啊哈,原来如此!4种流行的机器学习算法的顿悟时刻
 文章插图
文章插图
> Source: Pixabay
直观地知道为什么 , 而不仅仅是知道【啊哈,原来如此!4种流行的机器学习算法的顿悟时刻】大多数人都在两个营地中:
· 我不了解这些机器学习算法 。
· 我了解算法的工作原理 , 但不了解其工作原理 。
本文不仅试图解释算法的工作原理 , 而且要直观地理解算法的工作原理 , 以提供这种灯泡啊哈! 时刻 。
决策树决策树使用水平线和垂直线划分要素空间 。例如 , 考虑下面一个非常简单的决策树 , 该决策树具有一个条件节点和两个类节点 , 指示一个条件以及满足该条件的训练点将属于哪个类别 。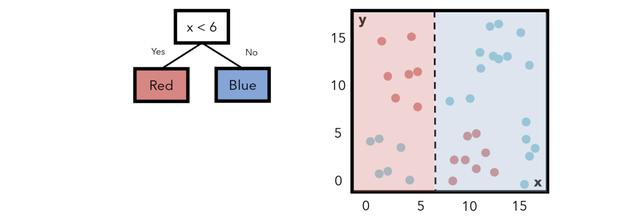 文章插图
文章插图
请注意 , 标记为每种颜色的字段与该区域内实际上是该颜色或(大致)熵的数据点之间存在很多重叠 。构造决策树以最小化熵 。在这种情况下 , 我们可以增加一层复杂性 。如果要添加另一个条件; 如果x小于6 , y大于6 , 我们可以将该区域中的点指定为红色 。此举降低了熵 。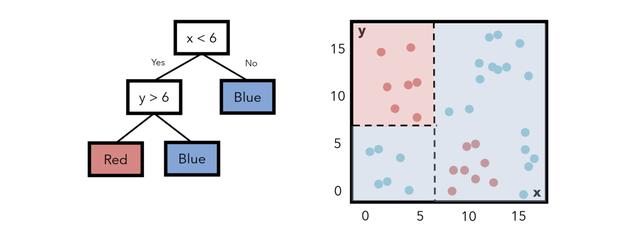 文章插图
文章插图
在每个步骤中 , 决策树算法都会尝试找到一种构建树的方法 , 以使熵最小化 。将熵更正式地看作是某个分隔线(条件)所具有的"混乱"或"混乱" , 而与"信息增益"相反的是 , 分隔线为模型增加了多少信息和洞察力 。具有最高信息增益(以及最低熵)的要素拆分位于顶部 。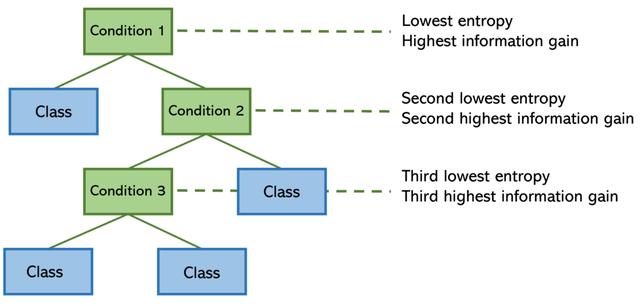 文章插图
文章插图
条件可能会将其一维特征分解为如下形式: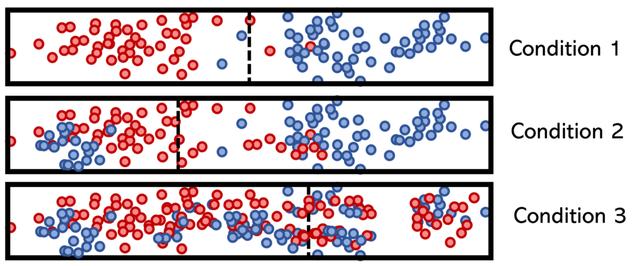 文章插图
文章插图
请注意 , 条件1具有清晰的分隔 , 因此熵低且信息增益高 。条件3不能说相同 , 这就是为什么它位于决策树底部附近的原因 。树的这种构造确保其可以保持尽可能轻巧 。
您可以在此处阅读有关熵及其在决策树以及神经网络(交叉熵作为损失函数)中的用法的更多信息 。
随机森林随机森林是决策树的袋装(引导聚合)版本 。主要思想是对数个决策树分别训练一个数据子集 。然后 , 输入通过每个模型 , 并且它们的输出通过类似平均值的函数进行汇总以产生最终输出 。套袋是组合学习的一种形式 。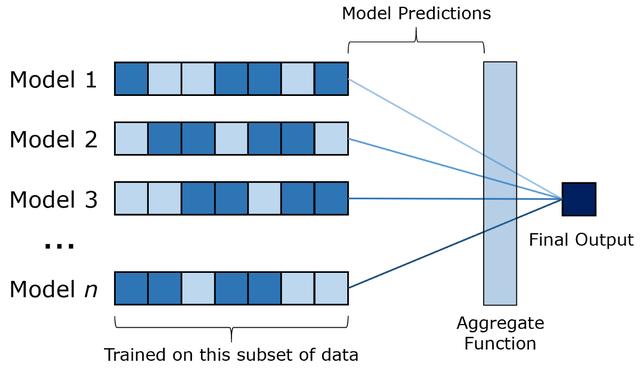 文章插图
文章插图
您需要确定下一家餐厅 。要向某人提出建议 , 您必须回答各种是/否问题 , 这将使他们做出您应该去哪家餐厅的决定 。
您愿意只问一个朋友还是问几个朋友 , 然后找到方式或普遍共识?
除非您只有一个朋友 , 否则大多数人都会回答第二个 。该类比提供的见解是 , 每棵树都有某种"思维多样性" , 因为它们是在不同的数据上训练的 , 因此具有不同的"体验" 。
这种类比 , 干净和简单 , 从来没有真正让我脱颖而出 。在现实世界中 , 单朋友选项的经验少于所有朋友 , 但在机器学习中 , 决策树和随机森林模型是在相同的数据上训练的 , 因此也具有相同的体验 。集成模型实际上没有接收任何新信息 。如果我可以向一个全知的朋友提出建议 , 我不会反对 。
在相同数据上训练的模型如何随机抽取数据子集以模拟人为的"多样性" , 其效果如何比在整个数据上训练的模型更好?
拍摄正弦波 , 并带有大量正态分布的噪声 。这是您的单个决策树分类器 , 它自然是一个高方差模型 。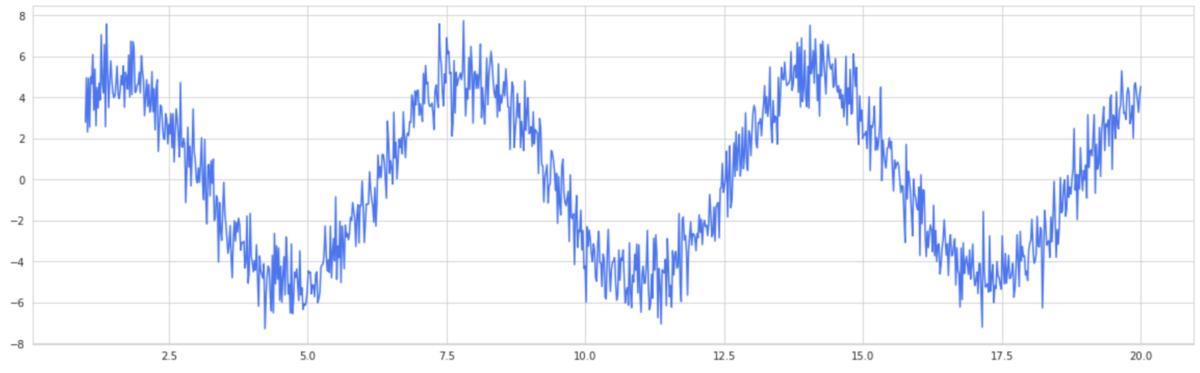 文章插图
文章插图
将选择100个"近似值" 。这些逼近器沿正弦波随机选择点并生成正弦曲线拟合 , 就像在数据子集上训练决策树一样 。然后将这些拟合平均 , 以形成袋装曲线 。结果? -更平滑的曲线 。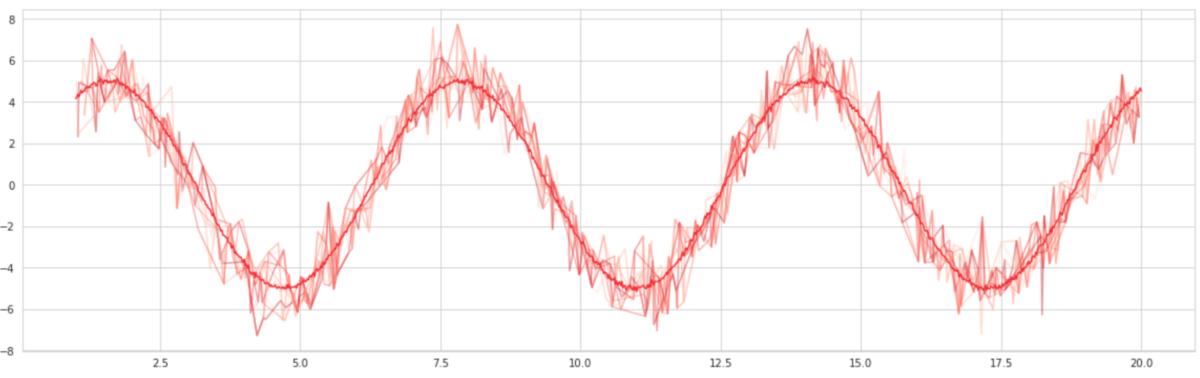 文章插图
文章插图
套袋有效的原因在于 , 它通过人为地使模型更具"信心" , 从而减少了模型的差异并有助于提高泛化能力 。这也就是为什么装袋在诸如Logistic回归之类的低方差模型中效果不佳的原因 。
您可以在这里阅读更多关于直觉的信息 , 以及关于套袋成功的更严格的证明 。
支持向量机支持向量机依靠"支持向量"的概念来最大化两个类别之间的距离 , 试图找到一种可以最好地划分数据的超平面 。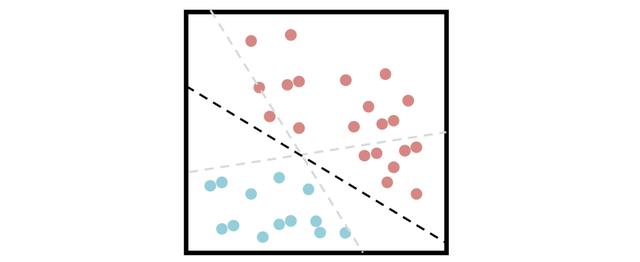 文章插图
文章插图
- 症状|专家提醒:手机出现4种症状,你可能正在被“监听”,要赶快自查
- 号码|手机能被“监控”吗?如果手机频繁出现这4种情况,你就要当心了
- 智能手机|专家提醒:手机出现4种症状,你可能正在被“监听”,要赶快自查
- 马云“预言”成真?未来10年,这4种职业或被淘汰,有你吗?
- 马化腾不再手软,微信这4种行为要注意,严重的直接封号
- 以防|马化腾下定决心,微信上4种行为零容忍,告诉家人以防封号
- 马云没有说谎,5年后,这4种职业将慢慢淘汰,大批人丢掉工作?
- 好消息!5G原来如此重要,中国移动立功
- 为了写这篇推文,我用Google翻译了24种语言
- 姑息|马化腾正式确认了!对于微信这4种行为不再姑息,必要时直接封号