个步骤,实现了规模性的盈利
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!