Pytho爬虫项目实战:采集B站《全职高手》20万条评论数据
我们都知道 , B站有很多号称“镇站之宝”的视频 , 拥有着数量极其恐怖的评论和弹幕 。 所以这次我们的目标就是 , 爬取B站视频的评论数据 , 分析其为何会深受大家喜爱 。
私信小编01即可获取大量Python学习资料
首先去调研一下 , B站评论数量最多的视频是哪一个 。。。 好在已经有大佬已经统计过了 , 我们来看一哈!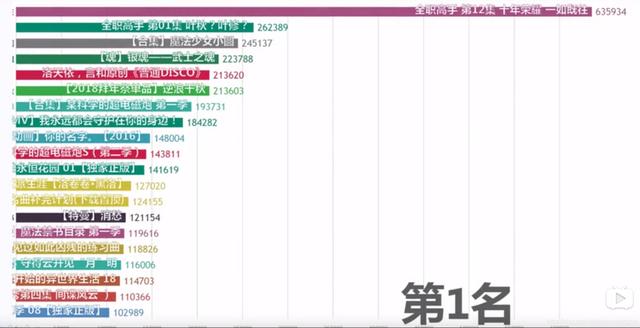 文章插图
文章插图
嗯?《全职高手》 , 有点意思 , 第一集和最后一集分别占据了评论数量排行榜的第二名和第一名 , 远超了其他很多很火的番 。 那好 , 就拿它下手吧 , 看看它到底强在哪儿 。
废话不多说 , 先去B站看看这部神剧到底有多好看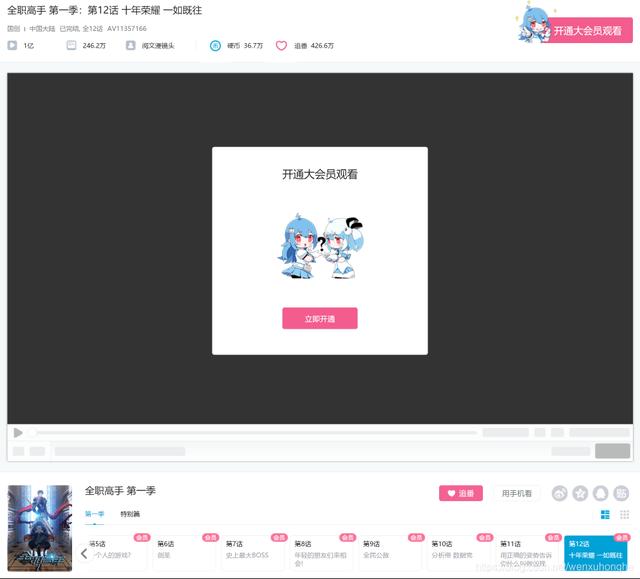 文章插图
文章插图
【Pytho爬虫项目实战:采集B站《全职高手》20万条评论数据】额 , 需要开通大会员才能观看 。。。
好吧 , 不看就不看 , 不过好在虽然视频看不了 , 评论却是可以看的 。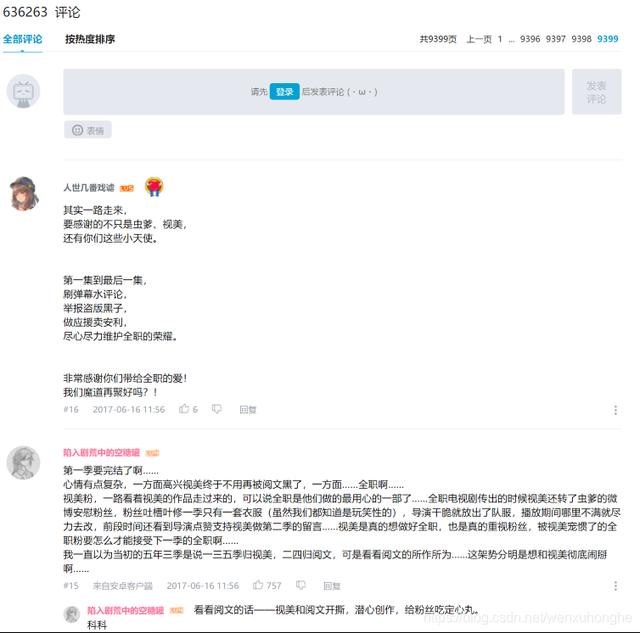 文章插图
文章插图
感受到它的恐怖了吗?63w6条的评论!9千多页!果然是不同凡响啊 。
接下来 , 我们就开始编写爬虫 , 爬取这些数据吧 。
使用爬虫爬取网页一般分为四个阶段:分析目标网页 , 获取网页内容 , 提取关键信息 , 输出保存 。
1. 分析目标网页
- 首先观察评论区结构 , 发现评论区为鼠标点击翻页形式 , 共 9399 页 , 每一页有 20 条评论 , 每条评论中包含 用户名、评论内容、评论楼层、时间日期、点赞数等信息展示 。
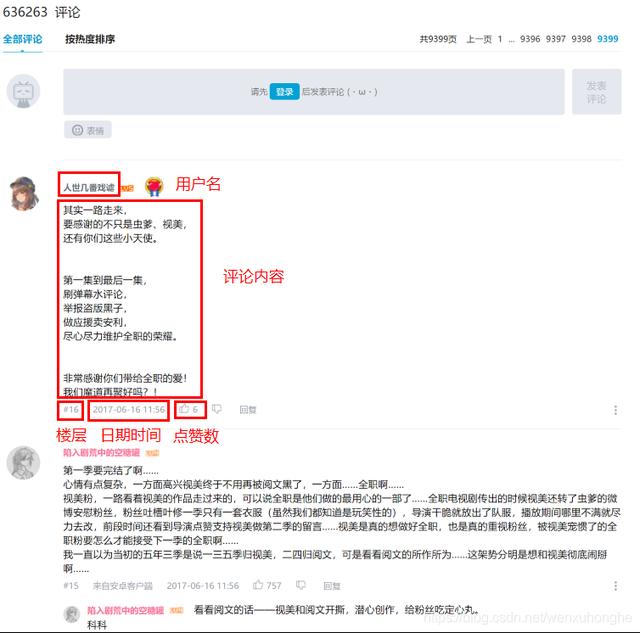 文章插图
文章插图- 接着我们按 F12 召唤出开发者工具 , 切换到Network 。 然后用鼠标点击评论翻页 , 观察这个过程有什么变化 , 并以此来制定我们的爬取策略 。
- 我们不难发现 , 整个过程中 URL 不变 , 说明评论区翻页不是通过 URL 控制 。 而在每翻一页的时候 , 网页会向服务器发出这样的请求(请看 Request URL) 。
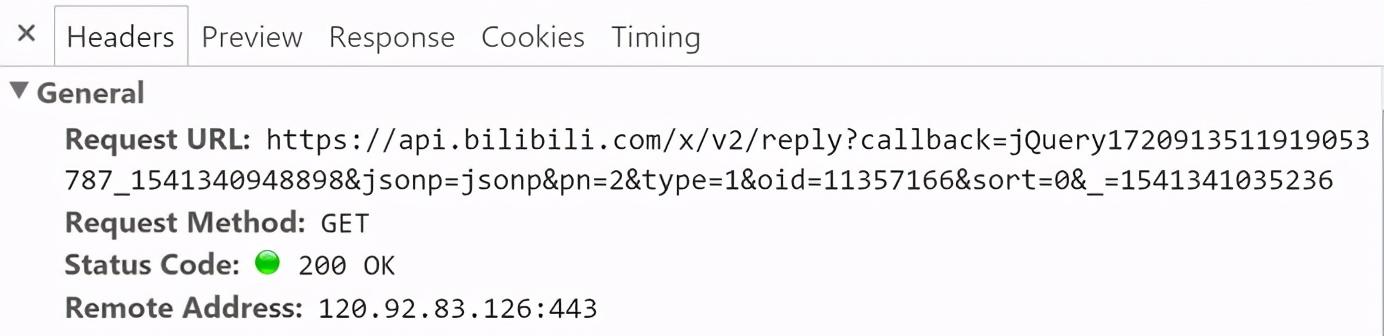 文章插图
文章插图- 点击 Preview 栏 , 可以切换到预览页面 , 也就是说 , 可以看到这个请求返回的结果是什么 。 下面是该请求返回的 json 文件 , 包含了在 replies 里包含了本页的评论数据 。 在这个 json 文件里 , 我们可以发现 , 这里面包含了太多的信息 , 除了网页上展示的信息 , 还有很多没展示出来的信息也有 , 简直是挖到宝了 。 不过 , 我们这里用不到 , 通通忽略掉 , 只挑我们关注的部分就好了 。
 文章插图
文章插图2. 获取网页内容
网页内容分析完毕 , 可以正式写代码爬了 。
import requests def fetchURL(url):'''功能:访问 url 的网页 , 获取网页内容并返回参数:url :目标网页的 url返回:目标网页的 html 内容'''headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',}try:r = requests.get(url,headers=headers)r.raise_for_status()print(r.url)return r.textexcept requests.HTTPError as e:print(e)print("HTTPError")except requests.RequestException as e:print(e)except:print("Unknown Error !")if __name__ == '__main__':url = ';jsonp=jsonp --tt-darkmode-color: #999999;">不过 , 在运行过后 , 你会发现 , 403 错误 , 服务器拒绝了我们的访问 。
运行结果: 403 Client Error: Forbidden for url: ;jsonp=jsonp --tt-darkmode-color: #999999;">同样的 , 这个请求放浏览器地址栏里面直接打开 , 会变403 , 什么也访问不到 。
 文章插图
文章插图
这是我们本次爬虫遇到的第一个坑 。 在浏览器中能正常返回响应 , 但是直接打开请求链接时 , 却会被服务器拒绝 。 (我第一反应是 cookie, 将浏览器中的 cookie 放入爬虫的请求头中 , 重新访问 , 发现没用) , 或许这也算是一个小的反爬虫机制吧 。
网上查阅资料之后 , 我找到了解决的方法(虽然不了解原理) , 原请求的 URL 参数如下:
callback = jQuery1720913511919053787_1541340948898jsonp = jsonppn = 2type = 1oid = 11357166 --tt-darkmode-color: #999999;">其中 , 真正有用的参数只有三个:pn(页数) , type(=1)和oid(视频id) 。 删除其余不必要的参数之后 , 用新整理出的url去访问 , 成功获取到评论数据 。
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收