稳定性平台的设计与实现
作者:颜发明
出处:
微服务架构中 , 服务数量大大增加 , 调用关系变得复杂 。 用户的一个请求 , 会放大为内部服务间的若干次调用 , 依赖实际上变多了 。 而一个服务的故障 , 沿着调用链传播 , 也可能造成难以预料的影响 。 更糟糕的是 , 在服务数量很多的时候 , 故障是无可避免的 。 不论单个服务可用性达到几个 9 , 在服务数量 N 很大时 , 它的乘方一定会离 0 越来越近 。 在这种现状下 , 增强整体容错性就成为一项重要的工作 。
一方面当下游服务挂掉时 , 上游服务作为调用方 , 需要有一定容错能力 , 设置一些兜底逻辑 , 尽量避免直接随之也挂掉 。 同时 , 也应避免无脑多次重试 , 降低下游服务的负载 , 使其有恢复的机会 。
另一方面 , 作为服务本身 , 其资源是有限的 , 服务能力也是有上限的 。 对于超出上限的流量 , 只能忍痛丢弃 。 毕竟只服务部分请求 , 总比接收所有请求然后拖死整个系统要好得多
这两方面的考量 , 正是我们稳定性平台的主题:熔断与限流 。 网络上流传着一句话 , 熔断、限流、降级是分布式架构的三板斧 , 可见其重要性 。
熔断, Circuit breaker , 也叫断路器 。 这是借用自电路的说法 , 其实就是保险丝的升级版 。 保险丝烧断后只能更换 , 而断路器断开后不用换 , 可以手动复位 。 熔断器用于软件系统 , 最早可能是在 Release It!: Design and Deploy Production-Ready Software 这本书中提出的 。 「重构」的作者 Martin Fowler 写文章介绍过这个概念 , 见 CircuitBreaker, 并被 Netflix 的 Hystrix 项目发扬光大 。
熔断器核心逻辑 , 可表示为一个简单的状态机: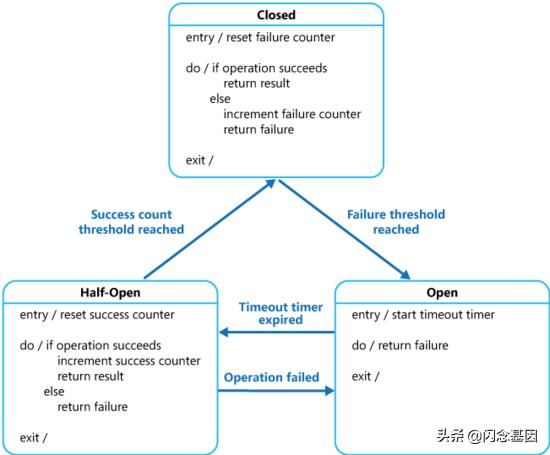 文章插图
文章插图
简单地说 , 当达到失败阈值后 , 熔断器将从 closed 状态进入 open 状态 。 open 即断开 , 所有请求都不允许通过 , 直接返回错误(这正是兜底逻辑的接入点) 。 进入 open 状态一段时间后 , 自动进入 half_open 状态 , 此时会允许少量请求通过 , 如果返回成功的数量超过一定阈值则进入 closed 状态 , 否则返回 open 状态 。
熔断器是由调用方使用的 。 从调用者角度看 , 可通过熔断器插入兜底逻辑 , 以减轻下游服务故障的影响 。 从被调用者角度看 , 被调用服务故障时 , 熔断断开 , 调用暂停 , 这对于过载恢复意义重大 。 而从整体上看 , 调用链上处处使用熔断器 , 可以阻断故障沿着调用链向上传播(此即级联失败, cascading failure) , 保证了系统整体的稳定性 。 另外 , 熔断器自动在 open - half_open - closed 的状态迁移 , 也可减少故障过程中的人工介入 。
限流的概念相对简单 , 计算 QPS 并据此决策即可 。 这里其实存在着两类场景 , 根据限流器使用的位置 , 是流量的「发起方」还是「接收方」 , 处理逻辑有所不同 。 对于微服务场景来说 , 是将限流器用在 server 端 , 以对调用方限速 , 这是所谓「流量的接收方」 , 超出阈值后通常直接丢弃即可 , 我们称之为「否决式限流」 。 而像消费 MQ 消息时 , 或者发送 Push 时 , 为避免打挂所依赖的下游服务 , 而对自身消费/发送 Push 的行为进行限速 , 这就是所谓「流量的发起方」 , 此时如果超出阈值我们一般选择等待 , 即阻塞在对限流器的调用上 , 只有从调用中返回时 , 我们才会继续执行动作 , 我们称之为「阻塞式限流」 。 而实现上 , 常见限流算法有滑动窗口、令牌桶、漏桶等供我们选择 。
稳定性平台:需求与设计首先 , 我们希望与服务框架深度整合 。 熔断方面 , 要支持对调用的每一个接口设置熔断阈值 。 限流方面 , 要支持按接口对不同调用方设置不同的限流阈值 。 而对于非接口的熔断限流也要加以支持 , 特别地 , 对于非接口的限流需要同时支持否决式限流和阻塞式限流 。 我们的现状是 , 服务治理平台已经解析了所有服务的 IDL 并提供了接口 , 因此很方便地就能获取服务的接口信息 。 而对于按调用方限流 , 现实就没那么美好了 , 被调用方暂时无法拿到调用方的服务标识 。 经过调研发现 , 可以通过 opentracing 的 baggage 机制 , 来支持这一特性 。 但这涉及我们服务框架和基础库的一些改造工作 , 因此「按调用方限流」的功能 , 只好放到二期再支持了 。
其次 , 未来熔断限流功能可能会整合到其他中间件中 , 因此除了管理后台之外 , 还需要提供单独的 SDK 。
第三 , 微服务一般是集群部署的 , 谈论服务能力时 , 我们也常默认其为集群的服务能力 。 如果我们提供集群级别的限流能力 , 则与此视角保持一致 , 而且使用者可无视服务扩容缩容的影响 , 体验将会更好 。 但是考虑到集群级别限流有额外的实现复杂度及开销 , 比如 , 需要外部存储保存状态并同步多个节点对状态的读写以保持数据一致性 , 又比如读写外部存储的网络开销 , 可能导致限流器本身的延迟将达到 ms 级别(而访问内存的开销可忽略不计) , 我们最终决定暂时只提供单节点级别的限流 。 另外 , 我们也调研过 Sentinel 的集群限流方案 , 其 token server 与一个服务无甚区别 。 而我们认为 , SDK 应是一个 library , 是「无我」的 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 信息|澜湄合作机制开通水资源合作信息共享平台
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生